 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMF-QAT: Multi-Format Quantization-Aware Training for Elastic Inference
Apr 01, 2026Quantization-aware training (QAT) is typically performed for a single target numeric format, while practical deployments often need to choose numerical precision at inference time based on hardware support or runtime constraints. We study multi-format QAT, where a single model is trained to be robust across multiple quantization formats. We find that multi-format QAT can match single-format QAT at each target precision, yielding one model that performs well overall across different formats, even formats that were not seen during training. To enable practical deployment, we propose the Slice-and-Scale conversion procedure for both MXINT and MXFP that converts a high-precision representation into lower-precision formats without re-training. Building on this, we introduce a pipeline that (i) trains a model with multi-format QAT, (ii) stores a single anchor format checkpoint (MXINT8/MXFP8), and (iii) allows on-the-fly conversion to lower MXINT or MXFP formats at runtime with negligible-or no-additional accuracy degradation. Together, these components provide a practical path to elastic precision scaling and allow selecting the runtime format at inference time across diverse deployment targets.
CRoPE: Efficient Parametrization of Rotary Positional Embedding
Jan 06, 2026Rotary positional embedding has become the state-of-the-art approach to encode position information in transformer-based models. While it is often succinctly expressed in complex linear algebra, we note that the actual implementation of $Q/K/V$-projections is not equivalent to a complex linear transformation. We argue that complex linear transformation is a more natural parametrization and saves near 50\% parameters within the attention block. We show empirically that removing such redundancy has negligible impact on the model performance both in sample and out of sample. Our modification achieves more efficient parameter usage, as well as a cleaner interpretation of the representation space.
The Impact of Quantization on Large Reasoning Model Reinforcement Learning
Nov 19, 2025Strong reasoning capabilities can now be achieved by large-scale reinforcement learning (RL) without any supervised fine-tuning. Although post-training quantization (PTQ) and quantization-aware training (QAT) are well studied in the context of fine-tuning, how quantization impacts RL in large reasoning models (LRMs) remains an open question. To answer this question, we conducted systematic experiments and discovered a significant gap in reasoning performance on mathematical benchmarks between post-RL quantized models and their quantization-aware RL optimized counterparts. Our findings suggest that quantization-aware RL training negatively impacted the learning process, whereas PTQ and QLoRA led to greater performance.
Understanding the difficulty of low-precision post-training quantization of large language models
Oct 18, 2024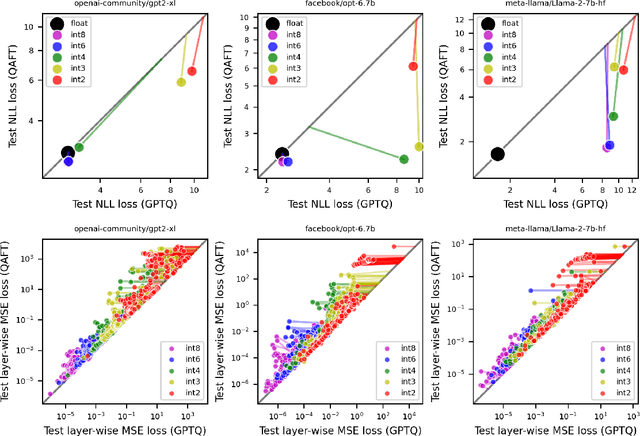
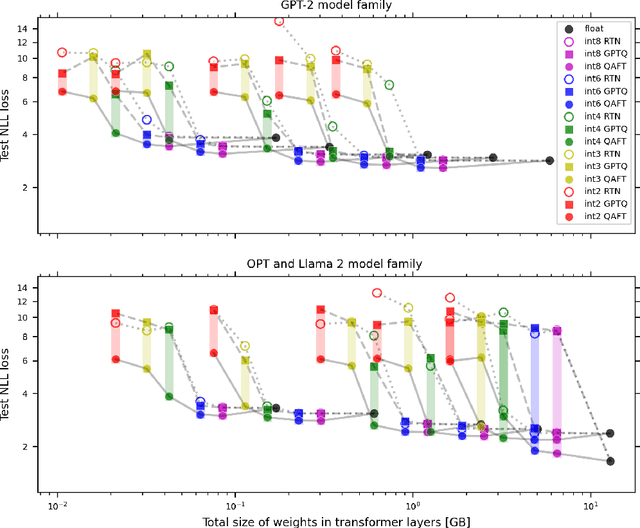
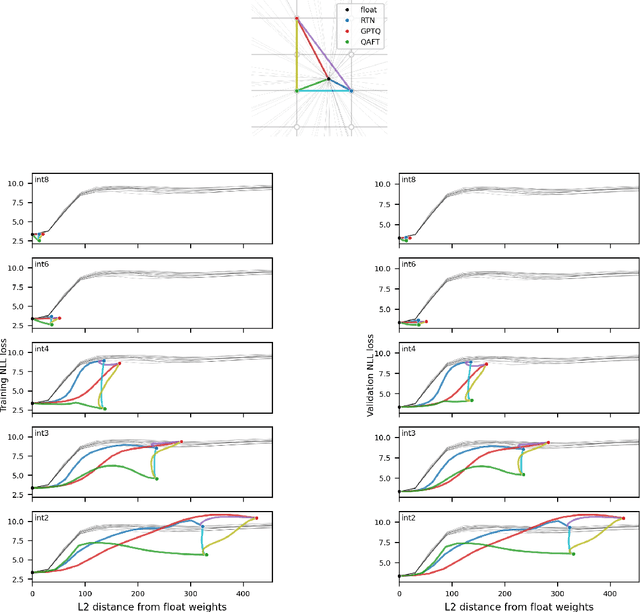
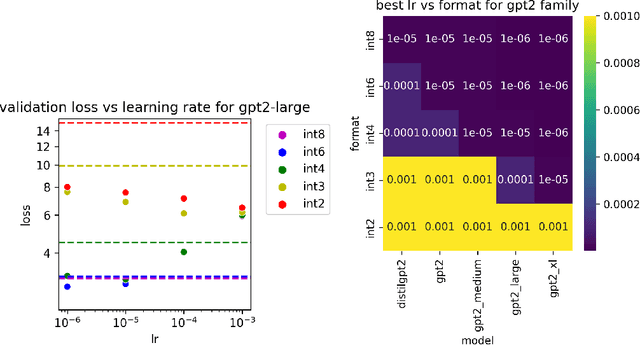
Large language models of high parameter counts are computationally expensive, yet can be made much more efficient by compressing their weights to very low numerical precision. This can be achieved either through post-training quantization by minimizing local, layer-wise quantization errors, or through quantization-aware fine-tuning by minimizing the global loss function. In this study, we discovered that, under the same data constraint, the former approach nearly always fared worse than the latter, a phenomenon particularly prominent when the numerical precision is very low. We further showed that this difficulty of post-training quantization arose from stark misalignment between optimization of the local and global objective functions. Our findings explains limited utility in minimization of local quantization error and the importance of direct quantization-aware fine-tuning, in the regime of large models at very low precision.
Scaling laws for post-training quantized large language models
Oct 15, 2024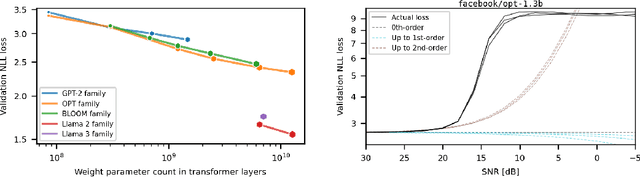
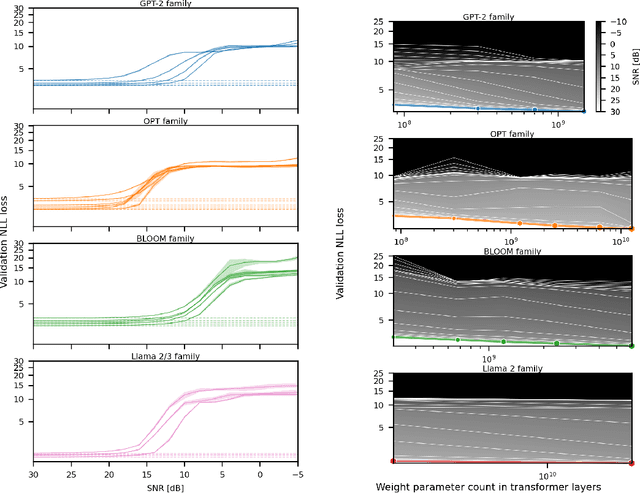
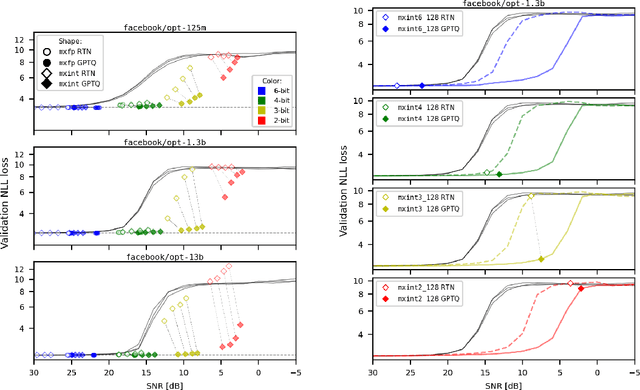
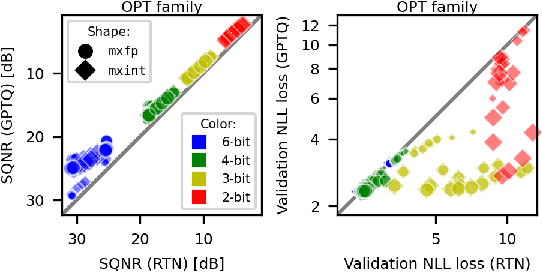
Generalization abilities of well-trained large language models (LLMs) are known to scale predictably as a function of model size. In contrast to the existence of practical scaling laws governing pre-training, the quality of LLMs after post-training compression remains highly unpredictable, often requiring case-by-case validation in practice. In this work, we attempted to close this gap for post-training weight quantization of LLMs by conducting a systematic empirical study on multiple LLM families quantized to numerous low-precision tensor data types using popular weight quantization techniques. We identified key scaling factors pertaining to characteristics of the local loss landscape, based on which the performance of quantized LLMs can be reasonably well predicted by a statistical model.
Combining multiple post-training techniques to achieve most efficient quantized LLMs
May 12, 2024Large Language Models (LLMs) have distinguished themselves with outstanding performance in complex language modeling tasks, yet they come with significant computational and storage challenges. This paper explores the potential of quantization to mitigate these challenges. We systematically study the combined application of two well-known post-training techniques, SmoothQuant and GPTQ, and provide a comprehensive analysis of their interactions and implications for advancing LLM quantization. We enhance the versatility of both techniques by enabling quantization to microscaling (MX) formats, expanding their applicability beyond their initial fixed-point format targets. We show that by applying GPTQ and SmoothQuant, and employing MX formats for quantizing models, we can achieve a significant reduction in the size of OPT models by up to 4x and LLaMA models by up to 3x with a negligible perplexity increase of 1-3%.
Self-Selected Attention Span for Accelerating Large Language Model Inference
Apr 14, 2024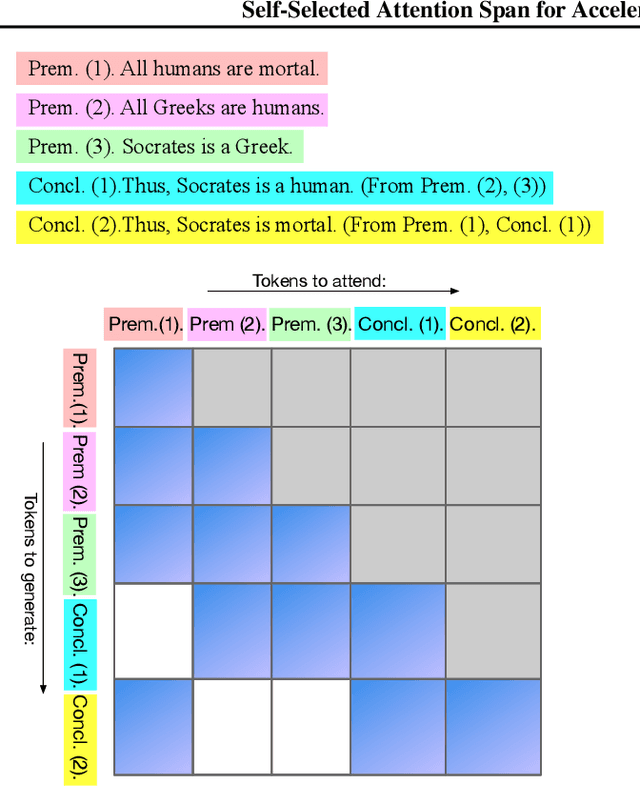
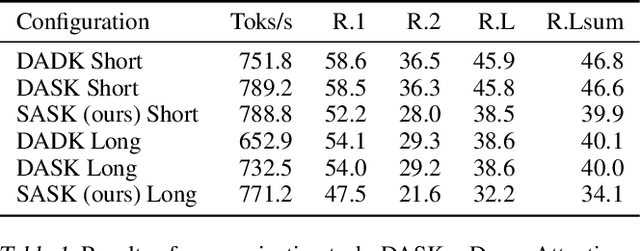
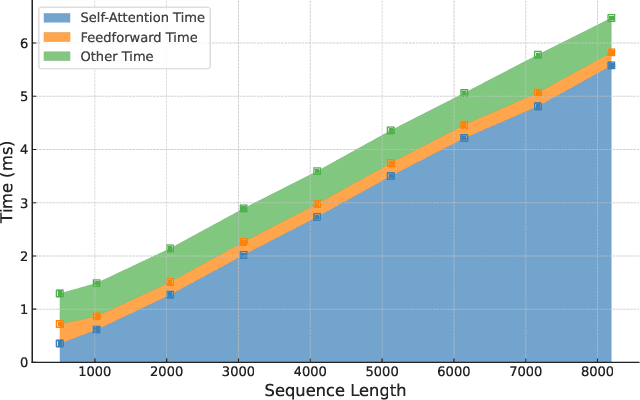
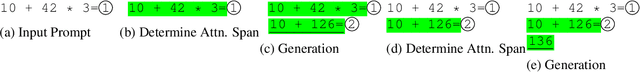
Large language models (LLMs) can solve challenging tasks. However, their inference computation on modern GPUs is highly inefficient due to the increasing number of tokens they must attend to as they generate new ones. To address this inefficiency, we capitalize on LLMs' problem-solving capabilities to optimize their own inference-time efficiency. We demonstrate with two specific tasks: (a) evaluating complex arithmetic expressions and (b) summarizing news articles. For both tasks, we create custom datasets to fine-tune an LLM. The goal of fine-tuning is twofold: first, to make the LLM learn to solve the evaluation or summarization task, and second, to train it to identify the minimal attention spans required for each step of the task. As a result, the fine-tuned model is able to convert these self-identified minimal attention spans into sparse attention masks on-the-fly during inference. We develop a custom CUDA kernel to take advantage of the reduced context to attend to. We demonstrate that using this custom CUDA kernel improves the throughput of LLM inference by 28%. Our work presents an end-to-end demonstration showing that training LLMs to self-select their attention spans speeds up autoregressive inference in solving real-world tasks.
Interpretable Predictive Models to Understand Risk Factors for Maternal and Fetal Outcomes
Oct 16, 2023Although most pregnancies result in a good outcome, complications are not uncommon and can be associated with serious implications for mothers and babies. Predictive modeling has the potential to improve outcomes through better understanding of risk factors, heightened surveillance for high risk patients, and more timely and appropriate interventions, thereby helping obstetricians deliver better care. We identify and study the most important risk factors for four types of pregnancy complications: (i) severe maternal morbidity, (ii) shoulder dystocia, (iii) preterm preeclampsia, and (iv) antepartum stillbirth. We use an Explainable Boosting Machine (EBM), a high-accuracy glass-box learning method, for prediction and identification of important risk factors. We undertake external validation and perform an extensive robustness analysis of the EBM models. EBMs match the accuracy of other black-box ML methods such as deep neural networks and random forests, and outperform logistic regression, while being more interpretable. EBMs prove to be robust. The interpretability of the EBM models reveals surprising insights into the features contributing to risk (e.g. maternal height is the second most important feature for shoulder dystocia) and may have potential for clinical application in the prediction and prevention of serious complications in pregnancy.
Using Interpretable Machine Learning to Predict Maternal and Fetal Outcomes
Jul 12, 2022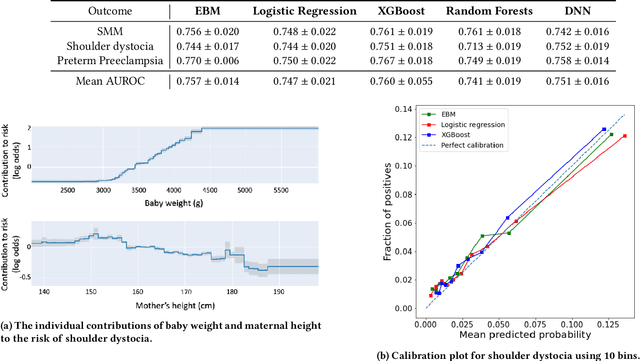

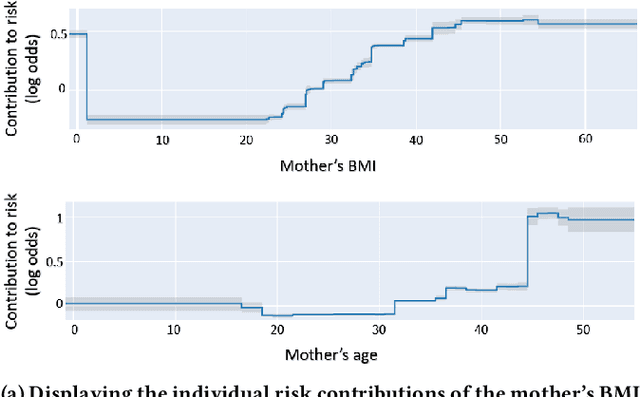
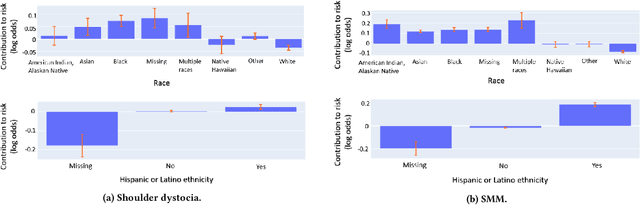
Most pregnancies and births result in a good outcome, but complications are not uncommon and when they do occur, they can be associated with serious implications for mothers and babies. Predictive modeling has the potential to improve outcomes through better understanding of risk factors, heightened surveillance, and more timely and appropriate interventions, thereby helping obstetricians deliver better care. For three types of complications we identify and study the most important risk factors using Explainable Boosting Machine (EBM), a glass box model, in order to gain intelligibility: (i) Severe Maternal Morbidity (SMM), (ii) shoulder dystocia, and (iii) preterm preeclampsia. While using the interpretability of EBM's to reveal surprising insights into the features contributing to risk, our experiments show EBMs match the accuracy of other black-box ML methods such as deep neural nets and random forests.