 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrödinger's FP: Dynamic Adaptation of Floating-Point Containers for Deep Learning Training
Apr 28, 2022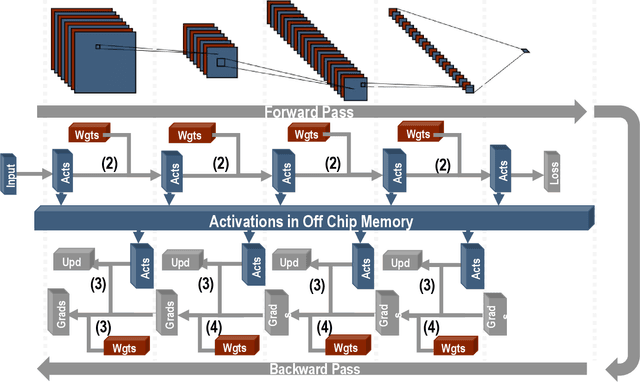
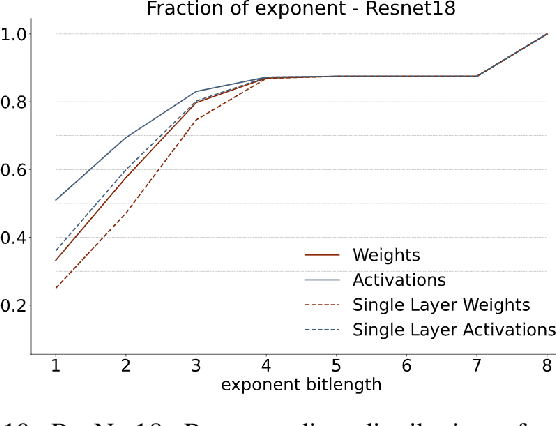
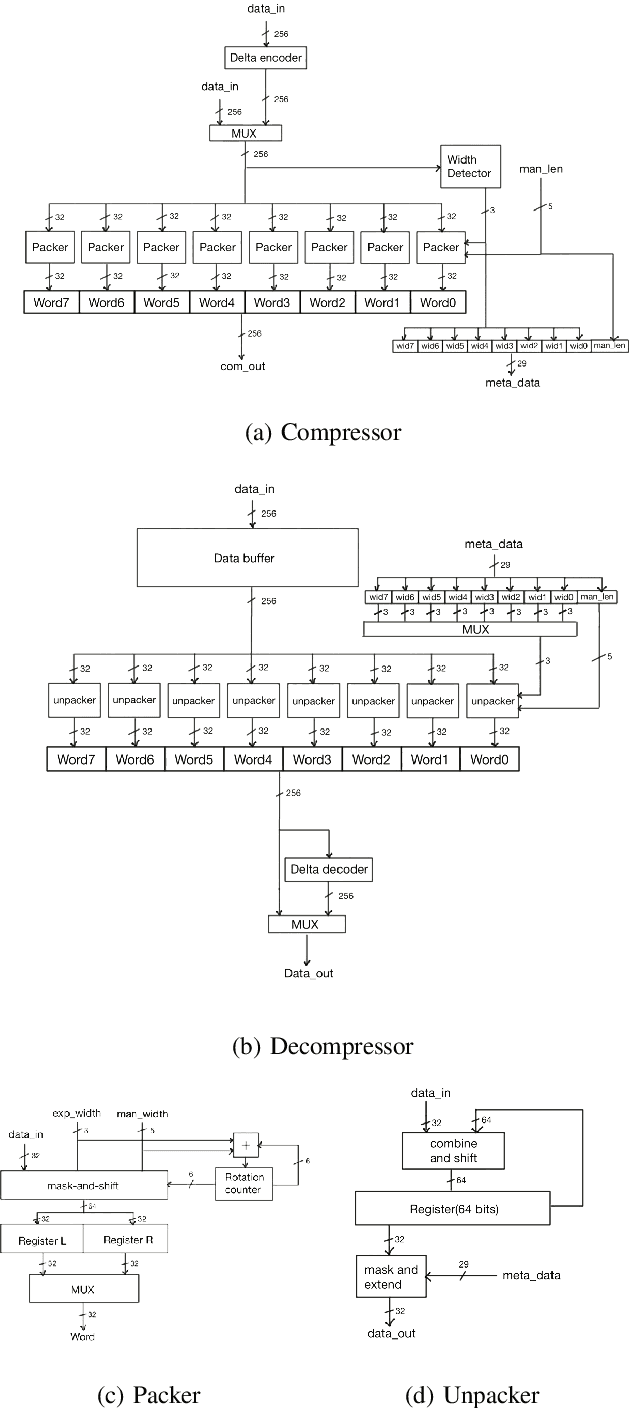
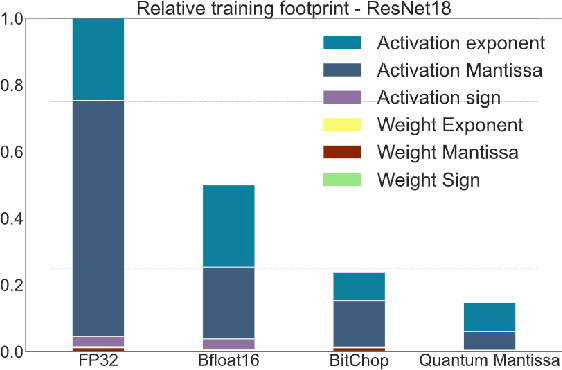
We introduce a software-hardware co-design approach to reduce memory traffic and footprint during training with BFloat16 or FP32 boosting energy efficiency and execution time performance. We introduce methods to dynamically adjust the size and format of the floating-point containers used to store activations and weights during training. The different value distributions lead us to different approaches for exponents and mantissas. Gecko exploits the favourable exponent distribution with a loss-less delta encoding approach to reduce the total exponent footprint by up to $58\%$ in comparison to a 32 bit floating point baseline. To content with the noisy mantissa distributions, we present two lossy methods to eliminate as many as possible least significant bits while not affecting accuracy. Quantum Mantissa, is a machine learning-first mantissa compression method that taps on training's gradient descent algorithm to also learn minimal mantissa bitlengths on a per-layer granularity, and obtain up to $92\%$ reduction in total mantissa footprint. Alternatively, BitChop observes changes in the loss function during training to adjust mantissa bit-length network-wide yielding a reduction of $81\%$ in footprint. Schr\"{o}dinger's FP implements hardware encoders/decoders that guided by Gecko/Quantum Mantissa or Gecko/BitChop transparently encode/decode values when transferring to/from off-chip memory boosting energy efficiency and reducing execution time.
Mokey: Enabling Narrow Fixed-Point Inference for Out-of-the-Box Floating-Point Transformer Models
Mar 23, 2022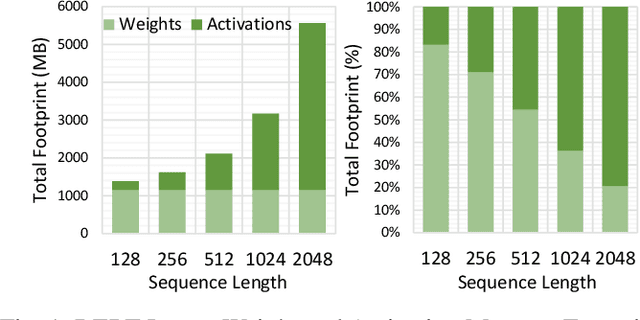
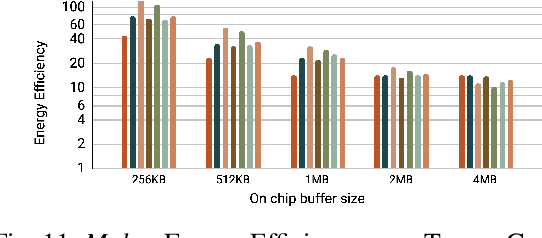
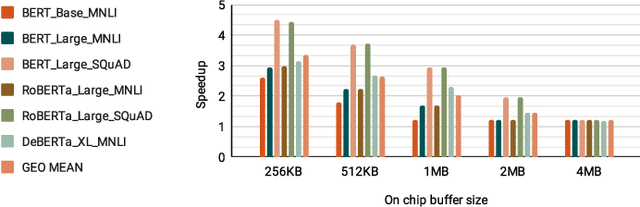
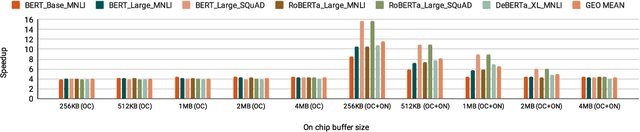
Increasingly larger and better Transformer models keep advancing state-of-the-art accuracy and capability for Natural Language Processing applications. These models demand more computational power, storage, and energy. Mokey reduces the footprint of state-of-the-art 32-bit or 16-bit floating-point transformer models by quantizing all values to 4-bit indexes into dictionaries of representative 16-bit fixed-point centroids. Mokey does not need fine-tuning, an essential feature as often the training resources or datasets are not available to many. Exploiting the range of values that naturally occur in transformer models, Mokey selects centroid values to also fit an exponential curve. This unique feature enables Mokey to replace the bulk of the original multiply-accumulate operations with narrow 3b fixed-point additions resulting in an area- and energy-efficient hardware accelerator design. Over a set of state-of-the-art transformer models, the Mokey accelerator delivers an order of magnitude improvements in energy efficiency over a Tensor Cores-based accelerator while improving performance by at least $4\times$ and as much as $15\times$ depending on the model and on-chip buffering capacity. Optionally, Mokey can be used as a memory compression assist for any other accelerator, transparently stashing wide floating-point or fixed-point activations or weights into narrow 4-bit indexes. Mokey proves superior to prior state-of-the-art quantization methods for Transformers.
APack: Off-Chip, Lossless Data Compression for Efficient Deep Learning Inference
Jan 21, 2022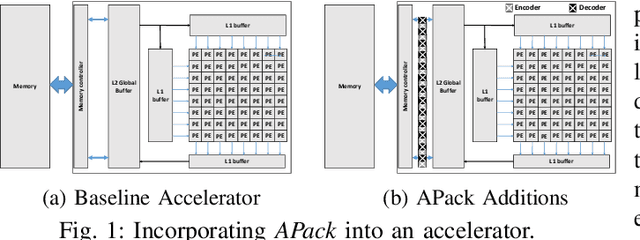
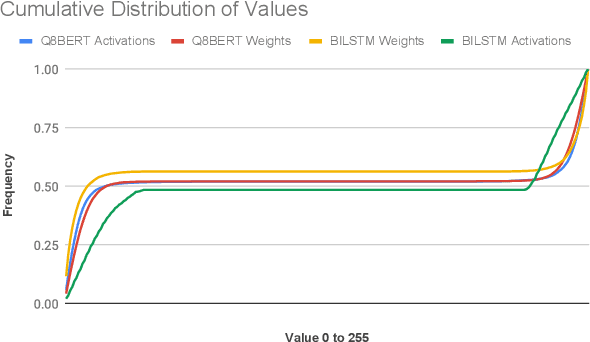
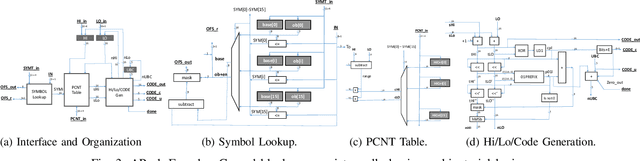
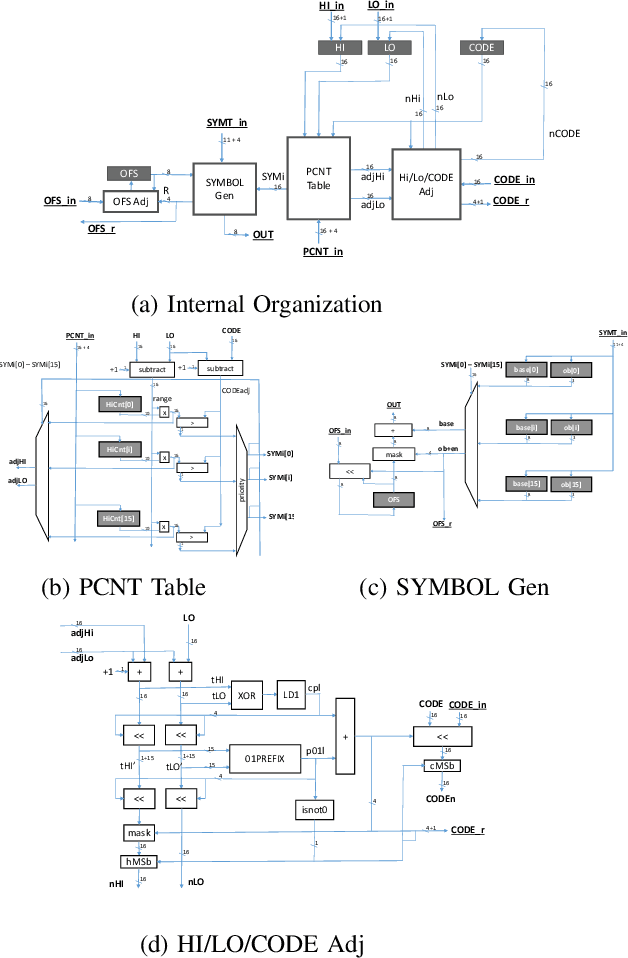
Data accesses between on- and off-chip memories account for a large fraction of overall energy consumption during inference with deep learning networks. We present APack, a simple and effective, lossless, off-chip memory compression technique for fixed-point quantized models. APack reduces data widths by exploiting the non-uniform value distribution in deep learning applications. APack can be used to increase the effective memory capacity, to reduce off-chip traffic, and/or to achieve the desired performance/energy targets while using smaller off-chip memories. APack builds upon arithmetic coding, encoding each value as an arithmetically coded variable length prefix, plus an offset. To maximize compression ratio a heuristic software algorithm partitions the value space into groups each sharing a common prefix. APack exploits memory access parallelism by using several, pipelined encoder/decoder units in parallel and keeps up with the high data bandwidth demands of deep learning. APack can be used with any machine learning accelerator. In the demonstrated configuration, APack is placed just before the off-chip memory controller so that he rest of the on-chip memory and compute units thus see the original data stream. We implemented the APack compressor and decompressor in Verilog and in a 65nm tech node demonstrating its performance and energy efficiency. Indicatively, APack reduces data footprint of weights and activations to 60% and 48% respectively on average over a wide set of 8-bit quantized models. It naturally adapts and compresses models that use even more aggressive quantization methods. When integrated with a Tensorcore-based accelerator, APack boosts the speedup and energy efficiency to 1.44X and 1.37X respectively.
FPRaker: A Processing Element For Accelerating Neural Network Training
Oct 15, 2020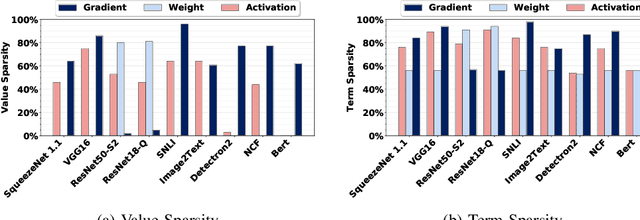
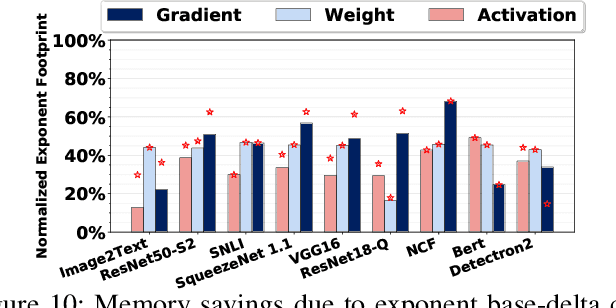
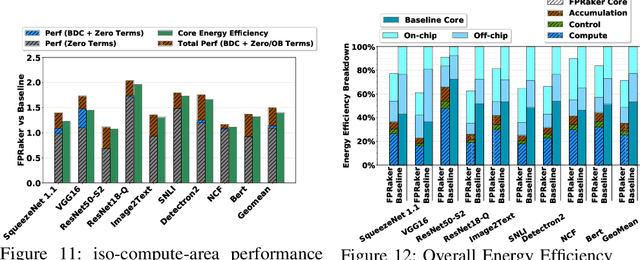
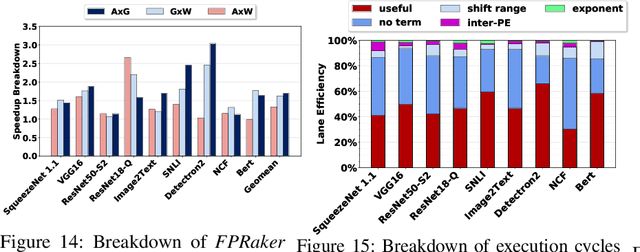
We present FPRaker, a processing element for composing training accelerators. FPRaker processes several floating-point multiply-accumulation operations concurrently and accumulates their result into a higher precision accumulator. FPRaker boosts performance and energy efficiency during training by taking advantage of the values that naturally appear during training. Specifically, it processes the significand of the operands of each multiply-accumulate as a series of signed powers of two. The conversion to this form is done on-the-fly. This exposes ineffectual work that can be skipped: values when encoded have few terms and some of them can be discarded as they would fall outside the range of the accumulator given the limited precision of floating-point. We demonstrate that FPRaker can be used to compose an accelerator for training and that it can improve performance and energy efficiency compared to using conventional floating-point units under ISO-compute area constraints. We also demonstrate that FPRaker delivers additional benefits when training incorporates pruning and quantization. Finally, we show that FPRaker naturally amplifies performance with training methods that use a different precision per layer.
TensorDash: Exploiting Sparsity to Accelerate Deep Neural Network Training and Inference
Sep 01, 2020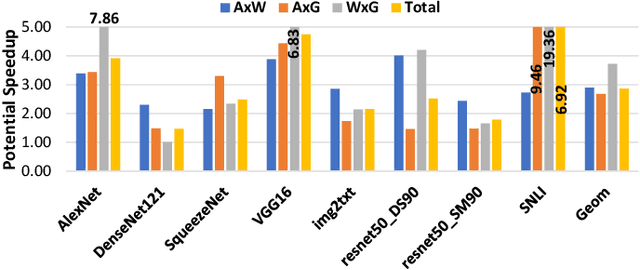
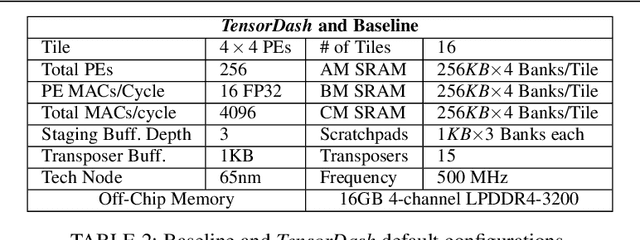
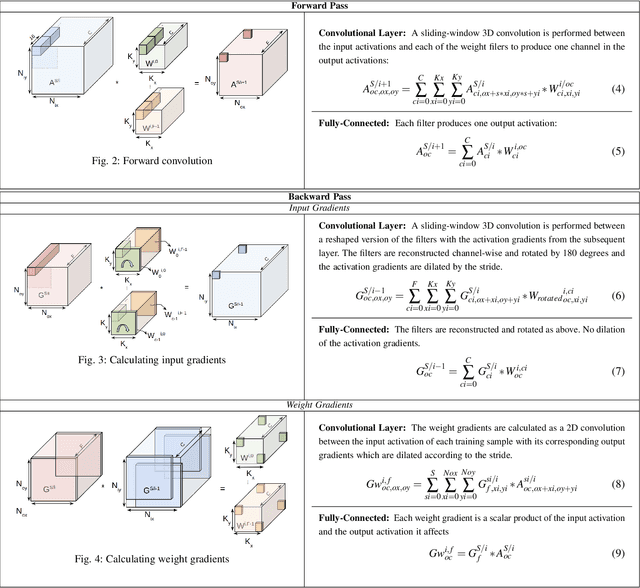
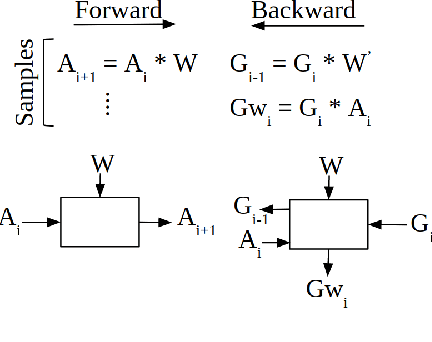
TensorDash is a hardware level technique for enabling data-parallel MAC units to take advantage of sparsity in their input operand streams. When used to compose a hardware accelerator for deep learning, TensorDash can speedup the training process while also increasing energy efficiency. TensorDash combines a low-cost, sparse input operand interconnect comprising an 8-input multiplexer per multiplier input, with an area-efficient hardware scheduler. While the interconnect allows a very limited set of movements per operand, the scheduler can effectively extract sparsity when it is present in the activations, weights or gradients of neural networks. Over a wide set of models covering various applications, TensorDash accelerates the training process by $1.95{\times}$ while being $1.89\times$ more energy-efficient, $1.6\times$ more energy efficient when taking on-chip and off-chip memory accesses into account. While TensorDash works with any datatype, we demonstrate it with both single-precision floating-point units and bfloat16.
Laconic Deep Learning Computing
May 10, 2018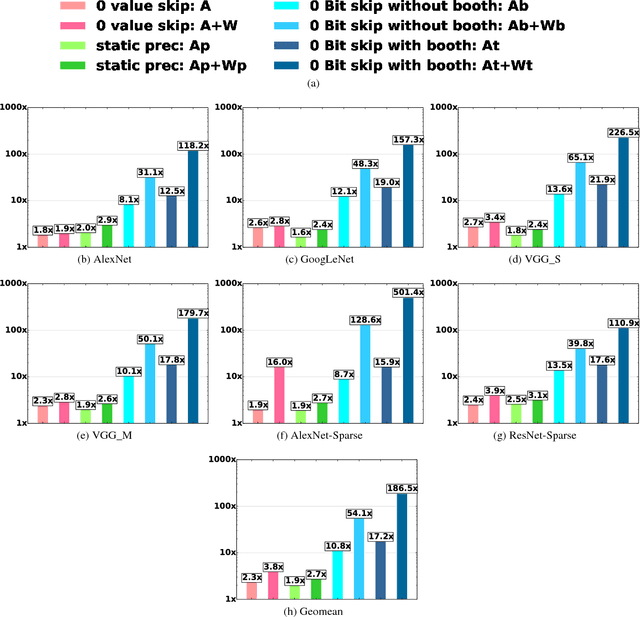
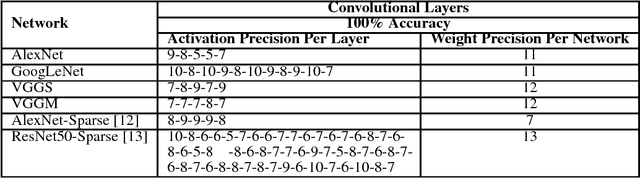
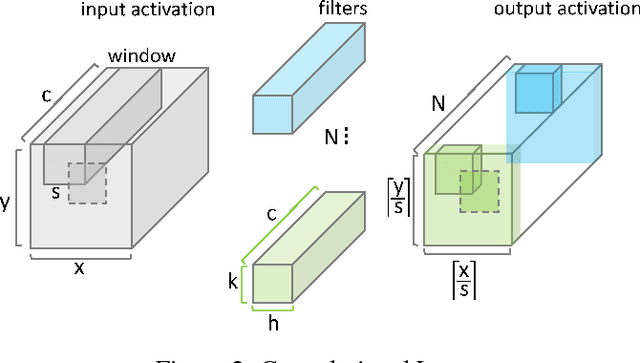
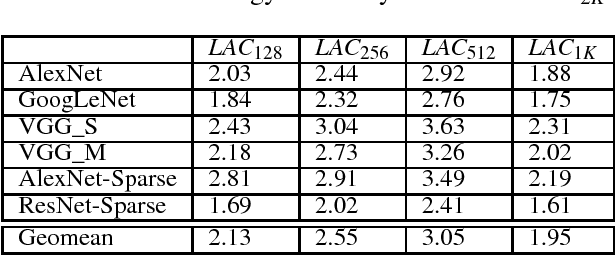
We motivate a method for transparently identifying ineffectual computations in unmodified Deep Learning models and without affecting accuracy. Specifically, we show that if we decompose multiplications down to the bit level the amount of work performed during inference for image classification models can be consistently reduced by two orders of magnitude. In the best case studied of a sparse variant of AlexNet, this approach can ideally reduce computation work by more than 500x. We present Laconic a hardware accelerator that implements this approach to improve execution time, and energy efficiency for inference with Deep Learning Networks. Laconic judiciously gives up some of the work reduction potential to yield a low-cost, simple, and energy efficient design that outperforms other state-of-the-art accelerators. For example, a Laconic configuration that uses a weight memory interface with just 128 wires outperforms a conventional accelerator with a 2K-wire weight memory interface by 2.3x on average while being 2.13x more energy efficient on average. A Laconic configuration that uses a 1K-wire weight memory interface, outperforms the 2K-wire conventional accelerator by 15.4x and is 1.95x more energy efficient. Laconic does not require but rewards advances in model design such as a reduction in precision, the use of alternate numeric representations that reduce the number of bits that are "1", or an increase in weight or activation sparsity.
Bit-Tactical: Exploiting Ineffectual Computations in Convolutional Neural Networks: Which, Why, and How
Mar 09, 2018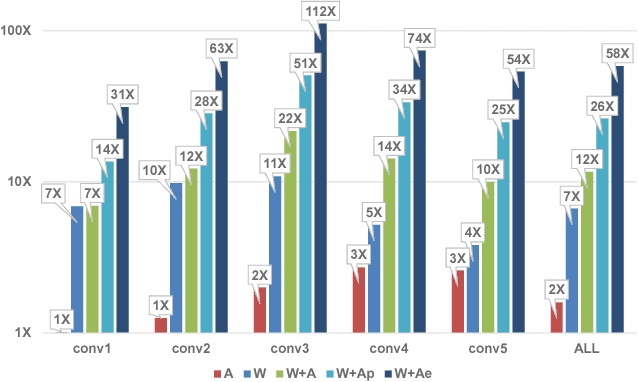
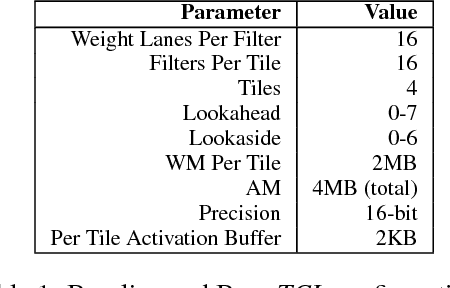
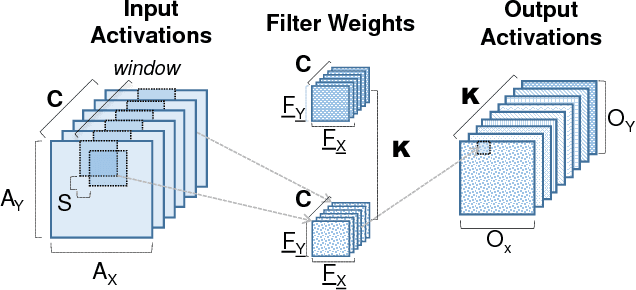
We show that, during inference with Convolutional Neural Networks (CNNs), more than 2x to $8x ineffectual work can be exposed if instead of targeting those weights and activations that are zero, we target different combinations of value stream properties. We demonstrate a practical application with Bit-Tactical (TCL), a hardware accelerator which exploits weight sparsity, per layer precision variability and dynamic fine-grain precision reduction for activations, and optionally the naturally occurring sparse effectual bit content of activations to improve performance and energy efficiency. TCL benefits both sparse and dense CNNs, natively supports both convolutional and fully-connected layers, and exploits properties of all activations to reduce storage, communication, and computation demands. While TCL does not require changes to the CNN to deliver benefits, it does reward any technique that would amplify any of the aforementioned weight and activation value properties. Compared to an equivalent data-parallel accelerator for dense CNNs, TCLp, a variant of TCL improves performance by 5.05x and is 2.98x more energy efficient while requiring 22% more area.