 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchrödinger's FP: Dynamic Adaptation of Floating-Point Containers for Deep Learning Training
Apr 28, 2022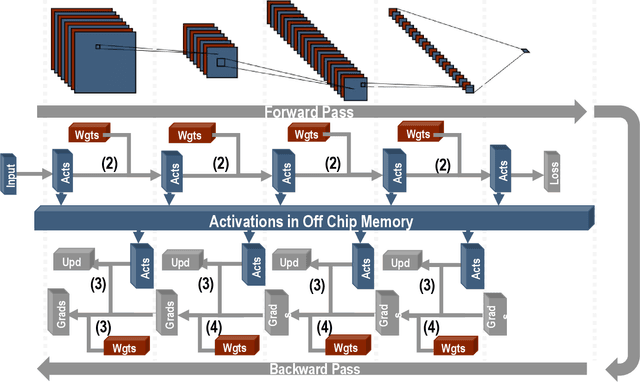
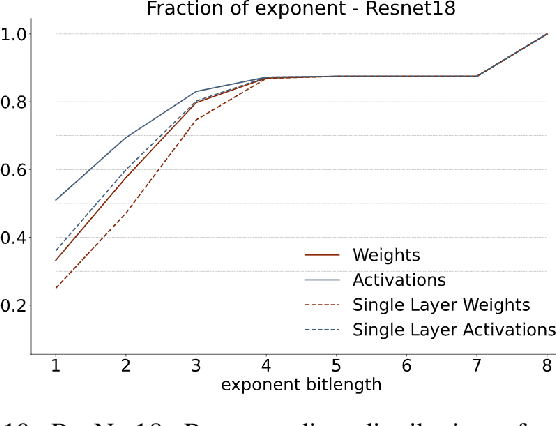
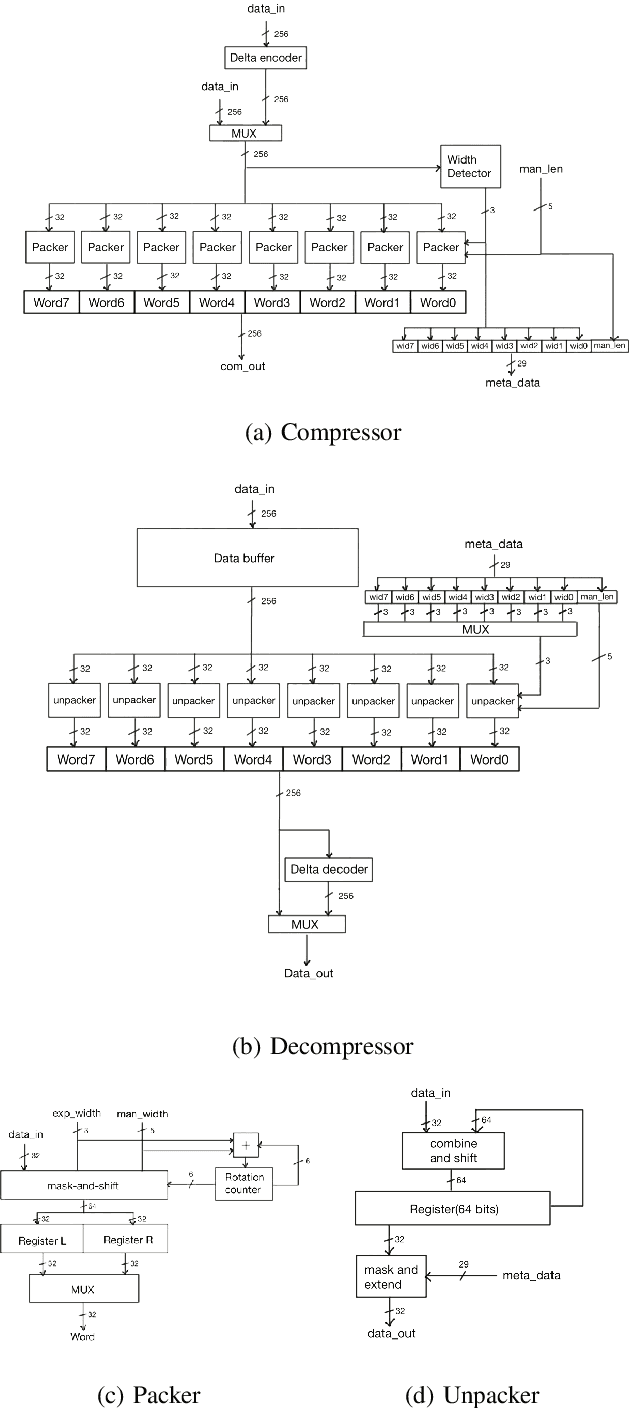
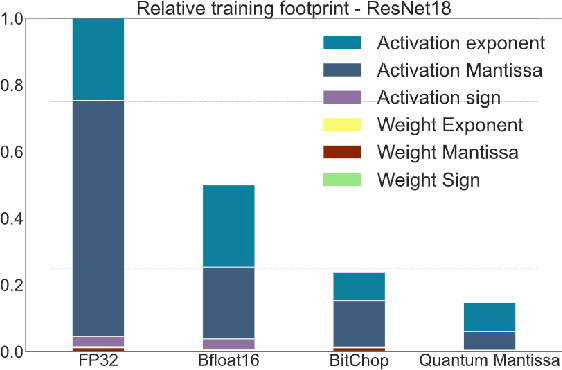
We introduce a software-hardware co-design approach to reduce memory traffic and footprint during training with BFloat16 or FP32 boosting energy efficiency and execution time performance. We introduce methods to dynamically adjust the size and format of the floating-point containers used to store activations and weights during training. The different value distributions lead us to different approaches for exponents and mantissas. Gecko exploits the favourable exponent distribution with a loss-less delta encoding approach to reduce the total exponent footprint by up to $58\%$ in comparison to a 32 bit floating point baseline. To content with the noisy mantissa distributions, we present two lossy methods to eliminate as many as possible least significant bits while not affecting accuracy. Quantum Mantissa, is a machine learning-first mantissa compression method that taps on training's gradient descent algorithm to also learn minimal mantissa bitlengths on a per-layer granularity, and obtain up to $92\%$ reduction in total mantissa footprint. Alternatively, BitChop observes changes in the loss function during training to adjust mantissa bit-length network-wide yielding a reduction of $81\%$ in footprint. Schr\"{o}dinger's FP implements hardware encoders/decoders that guided by Gecko/Quantum Mantissa or Gecko/BitChop transparently encode/decode values when transferring to/from off-chip memory boosting energy efficiency and reducing execution time.
Mokey: Enabling Narrow Fixed-Point Inference for Out-of-the-Box Floating-Point Transformer Models
Mar 23, 2022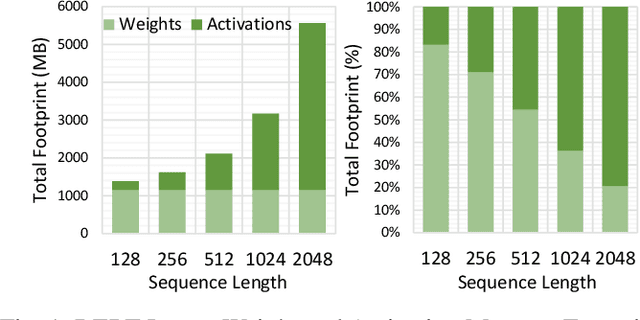
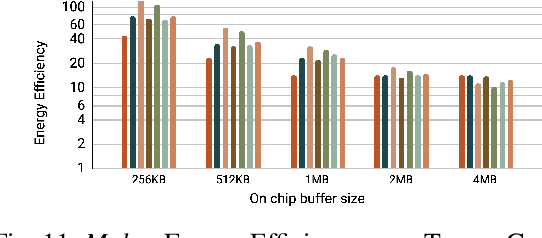
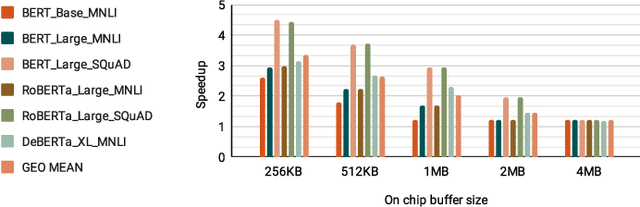
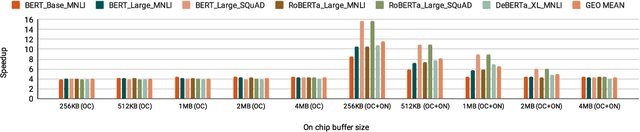
Increasingly larger and better Transformer models keep advancing state-of-the-art accuracy and capability for Natural Language Processing applications. These models demand more computational power, storage, and energy. Mokey reduces the footprint of state-of-the-art 32-bit or 16-bit floating-point transformer models by quantizing all values to 4-bit indexes into dictionaries of representative 16-bit fixed-point centroids. Mokey does not need fine-tuning, an essential feature as often the training resources or datasets are not available to many. Exploiting the range of values that naturally occur in transformer models, Mokey selects centroid values to also fit an exponential curve. This unique feature enables Mokey to replace the bulk of the original multiply-accumulate operations with narrow 3b fixed-point additions resulting in an area- and energy-efficient hardware accelerator design. Over a set of state-of-the-art transformer models, the Mokey accelerator delivers an order of magnitude improvements in energy efficiency over a Tensor Cores-based accelerator while improving performance by at least $4\times$ and as much as $15\times$ depending on the model and on-chip buffering capacity. Optionally, Mokey can be used as a memory compression assist for any other accelerator, transparently stashing wide floating-point or fixed-point activations or weights into narrow 4-bit indexes. Mokey proves superior to prior state-of-the-art quantization methods for Transformers.