 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPack: Off-Chip, Lossless Data Compression for Efficient Deep Learning Inference
Jan 21, 2022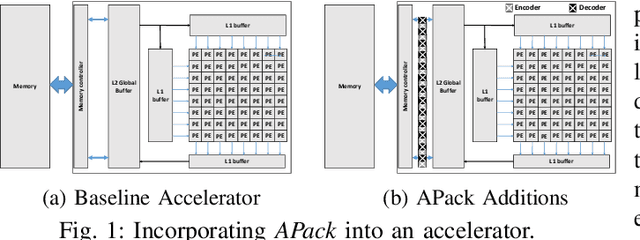
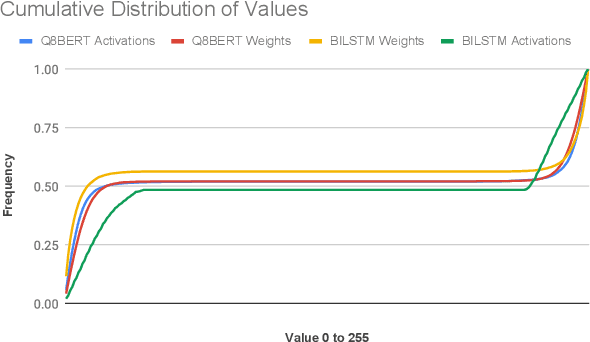
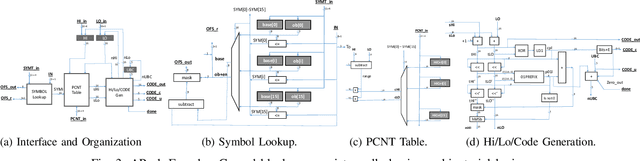
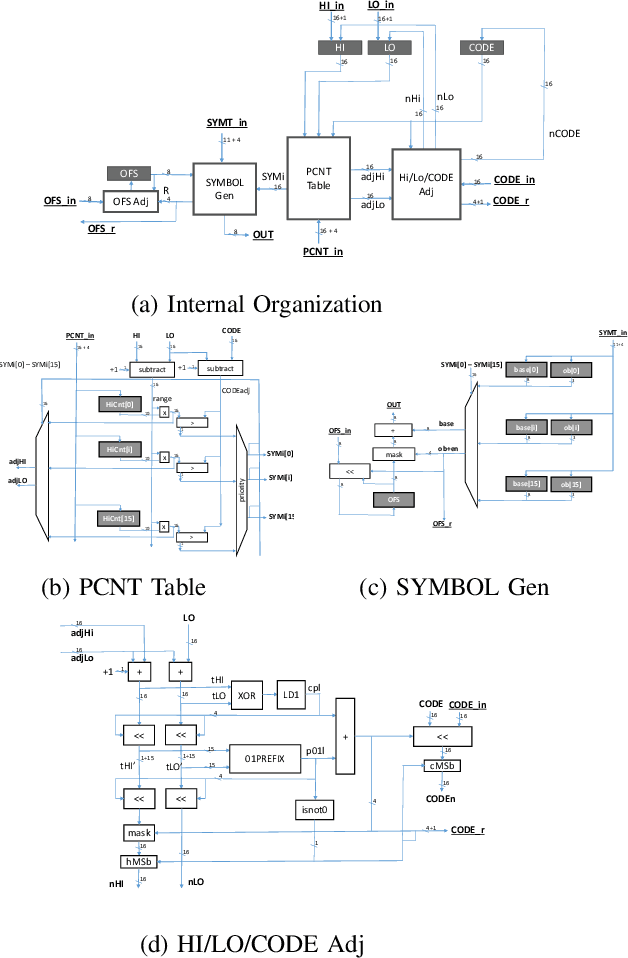
Data accesses between on- and off-chip memories account for a large fraction of overall energy consumption during inference with deep learning networks. We present APack, a simple and effective, lossless, off-chip memory compression technique for fixed-point quantized models. APack reduces data widths by exploiting the non-uniform value distribution in deep learning applications. APack can be used to increase the effective memory capacity, to reduce off-chip traffic, and/or to achieve the desired performance/energy targets while using smaller off-chip memories. APack builds upon arithmetic coding, encoding each value as an arithmetically coded variable length prefix, plus an offset. To maximize compression ratio a heuristic software algorithm partitions the value space into groups each sharing a common prefix. APack exploits memory access parallelism by using several, pipelined encoder/decoder units in parallel and keeps up with the high data bandwidth demands of deep learning. APack can be used with any machine learning accelerator. In the demonstrated configuration, APack is placed just before the off-chip memory controller so that he rest of the on-chip memory and compute units thus see the original data stream. We implemented the APack compressor and decompressor in Verilog and in a 65nm tech node demonstrating its performance and energy efficiency. Indicatively, APack reduces data footprint of weights and activations to 60% and 48% respectively on average over a wide set of 8-bit quantized models. It naturally adapts and compresses models that use even more aggressive quantization methods. When integrated with a Tensorcore-based accelerator, APack boosts the speedup and energy efficiency to 1.44X and 1.37X respectively.
BitPruning: Learning Bitlengths for Aggressive and Accurate Quantization
Feb 08, 2020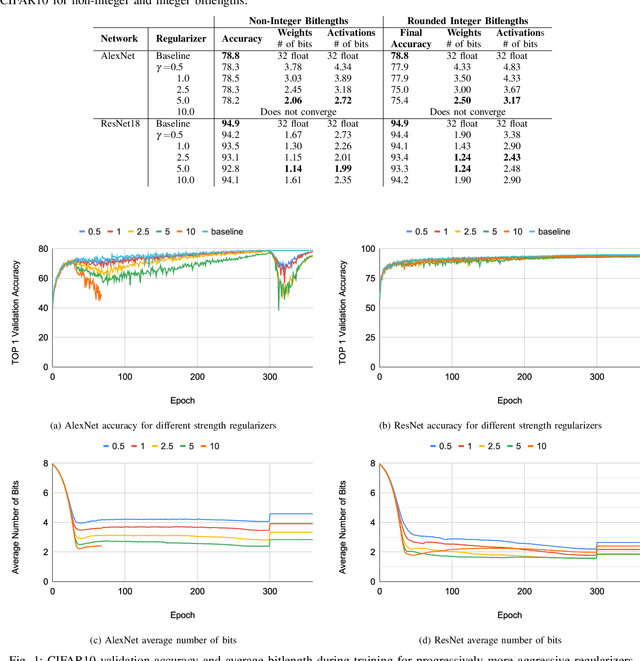
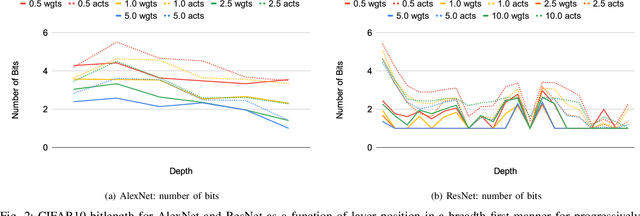
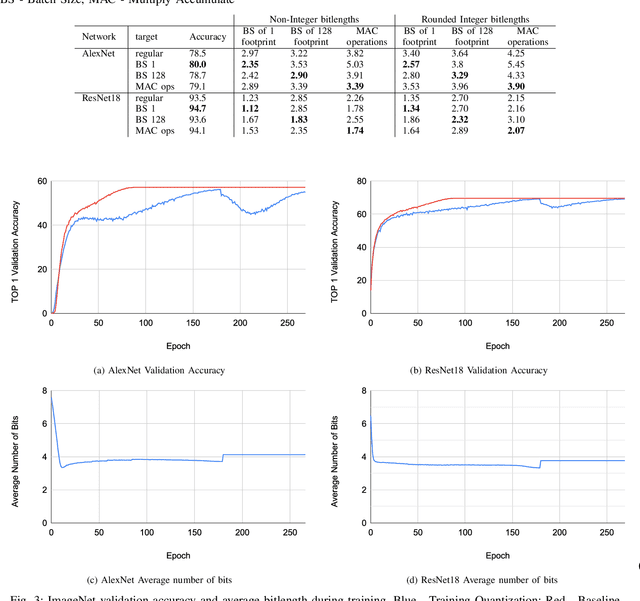
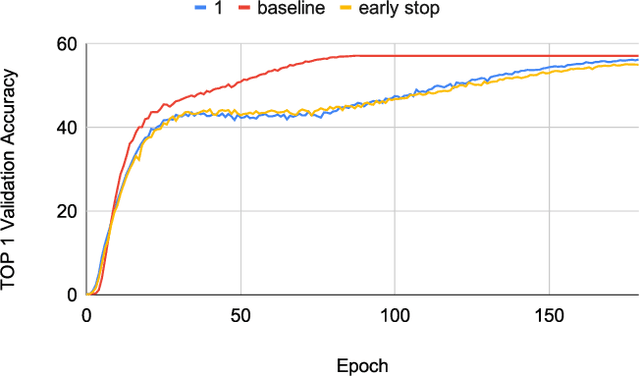
Neural networks have demonstrably achieved state-of-the art accuracy using low-bitlength integer quantization, yielding both execution time and energy benefits on existing hardware designs that support short bitlengths. However, the question of finding the minimum bitlength for a desired accuracy remains open. We introduce a training method for minimizing inference bitlength at any granularity while maintaining accuracy. Furthermore, we propose a regularizer that penalizes large bitlength representations throughout the architecture and show how it can be modified to minimize other quantifiable criteria, such as number of operations or memory footprint. We demonstrate that our method learns thrifty representations while maintaining accuracy. With ImageNet, the method produces an average per layer bitlength of 4.13 and 3.76 bits on AlexNet and ResNet18 respectively, remaining within 2.0% and 0.5% of the baseline TOP-1 accuracy.
Loom: Exploiting Weight and Activation Precisions to Accelerate Convolutional Neural Networks
May 16, 2018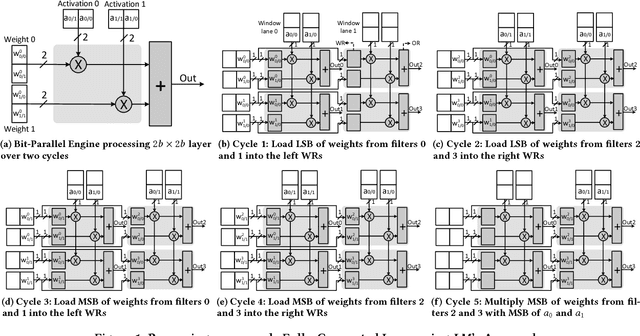
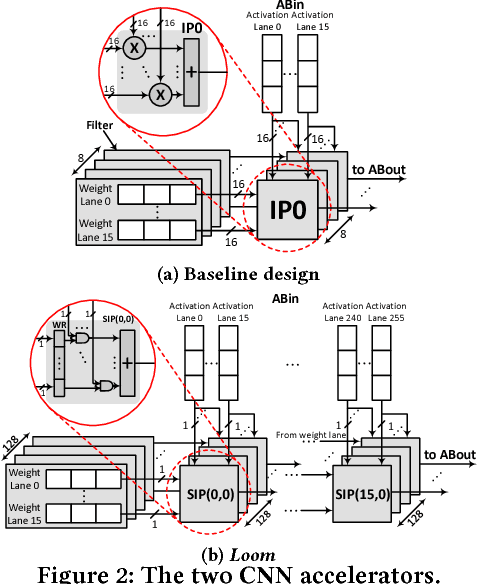
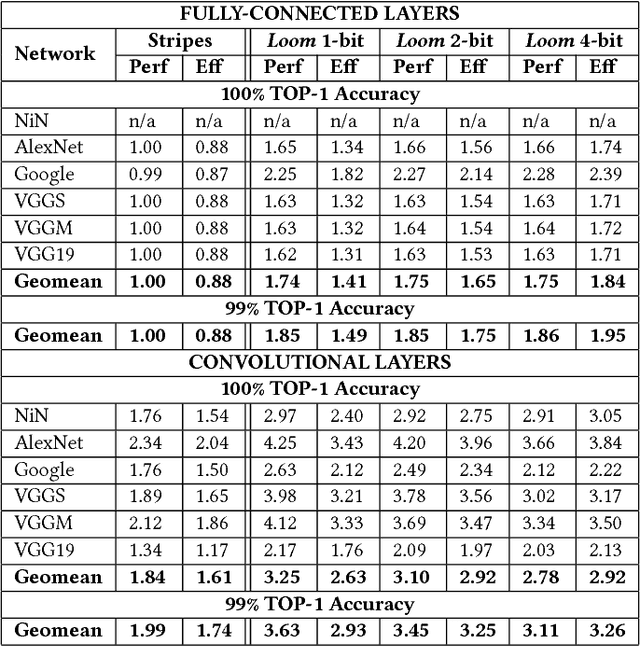
Loom (LM), a hardware inference accelerator for Convolutional Neural Networks (CNNs) is presented. In LM every bit of data precision that can be saved translates to proportional performance gains. Specifically, for convolutional layers LM's execution time scales inversely proportionally with the precisions of both weights and activations. For fully-connected layers LM's performance scales inversely proportionally with the precision of the weights. LM targets area- and bandwidth-constrained System-on-a-Chip designs such as those found on mobile devices that cannot afford the multi-megabyte buffers that would be needed to store each layer on-chip. Accordingly, given a data bandwidth budget, LM boosts energy efficiency and performance over an equivalent bit-parallel accelerator. For both weights and activations LM can exploit profile-derived perlayer precisions. However, at runtime LM further trims activation precisions at a much smaller than a layer granularity. Moreover, it can naturally exploit weight precision variability at a smaller granularity than a layer. On average, across several image classification CNNs and for a configuration that can perform the equivalent of 128 16b x 16b multiply-accumulate operations per cycle LM outperforms a state-of-the-art bit-parallel accelerator [1] by 4.38x without any loss in accuracy while being 3.54x more energy efficient. LM can trade-off accuracy for additional improvements in execution performance and energy efficiency and compares favorably to an accelerator that targeted only activation precisions. We also study 2- and 4-bit LM variants and find the the 2-bit per cycle variant is the most energy efficient.
Laconic Deep Learning Computing
May 10, 2018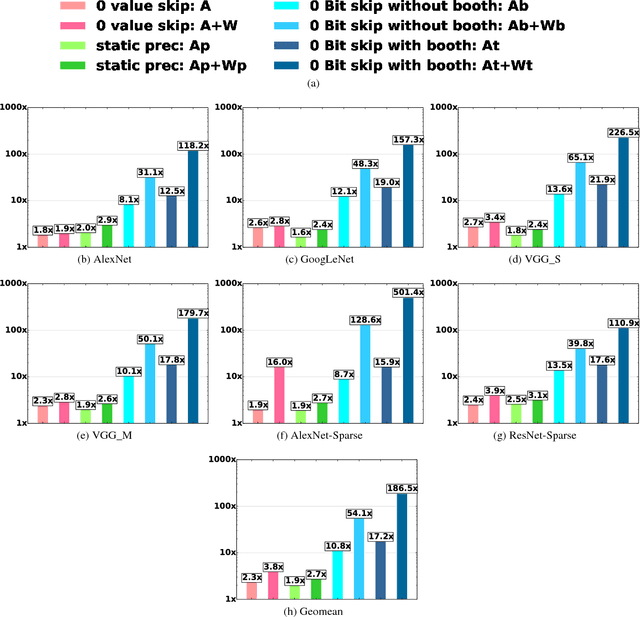
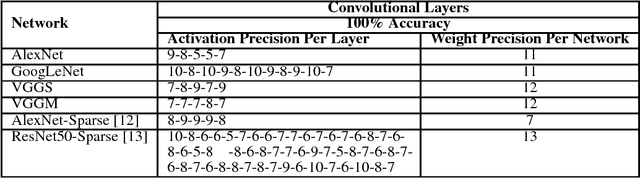
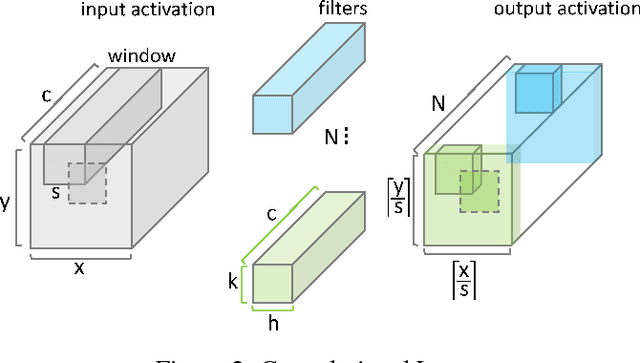
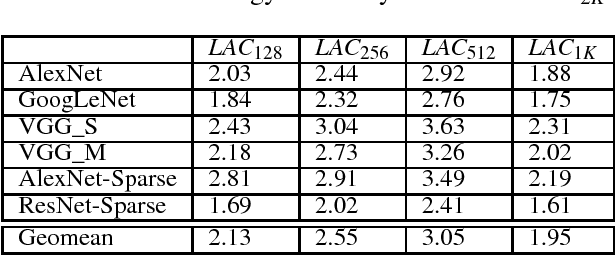
We motivate a method for transparently identifying ineffectual computations in unmodified Deep Learning models and without affecting accuracy. Specifically, we show that if we decompose multiplications down to the bit level the amount of work performed during inference for image classification models can be consistently reduced by two orders of magnitude. In the best case studied of a sparse variant of AlexNet, this approach can ideally reduce computation work by more than 500x. We present Laconic a hardware accelerator that implements this approach to improve execution time, and energy efficiency for inference with Deep Learning Networks. Laconic judiciously gives up some of the work reduction potential to yield a low-cost, simple, and energy efficient design that outperforms other state-of-the-art accelerators. For example, a Laconic configuration that uses a weight memory interface with just 128 wires outperforms a conventional accelerator with a 2K-wire weight memory interface by 2.3x on average while being 2.13x more energy efficient on average. A Laconic configuration that uses a 1K-wire weight memory interface, outperforms the 2K-wire conventional accelerator by 15.4x and is 1.95x more energy efficient. Laconic does not require but rewards advances in model design such as a reduction in precision, the use of alternate numeric representations that reduce the number of bits that are "1", or an increase in weight or activation sparsity.