 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBit-Tactical: Exploiting Ineffectual Computations in Convolutional Neural Networks: Which, Why, and How
Mar 09, 2018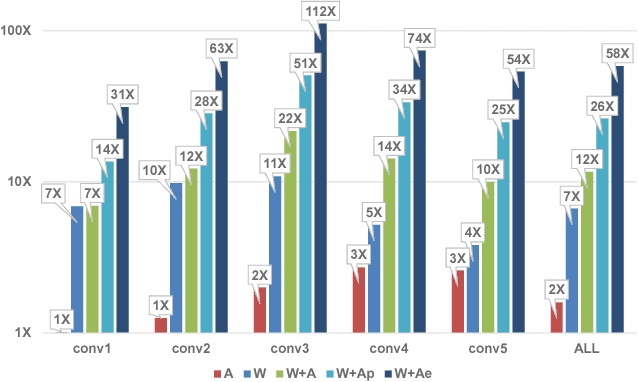
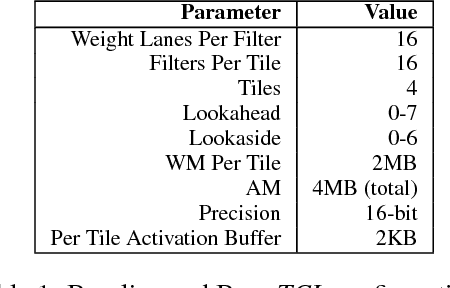
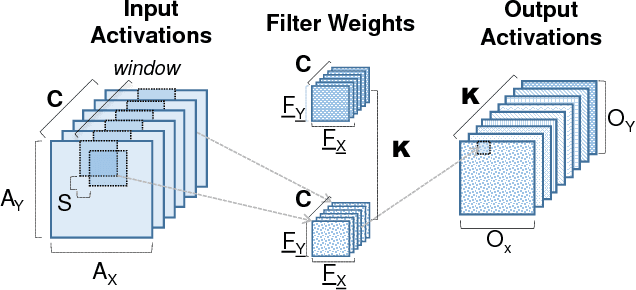
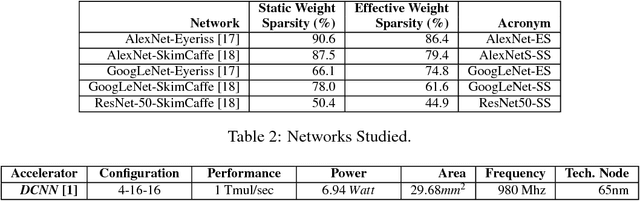
We show that, during inference with Convolutional Neural Networks (CNNs), more than 2x to $8x ineffectual work can be exposed if instead of targeting those weights and activations that are zero, we target different combinations of value stream properties. We demonstrate a practical application with Bit-Tactical (TCL), a hardware accelerator which exploits weight sparsity, per layer precision variability and dynamic fine-grain precision reduction for activations, and optionally the naturally occurring sparse effectual bit content of activations to improve performance and energy efficiency. TCL benefits both sparse and dense CNNs, natively supports both convolutional and fully-connected layers, and exploits properties of all activations to reduce storage, communication, and computation demands. While TCL does not require changes to the CNN to deliver benefits, it does reward any technique that would amplify any of the aforementioned weight and activation value properties. Compared to an equivalent data-parallel accelerator for dense CNNs, TCLp, a variant of TCL improves performance by 5.05x and is 2.98x more energy efficient while requiring 22% more area.
Investigating the Effects of Dynamic Precision Scaling on Neural Network Training
Jan 25, 2018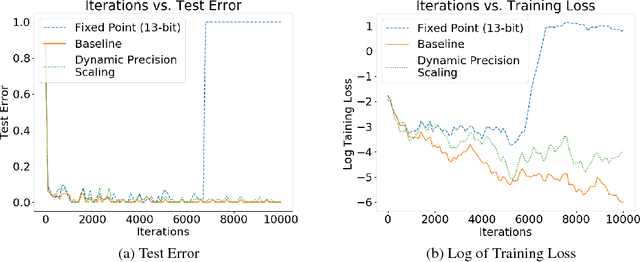
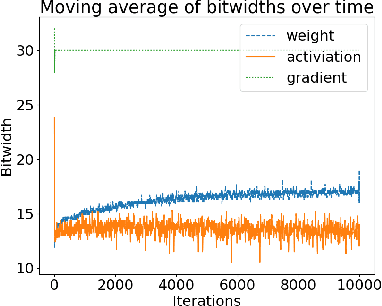
Training neural networks is a time- and compute-intensive operation. This is mainly due to the large amount of floating point tensor operations that are required during training. These constraints limit the scope of design space explorations (in terms of hyperparameter search) for data scientists and researchers. Recent work has explored the possibility of reducing the numerical precision used to represent parameters, activations, and gradients during neural network training as a way to reduce the computational cost of training (and thus reducing training time). In this paper we develop a novel dynamic precision scaling scheme and evaluate its performance, comparing it to previous works. Using stochastic fixed-point rounding, a quantization-error based scaling scheme, and dynamic bit-widths during training, we achieve 98.8% test accuracy on the MNIST dataset using an average bit-width of just 16 bits for weights and 14 bits for activations. This beats the previous state-of-the-art dynamic bit-width precision scaling algorithm.