 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMF-QAT: Multi-Format Quantization-Aware Training for Elastic Inference
Apr 01, 2026Quantization-aware training (QAT) is typically performed for a single target numeric format, while practical deployments often need to choose numerical precision at inference time based on hardware support or runtime constraints. We study multi-format QAT, where a single model is trained to be robust across multiple quantization formats. We find that multi-format QAT can match single-format QAT at each target precision, yielding one model that performs well overall across different formats, even formats that were not seen during training. To enable practical deployment, we propose the Slice-and-Scale conversion procedure for both MXINT and MXFP that converts a high-precision representation into lower-precision formats without re-training. Building on this, we introduce a pipeline that (i) trains a model with multi-format QAT, (ii) stores a single anchor format checkpoint (MXINT8/MXFP8), and (iii) allows on-the-fly conversion to lower MXINT or MXFP formats at runtime with negligible-or no-additional accuracy degradation. Together, these components provide a practical path to elastic precision scaling and allow selecting the runtime format at inference time across diverse deployment targets.
ResQ: Mixed-Precision Quantization of Large Language Models with Low-Rank Residuals
Dec 18, 2024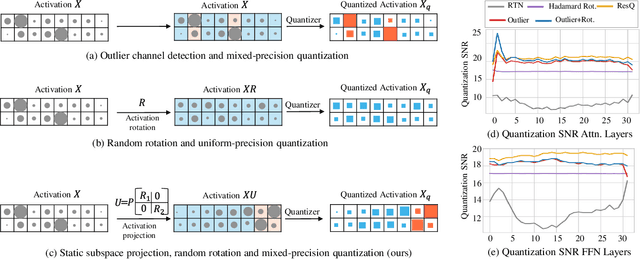
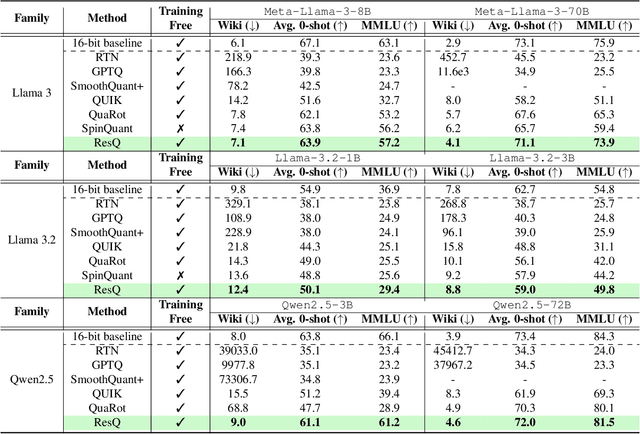
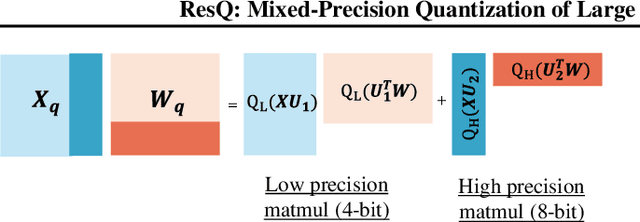

Post-training quantization (PTQ) of large language models (LLMs) holds the promise in reducing the prohibitive computational cost at inference time. Quantization of all weight, activation and key-value (KV) cache tensors to 4-bit without significantly degrading generalizability is challenging, due to the high quantization error caused by extreme outliers in activations. To tackle this problem, we propose ResQ, a PTQ method that pushes further the state-of-the-art. By means of principal component analysis (PCA), it identifies a low-rank subspace (in practice 1/8 of the hidden dimension) in which activation variances are highest, and keep the coefficients within this subspace in high precision, e.g. 8-bit, while quantizing the rest to 4-bit. Within each subspace, invariant random rotation is applied to further suppress outliers. We show that this is a provably optimal mixed precision quantization scheme that minimizes error. With the Llama families of models, we demonstrate that ResQ outperforms recent uniform and mixed precision PTQ methods on a variety of benchmarks, achieving up to 33% lower perplexity on Wikitext than the next best method SpinQuant, and a 2.4x speedup over 16-bit baseline. Code is available at https://github.com/utkarsh-dmx/project-resq.
Understanding the difficulty of low-precision post-training quantization of large language models
Oct 18, 2024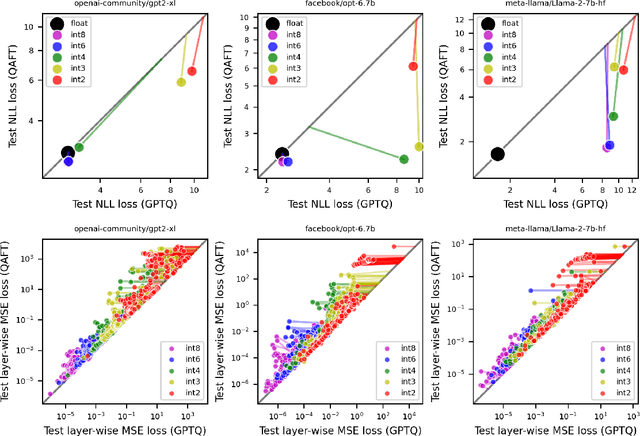
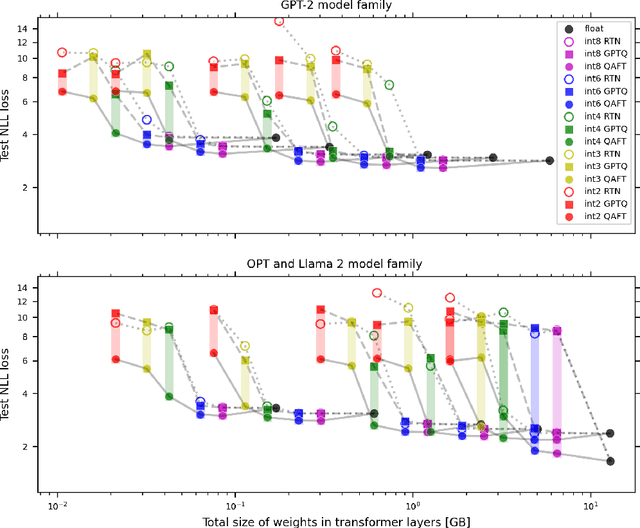
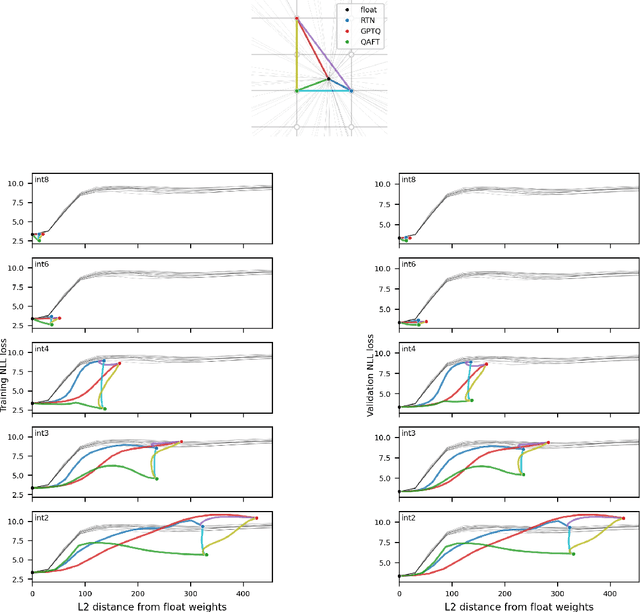
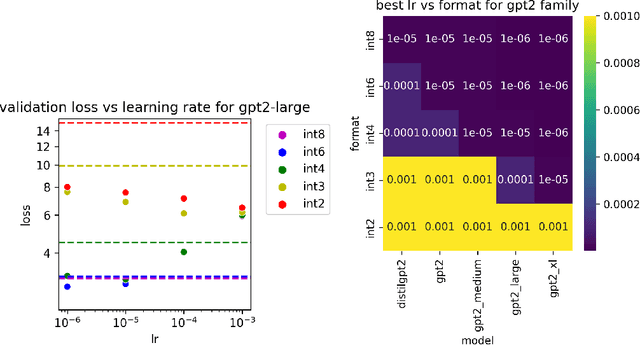
Large language models of high parameter counts are computationally expensive, yet can be made much more efficient by compressing their weights to very low numerical precision. This can be achieved either through post-training quantization by minimizing local, layer-wise quantization errors, or through quantization-aware fine-tuning by minimizing the global loss function. In this study, we discovered that, under the same data constraint, the former approach nearly always fared worse than the latter, a phenomenon particularly prominent when the numerical precision is very low. We further showed that this difficulty of post-training quantization arose from stark misalignment between optimization of the local and global objective functions. Our findings explains limited utility in minimization of local quantization error and the importance of direct quantization-aware fine-tuning, in the regime of large models at very low precision.
Scaling laws for post-training quantized large language models
Oct 15, 2024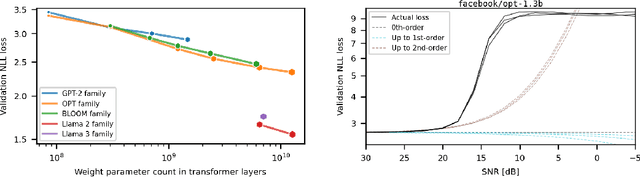
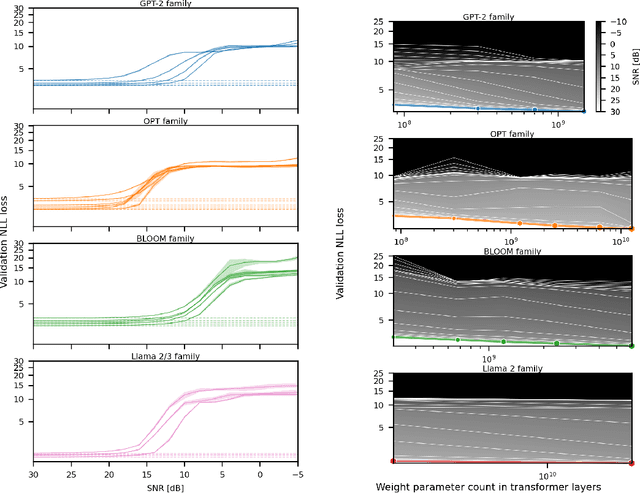
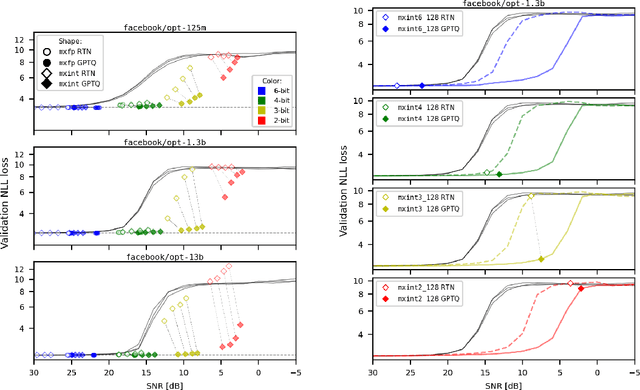
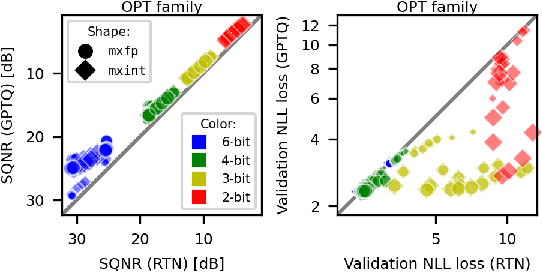
Generalization abilities of well-trained large language models (LLMs) are known to scale predictably as a function of model size. In contrast to the existence of practical scaling laws governing pre-training, the quality of LLMs after post-training compression remains highly unpredictable, often requiring case-by-case validation in practice. In this work, we attempted to close this gap for post-training weight quantization of LLMs by conducting a systematic empirical study on multiple LLM families quantized to numerous low-precision tensor data types using popular weight quantization techniques. We identified key scaling factors pertaining to characteristics of the local loss landscape, based on which the performance of quantized LLMs can be reasonably well predicted by a statistical model.
Combining multiple post-training techniques to achieve most efficient quantized LLMs
May 12, 2024Large Language Models (LLMs) have distinguished themselves with outstanding performance in complex language modeling tasks, yet they come with significant computational and storage challenges. This paper explores the potential of quantization to mitigate these challenges. We systematically study the combined application of two well-known post-training techniques, SmoothQuant and GPTQ, and provide a comprehensive analysis of their interactions and implications for advancing LLM quantization. We enhance the versatility of both techniques by enabling quantization to microscaling (MX) formats, expanding their applicability beyond their initial fixed-point format targets. We show that by applying GPTQ and SmoothQuant, and employing MX formats for quantizing models, we can achieve a significant reduction in the size of OPT models by up to 4x and LLaMA models by up to 3x with a negligible perplexity increase of 1-3%.
Self-Selected Attention Span for Accelerating Large Language Model Inference
Apr 14, 2024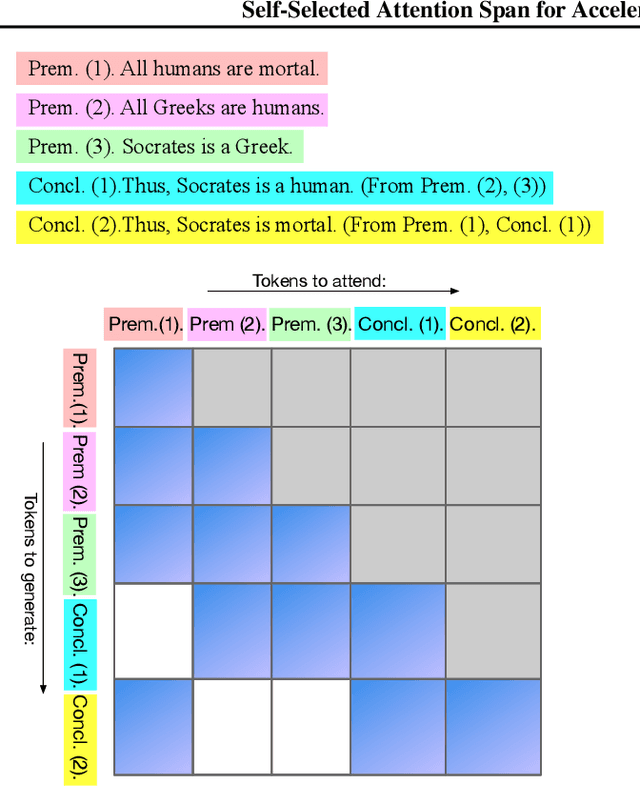
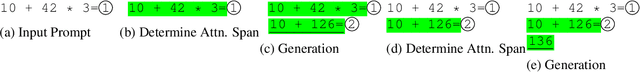
Large language models (LLMs) can solve challenging tasks. However, their inference computation on modern GPUs is highly inefficient due to the increasing number of tokens they must attend to as they generate new ones. To address this inefficiency, we capitalize on LLMs' problem-solving capabilities to optimize their own inference-time efficiency. We demonstrate with two specific tasks: (a) evaluating complex arithmetic expressions and (b) summarizing news articles. For both tasks, we create custom datasets to fine-tune an LLM. The goal of fine-tuning is twofold: first, to make the LLM learn to solve the evaluation or summarization task, and second, to train it to identify the minimal attention spans required for each step of the task. As a result, the fine-tuned model is able to convert these self-identified minimal attention spans into sparse attention masks on-the-fly during inference. We develop a custom CUDA kernel to take advantage of the reduced context to attend to. We demonstrate that using this custom CUDA kernel improves the throughput of LLM inference by 28%. Our work presents an end-to-end demonstration showing that training LLMs to self-select their attention spans speeds up autoregressive inference in solving real-world tasks.
Mixed-Precision Quantization with Cross-Layer Dependencies
Jul 11, 2023



Quantization is commonly used to compress and accelerate deep neural networks. Quantization assigning the same bit-width to all layers leads to large accuracy degradation at low precision and is wasteful at high precision settings. Mixed-precision quantization (MPQ) assigns varied bit-widths to layers to optimize the accuracy-efficiency trade-off. Existing methods simplify the MPQ problem by assuming that quantization errors at different layers act independently. We show that this assumption does not reflect the true behavior of quantized deep neural networks. We propose the first MPQ algorithm that captures the cross-layer dependency of quantization error. Our algorithm (CLADO) enables a fast approximation of pairwise cross-layer error terms by solving linear equations that require only forward evaluations of the network on a small amount of data. Decisions on layerwise bit-width assignments are then determined by optimizing a new MPQ formulation dependent on these cross-layer quantization errors via the Integer Quadratic Program (IQP), which can be solved within seconds. We conduct experiments on multiple networks on the Imagenet dataset and demonstrate an improvement, in top-1 classification accuracy, of up to 27% over uniform precision quantization, and up to 15% over existing MPQ methods.
Loom: Exploiting Weight and Activation Precisions to Accelerate Convolutional Neural Networks
May 16, 2018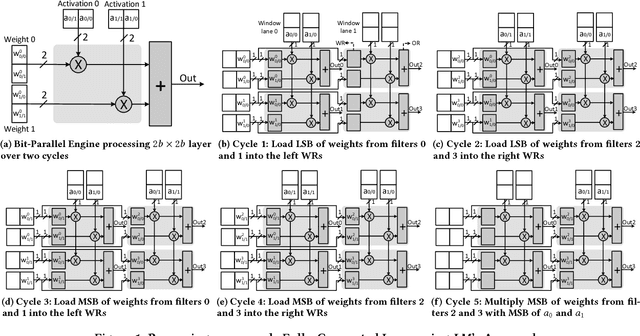
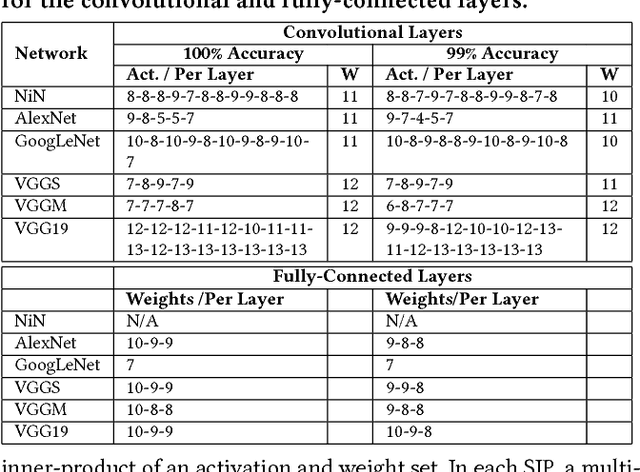
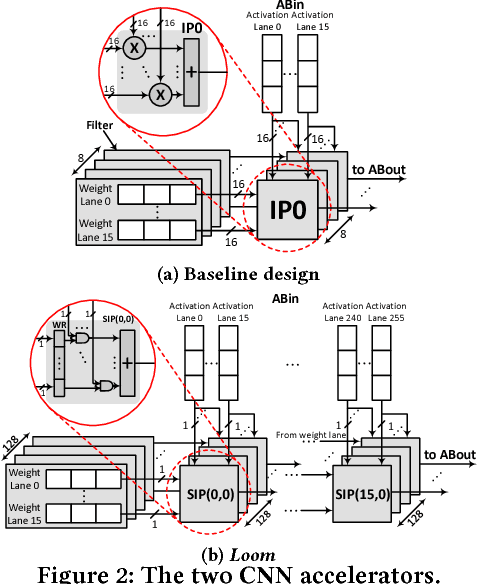
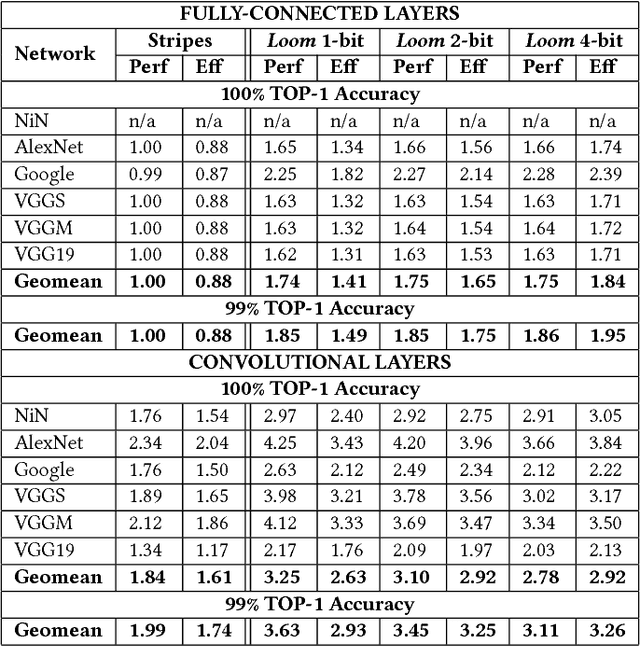
Loom (LM), a hardware inference accelerator for Convolutional Neural Networks (CNNs) is presented. In LM every bit of data precision that can be saved translates to proportional performance gains. Specifically, for convolutional layers LM's execution time scales inversely proportionally with the precisions of both weights and activations. For fully-connected layers LM's performance scales inversely proportionally with the precision of the weights. LM targets area- and bandwidth-constrained System-on-a-Chip designs such as those found on mobile devices that cannot afford the multi-megabyte buffers that would be needed to store each layer on-chip. Accordingly, given a data bandwidth budget, LM boosts energy efficiency and performance over an equivalent bit-parallel accelerator. For both weights and activations LM can exploit profile-derived perlayer precisions. However, at runtime LM further trims activation precisions at a much smaller than a layer granularity. Moreover, it can naturally exploit weight precision variability at a smaller granularity than a layer. On average, across several image classification CNNs and for a configuration that can perform the equivalent of 128 16b x 16b multiply-accumulate operations per cycle LM outperforms a state-of-the-art bit-parallel accelerator [1] by 4.38x without any loss in accuracy while being 3.54x more energy efficient. LM can trade-off accuracy for additional improvements in execution performance and energy efficiency and compares favorably to an accelerator that targeted only activation precisions. We also study 2- and 4-bit LM variants and find the the 2-bit per cycle variant is the most energy efficient.
DPRed: Making Typical Activation Values Matter In Deep Learning Computing
May 15, 2018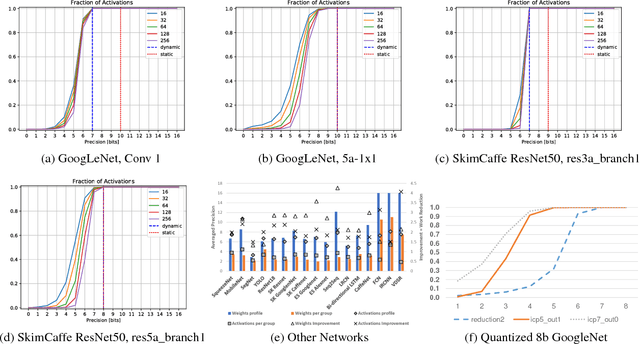

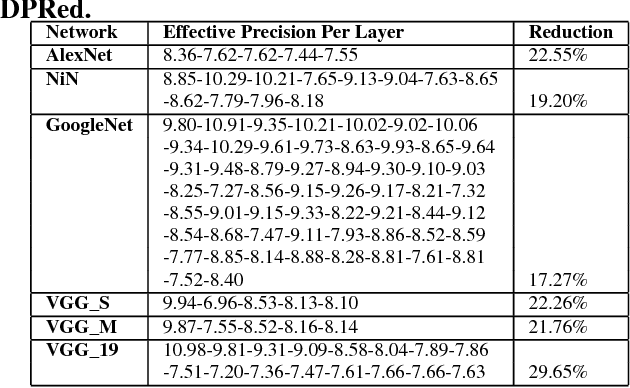

We show that selecting a fixed precision for all values in Convolutional Neural Networks, even if that precision is different per layer, amounts to worst case design. We show that much lower precisions can be used if we could target the common case instead by tailoring the precision at a much finer granularity than that of a layer. While this observation may not be surprising, to date no design takes advantage of it in practice. We propose Dynamic Prediction Reduction (DPRed), where hardware on-the-fly detects the precision activations need at a much finer granularity than a whole layer. Further we encode activations and weights using the respective per group dynamically and statically detected precisions to reduce off- and on-chip storage and communication. We demonstrate a practical implementation of DPRed with DPRed Stripes (DPRS), a data-parallel hardware accelerator that adjusts precision on-the-fly to accommodate the values of the activations it processes concurrently. DPRS accelerates convolutional layers and executes unmodified convolutional neural networks. Ignoring offchip communication, DPRS is 2.61x faster and 1.84x more energy efficient than a fixed-precision accelerator for a set of convolutional neural networks. We further extend DPRS to exploit activation and weight precisions for fully-connected layers. The enhanced design improves average performance and energy efficiency respectively by 2.59x and 1.19x over the fixed-precision accelerator for a broader set of neural networks. Finally, we consider a lower cost variant that supports only even precision widths which offers better energy efficiency. Taking into account off-chip communication, DPRed compression reduces off-chip traffic to nearly 35% on average compared to no compression making it possible to sustain higher performance for a given off-chip memory interface while also boosting energy efficiency.
Laconic Deep Learning Computing
May 10, 2018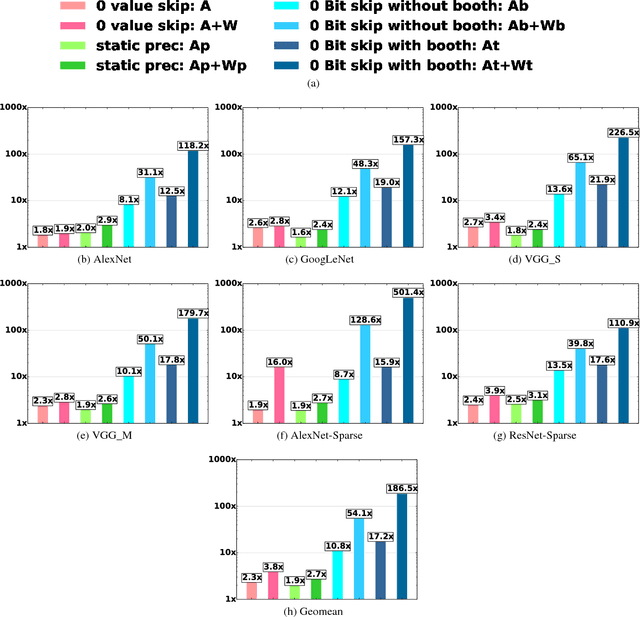
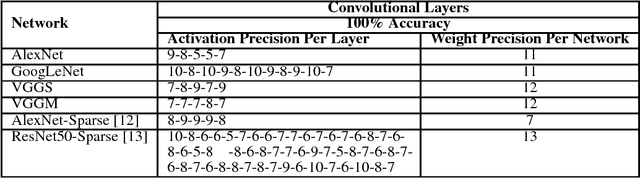
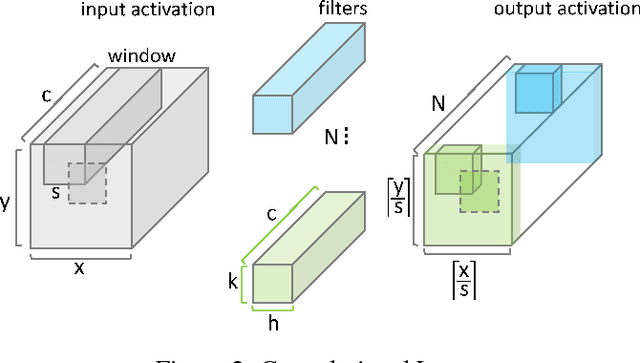
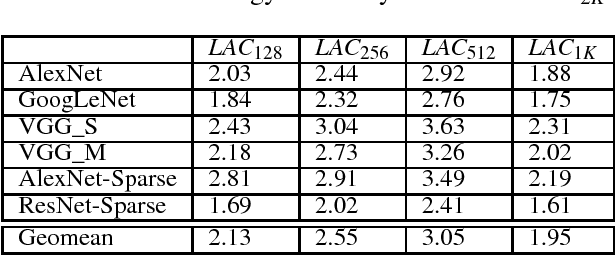
We motivate a method for transparently identifying ineffectual computations in unmodified Deep Learning models and without affecting accuracy. Specifically, we show that if we decompose multiplications down to the bit level the amount of work performed during inference for image classification models can be consistently reduced by two orders of magnitude. In the best case studied of a sparse variant of AlexNet, this approach can ideally reduce computation work by more than 500x. We present Laconic a hardware accelerator that implements this approach to improve execution time, and energy efficiency for inference with Deep Learning Networks. Laconic judiciously gives up some of the work reduction potential to yield a low-cost, simple, and energy efficient design that outperforms other state-of-the-art accelerators. For example, a Laconic configuration that uses a weight memory interface with just 128 wires outperforms a conventional accelerator with a 2K-wire weight memory interface by 2.3x on average while being 2.13x more energy efficient on average. A Laconic configuration that uses a 1K-wire weight memory interface, outperforms the 2K-wire conventional accelerator by 15.4x and is 1.95x more energy efficient. Laconic does not require but rewards advances in model design such as a reduction in precision, the use of alternate numeric representations that reduce the number of bits that are "1", or an increase in weight or activation sparsity.