 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPRed: Making Typical Activation Values Matter In Deep Learning Computing
Paper and Code
May 15, 2018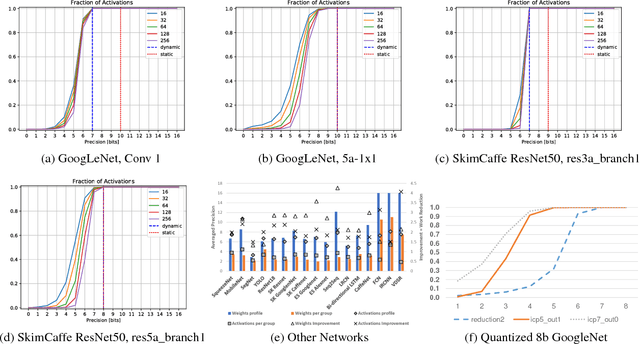

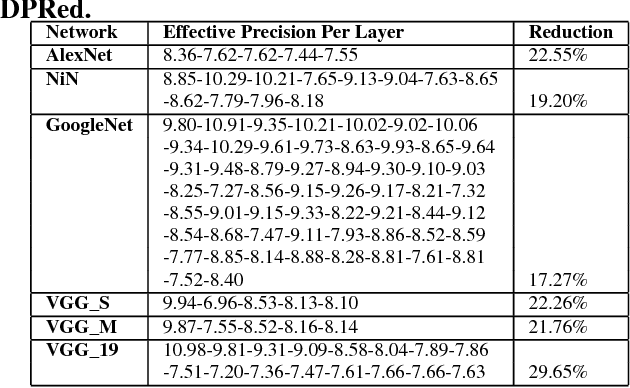

We show that selecting a fixed precision for all values in Convolutional Neural Networks, even if that precision is different per layer, amounts to worst case design. We show that much lower precisions can be used if we could target the common case instead by tailoring the precision at a much finer granularity than that of a layer. While this observation may not be surprising, to date no design takes advantage of it in practice. We propose Dynamic Prediction Reduction (DPRed), where hardware on-the-fly detects the precision activations need at a much finer granularity than a whole layer. Further we encode activations and weights using the respective per group dynamically and statically detected precisions to reduce off- and on-chip storage and communication. We demonstrate a practical implementation of DPRed with DPRed Stripes (DPRS), a data-parallel hardware accelerator that adjusts precision on-the-fly to accommodate the values of the activations it processes concurrently. DPRS accelerates convolutional layers and executes unmodified convolutional neural networks. Ignoring offchip communication, DPRS is 2.61x faster and 1.84x more energy efficient than a fixed-precision accelerator for a set of convolutional neural networks. We further extend DPRS to exploit activation and weight precisions for fully-connected layers. The enhanced design improves average performance and energy efficiency respectively by 2.59x and 1.19x over the fixed-precision accelerator for a broader set of neural networks. Finally, we consider a lower cost variant that supports only even precision widths which offers better energy efficiency. Taking into account off-chip communication, DPRed compression reduces off-chip traffic to nearly 35% on average compared to no compression making it possible to sustain higher performance for a given off-chip memory interface while also boosting energy efficiency.