 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBitPruning: Learning Bitlengths for Aggressive and Accurate Quantization
Paper and Code
Feb 08, 2020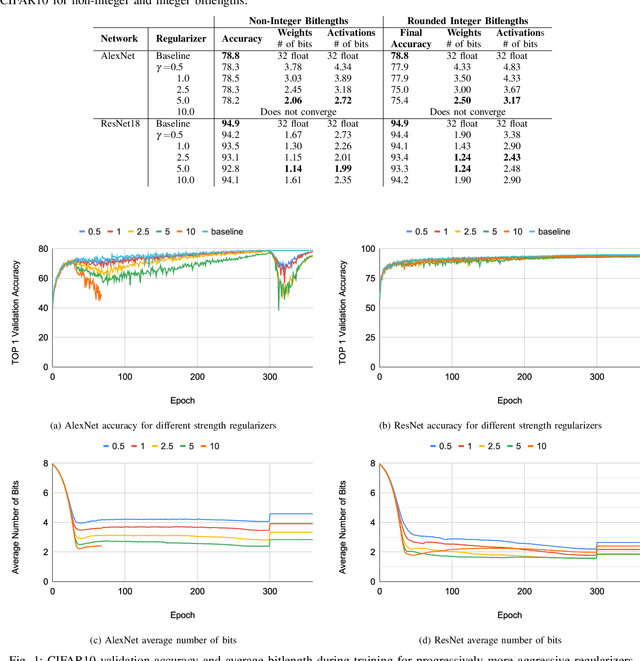
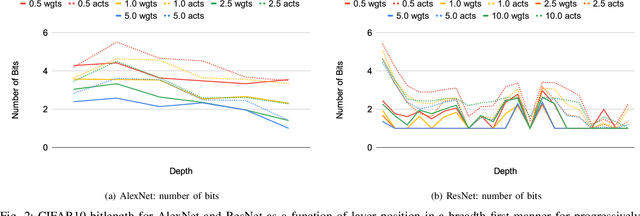
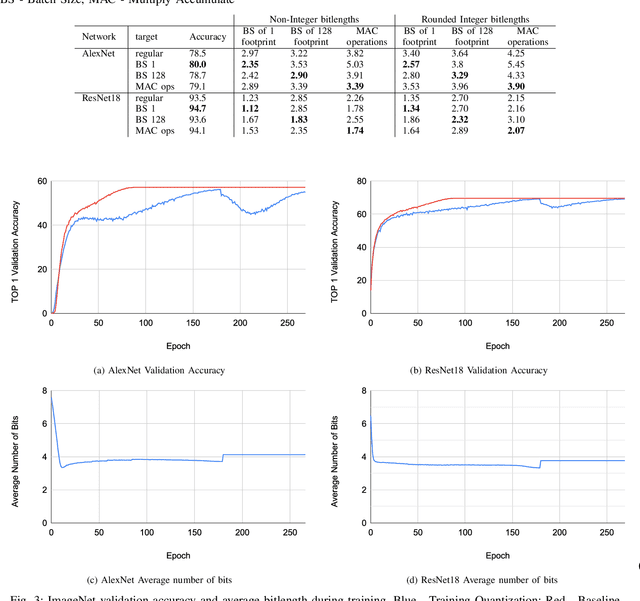
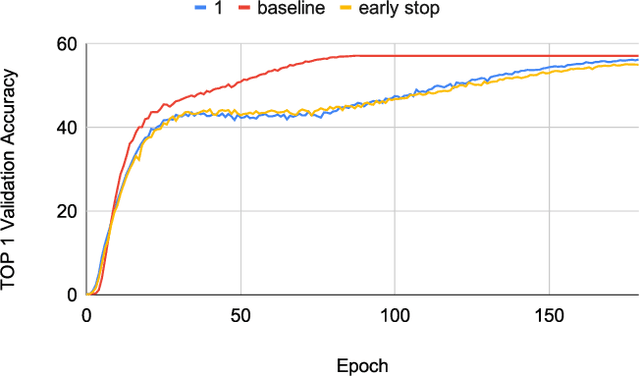
Neural networks have demonstrably achieved state-of-the art accuracy using low-bitlength integer quantization, yielding both execution time and energy benefits on existing hardware designs that support short bitlengths. However, the question of finding the minimum bitlength for a desired accuracy remains open. We introduce a training method for minimizing inference bitlength at any granularity while maintaining accuracy. Furthermore, we propose a regularizer that penalizes large bitlength representations throughout the architecture and show how it can be modified to minimize other quantifiable criteria, such as number of operations or memory footprint. We demonstrate that our method learns thrifty representations while maintaining accuracy. With ImageNet, the method produces an average per layer bitlength of 4.13 and 3.76 bits on AlexNet and ResNet18 respectively, remaining within 2.0% and 0.5% of the baseline TOP-1 accuracy.