 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPRed: Making Typical Activation Values Matter In Deep Learning Computing
May 15, 2018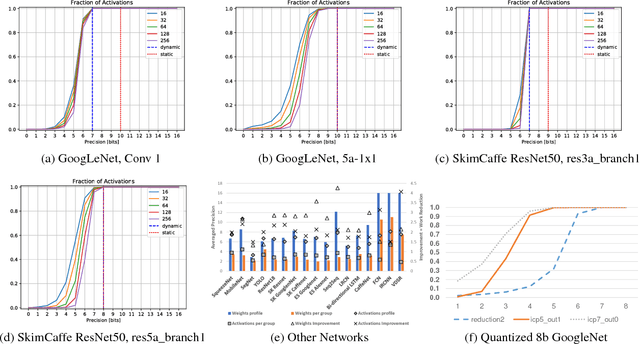

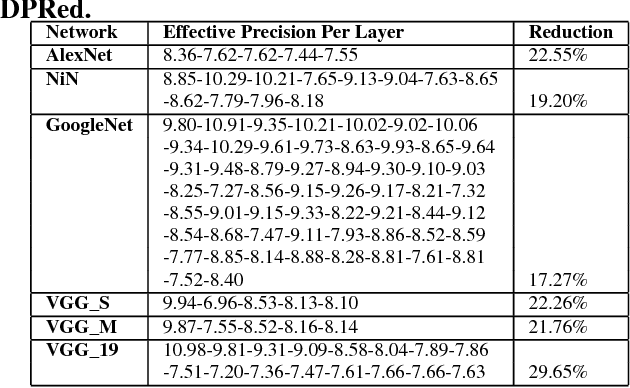

We show that selecting a fixed precision for all values in Convolutional Neural Networks, even if that precision is different per layer, amounts to worst case design. We show that much lower precisions can be used if we could target the common case instead by tailoring the precision at a much finer granularity than that of a layer. While this observation may not be surprising, to date no design takes advantage of it in practice. We propose Dynamic Prediction Reduction (DPRed), where hardware on-the-fly detects the precision activations need at a much finer granularity than a whole layer. Further we encode activations and weights using the respective per group dynamically and statically detected precisions to reduce off- and on-chip storage and communication. We demonstrate a practical implementation of DPRed with DPRed Stripes (DPRS), a data-parallel hardware accelerator that adjusts precision on-the-fly to accommodate the values of the activations it processes concurrently. DPRS accelerates convolutional layers and executes unmodified convolutional neural networks. Ignoring offchip communication, DPRS is 2.61x faster and 1.84x more energy efficient than a fixed-precision accelerator for a set of convolutional neural networks. We further extend DPRS to exploit activation and weight precisions for fully-connected layers. The enhanced design improves average performance and energy efficiency respectively by 2.59x and 1.19x over the fixed-precision accelerator for a broader set of neural networks. Finally, we consider a lower cost variant that supports only even precision widths which offers better energy efficiency. Taking into account off-chip communication, DPRed compression reduces off-chip traffic to nearly 35% on average compared to no compression making it possible to sustain higher performance for a given off-chip memory interface while also boosting energy efficiency.
Bit-Tactical: Exploiting Ineffectual Computations in Convolutional Neural Networks: Which, Why, and How
Mar 09, 2018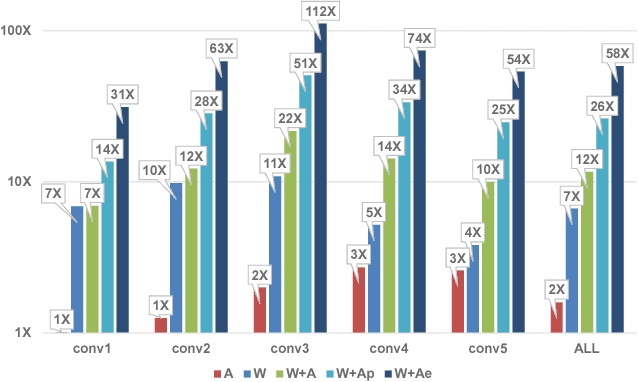
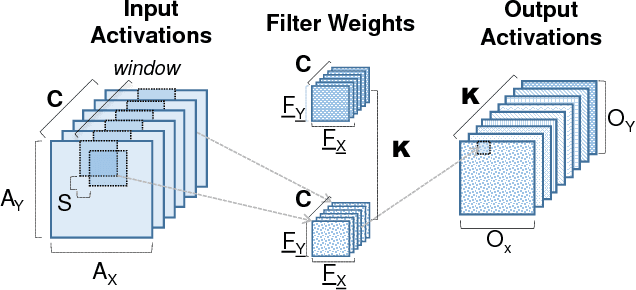
We show that, during inference with Convolutional Neural Networks (CNNs), more than 2x to $8x ineffectual work can be exposed if instead of targeting those weights and activations that are zero, we target different combinations of value stream properties. We demonstrate a practical application with Bit-Tactical (TCL), a hardware accelerator which exploits weight sparsity, per layer precision variability and dynamic fine-grain precision reduction for activations, and optionally the naturally occurring sparse effectual bit content of activations to improve performance and energy efficiency. TCL benefits both sparse and dense CNNs, natively supports both convolutional and fully-connected layers, and exploits properties of all activations to reduce storage, communication, and computation demands. While TCL does not require changes to the CNN to deliver benefits, it does reward any technique that would amplify any of the aforementioned weight and activation value properties. Compared to an equivalent data-parallel accelerator for dense CNNs, TCLp, a variant of TCL improves performance by 5.05x and is 2.98x more energy efficient while requiring 22% more area.
Tartan: Accelerating Fully-Connected and Convolutional Layers in Deep Learning Networks by Exploiting Numerical Precision Variability
Jul 27, 2017
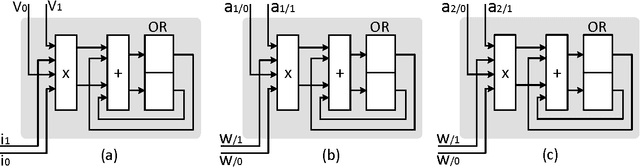
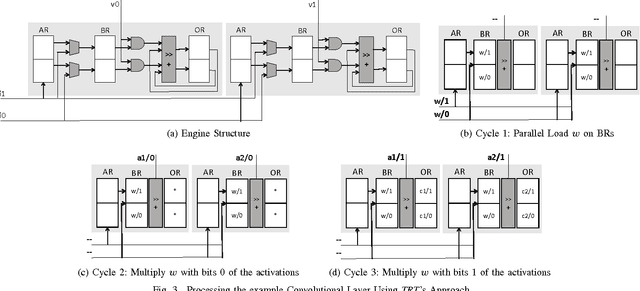
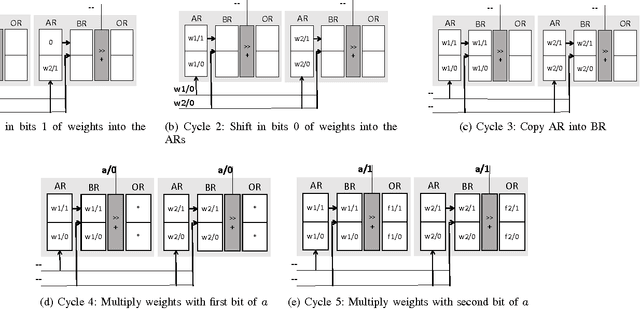
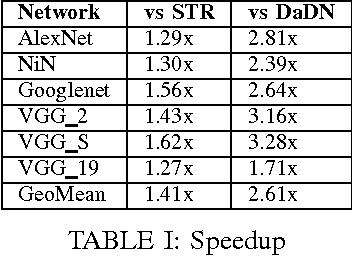
Tartan (TRT), a hardware accelerator for inference with Deep Neural Networks (DNNs), is presented and evaluated on Convolutional Neural Networks. TRT exploits the variable per layer precision requirements of DNNs to deliver execution time that is proportional to the precision p in bits used per layer for convolutional and fully-connected layers. Prior art has demonstrated an accelerator with the same execution performance only for convolutional layers. Experiments on image classification CNNs show that on average across all networks studied, TRT outperforms a state-of-the-art bit-parallel accelerator by 1:90x without any loss in accuracy while it is 1:17x more energy efficient. TRT requires no network retraining while it enables trading off accuracy for additional improvements in execution performance and energy efficiency. For example, if a 1% relative loss in accuracy is acceptable, TRT is on average 2:04x faster and 1:25x more energy efficient than a conventional bit-parallel accelerator. A Tartan configuration that processes 2-bits at time, requires less area than the 1-bit configuration, improves efficiency to 1:24x over the bit-parallel baseline while being 73% faster for convolutional layers and 60% faster for fully-connected layers is also presented.
Dynamic Stripes: Exploiting the Dynamic Precision Requirements of Activation Values in Neural Networks
Jun 01, 2017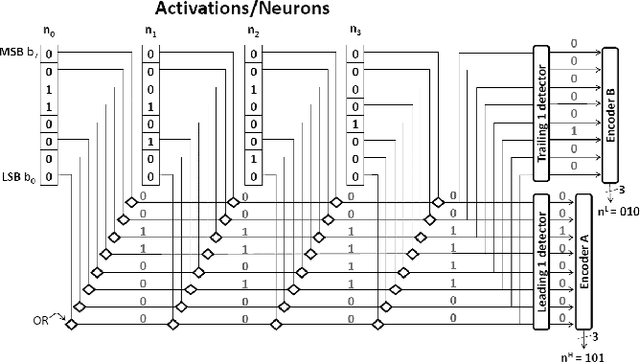
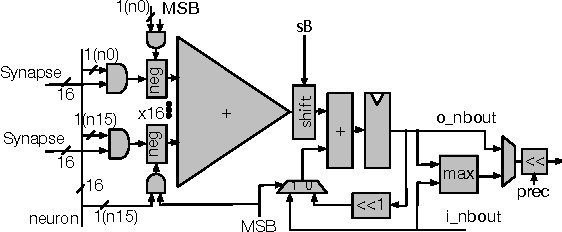
Stripes is a Deep Neural Network (DNN) accelerator that uses bit-serial computation to offer performance that is proportional to the fixed-point precision of the activation values. The fixed-point precisions are determined a priori using profiling and are selected at a per layer granularity. This paper presents Dynamic Stripes, an extension to Stripes that detects precision variance at runtime and at a finer granularity. This extra level of precision reduction increases performance by 41% over Stripes.
Cnvlutin2: Ineffectual-Activation-and-Weight-Free Deep Neural Network Computing
Apr 29, 2017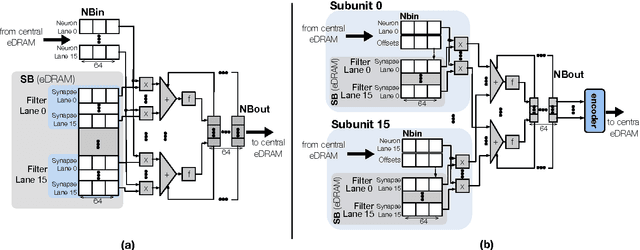



We discuss several modifications and extensions over the previous proposed Cnvlutin (CNV) accelerator for convolutional and fully-connected layers of Deep Learning Network. We first describe different encodings of the activations that are deemed ineffectual. The encodings have different memory overhead and energy characteristics. We propose using a level of indirection when accessing activations from memory to reduce their memory footprint by storing only the effectual activations. We also present a modified organization that detects the activations that are deemed as ineffectual while fetching them from memory. This is different than the original design that instead detected them at the output of the preceding layer. Finally, we present an extended CNV that can also skip ineffectual weights.