 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the difficulty of low-precision post-training quantization of large language models
Paper and Code
Oct 18, 2024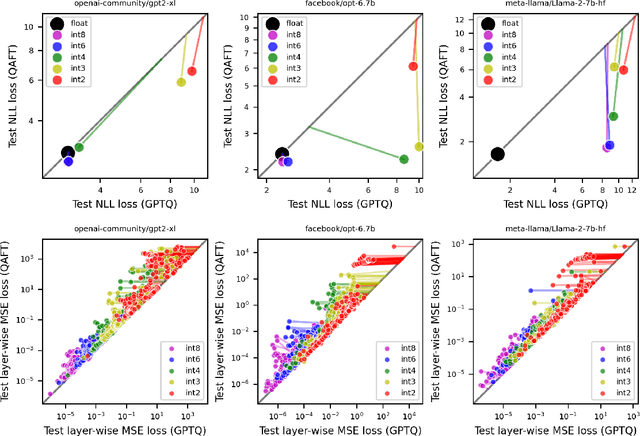
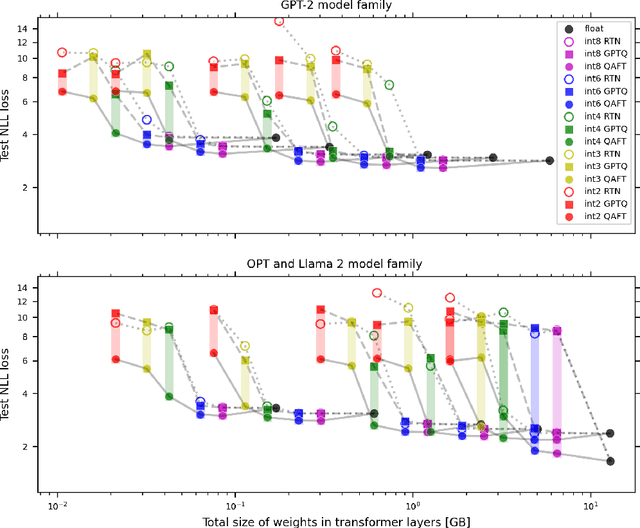
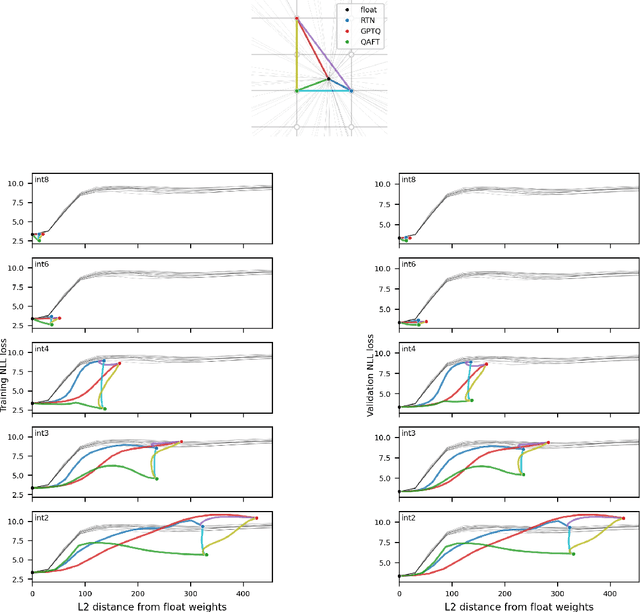
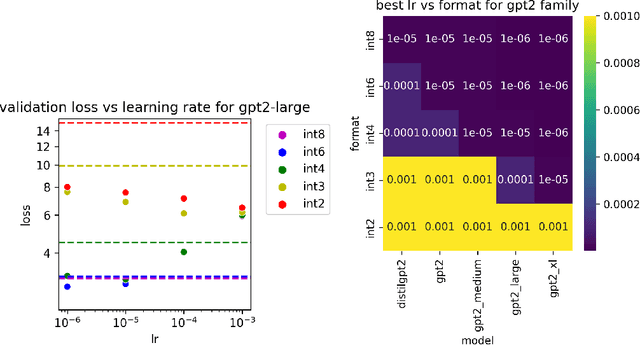
Large language models of high parameter counts are computationally expensive, yet can be made much more efficient by compressing their weights to very low numerical precision. This can be achieved either through post-training quantization by minimizing local, layer-wise quantization errors, or through quantization-aware fine-tuning by minimizing the global loss function. In this study, we discovered that, under the same data constraint, the former approach nearly always fared worse than the latter, a phenomenon particularly prominent when the numerical precision is very low. We further showed that this difficulty of post-training quantization arose from stark misalignment between optimization of the local and global objective functions. Our findings explains limited utility in minimization of local quantization error and the importance of direct quantization-aware fine-tuning, in the regime of large models at very low precision.