 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPack: Off-Chip, Lossless Data Compression for Efficient Deep Learning Inference
Paper and Code
Jan 21, 2022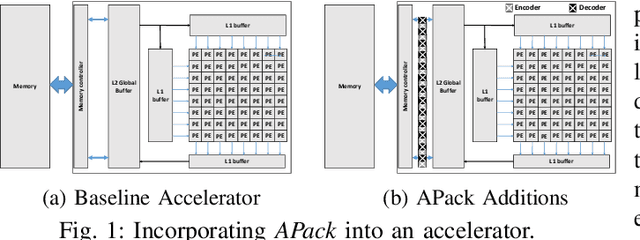
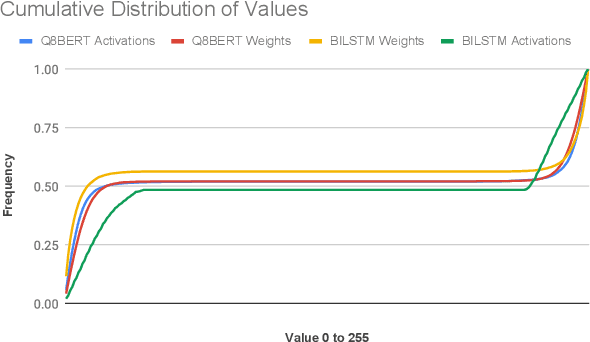
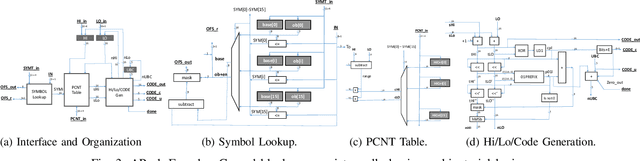
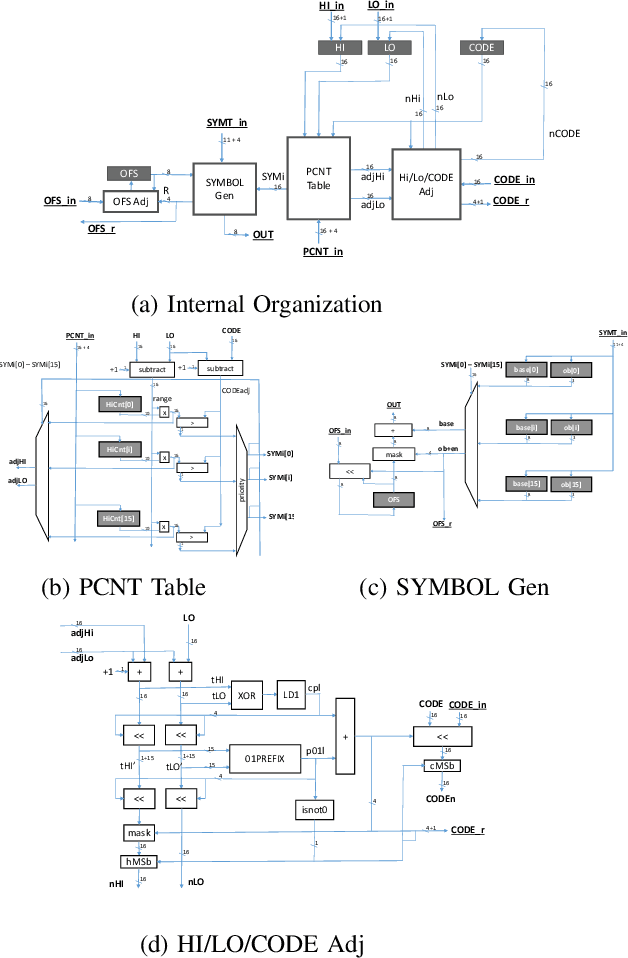
Data accesses between on- and off-chip memories account for a large fraction of overall energy consumption during inference with deep learning networks. We present APack, a simple and effective, lossless, off-chip memory compression technique for fixed-point quantized models. APack reduces data widths by exploiting the non-uniform value distribution in deep learning applications. APack can be used to increase the effective memory capacity, to reduce off-chip traffic, and/or to achieve the desired performance/energy targets while using smaller off-chip memories. APack builds upon arithmetic coding, encoding each value as an arithmetically coded variable length prefix, plus an offset. To maximize compression ratio a heuristic software algorithm partitions the value space into groups each sharing a common prefix. APack exploits memory access parallelism by using several, pipelined encoder/decoder units in parallel and keeps up with the high data bandwidth demands of deep learning. APack can be used with any machine learning accelerator. In the demonstrated configuration, APack is placed just before the off-chip memory controller so that he rest of the on-chip memory and compute units thus see the original data stream. We implemented the APack compressor and decompressor in Verilog and in a 65nm tech node demonstrating its performance and energy efficiency. Indicatively, APack reduces data footprint of weights and activations to 60% and 48% respectively on average over a wide set of 8-bit quantized models. It naturally adapts and compresses models that use even more aggressive quantization methods. When integrated with a Tensorcore-based accelerator, APack boosts the speedup and energy efficiency to 1.44X and 1.37X respectively.