 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO-LLaMA: Efficient Caching for High-Performance LLaMA Training
May 22, 2025This paper introduces ECHO-LLaMA, an efficient LLaMA architecture designed to improve both the training speed and inference throughput of LLaMA architectures while maintaining its learning capacity. ECHO-LLaMA transforms LLaMA models into shared KV caching across certain layers, significantly reducing KV computational complexity while maintaining or improving language performance. Experimental results demonstrate that ECHO-LLaMA achieves up to 77\% higher token-per-second throughput during training, up to 16\% higher Model FLOPs Utilization (MFU), and up to 14\% lower loss when trained on an equal number of tokens. Furthermore, on the 1.1B model, ECHO-LLaMA delivers approximately 7\% higher test-time throughput compared to the baseline. By introducing a computationally efficient adaptation mechanism, ECHO-LLaMA offers a scalable and cost-effective solution for pretraining and finetuning large language models, enabling faster and more resource-efficient training without compromising performance.
SkipViT: Speeding Up Vision Transformers with a Token-Level Skip Connection
Jan 27, 2024Vision transformers are known to be more computationally and data-intensive than CNN models. These transformer models such as ViT, require all the input image tokens to learn the relationship among them. However, many of these tokens are not informative and may contain irrelevant information such as unrelated background or unimportant scenery. These tokens are overlooked by the multi-head self-attention (MHSA), resulting in many redundant and unnecessary computations in MHSA and the feed-forward network (FFN). In this work, we propose a method to optimize the amount of unnecessary interactions between unimportant tokens by separating and sending them through a different low-cost computational path. Our method does not add any parameters to the ViT model and aims to find the best trade-off between training throughput and achieving a 0% loss in the Top-1 accuracy of the final model. Our experimental results on training ViT-small from scratch show that SkipViT is capable of effectively dropping 55% of the tokens while gaining more than 13% training throughput and maintaining classification accuracy at the level of the baseline model on Huawei Ascend910A.
SwiftLearn: A Data-Efficient Training Method of Deep Learning Models using Importance Sampling
Nov 25, 2023
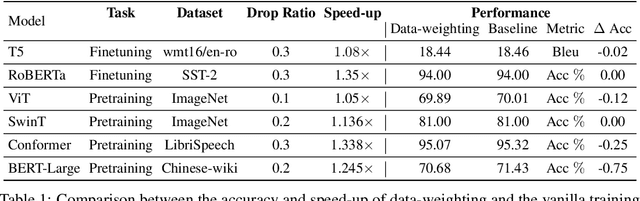

In this paper, we present SwiftLearn, a data-efficient approach to accelerate training of deep learning models using a subset of data samples selected during the warm-up stages of training. This subset is selected based on an importance criteria measured over the entire dataset during warm-up stages, aiming to preserve the model performance with fewer examples during the rest of training. The importance measure we propose could be updated during training every once in a while, to make sure that all of the data samples have a chance to return to the training loop if they show a higher importance. The model architecture is unchanged but since the number of data samples controls the number of forward and backward passes during training, we can reduce the training time by reducing the number of training samples used in each epoch of training. Experimental results on a variety of CV and NLP models during both pretraining and finetuning show that the model performance could be preserved while achieving a significant speed-up during training. More specifically, BERT finetuning on GLUE benchmark shows that almost 90% of the data can be dropped achieving an end-to-end average speedup of 3.36x while keeping the average accuracy drop less than 0.92%.
GQKVA: Efficient Pre-training of Transformers by Grouping Queries, Keys, and Values
Nov 06, 2023Massive transformer-based models face several challenges, including slow and computationally intensive pre-training and over-parametrization. This paper addresses these challenges by proposing a versatile method called GQKVA, which generalizes query, key, and value grouping techniques. GQKVA is designed to speed up transformer pre-training while reducing the model size. Our experiments with various GQKVA variants highlight a clear trade-off between performance and model size, allowing for customized choices based on resource and time limitations. Our findings also indicate that the conventional multi-head attention approach is not always the best choice, as there are lighter and faster alternatives available. We tested our method on ViT, which achieved an approximate 0.3% increase in accuracy while reducing the model size by about 4% in the task of image classification. Additionally, our most aggressive model reduction experiment resulted in a reduction of approximately 15% in model size, with only around a 1% drop in accuracy.
Improving Resnet-9 Generalization Trained on Small Datasets
Sep 07, 2023This paper presents our proposed approach that won the first prize at the ICLR competition on Hardware Aware Efficient Training. The challenge is to achieve the highest possible accuracy in an image classification task in less than 10 minutes. The training is done on a small dataset of 5000 images picked randomly from CIFAR-10 dataset. The evaluation is performed by the competition organizers on a secret dataset with 1000 images of the same size. Our approach includes applying a series of technique for improving the generalization of ResNet-9 including: sharpness aware optimization, label smoothing, gradient centralization, input patch whitening as well as metalearning based training. Our experiments show that the ResNet-9 can achieve the accuracy of 88% while trained only on a 10% subset of CIFAR-10 dataset in less than 10 minuets
FPRaker: A Processing Element For Accelerating Neural Network Training
Oct 15, 2020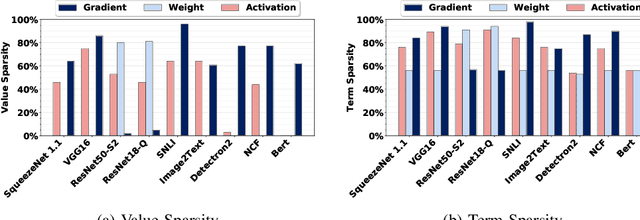
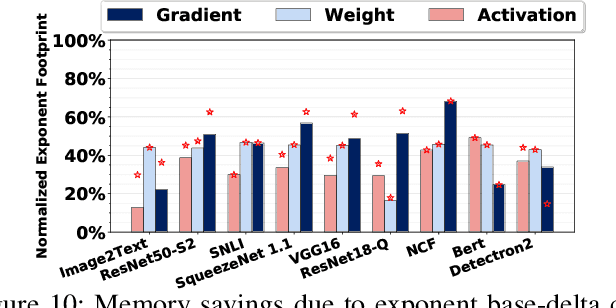
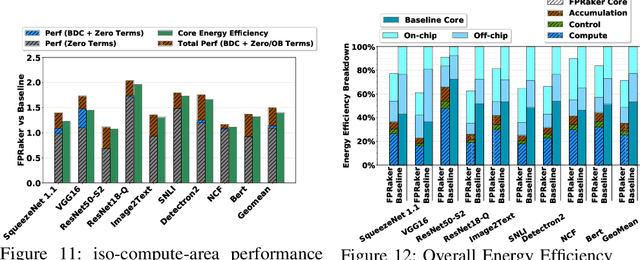
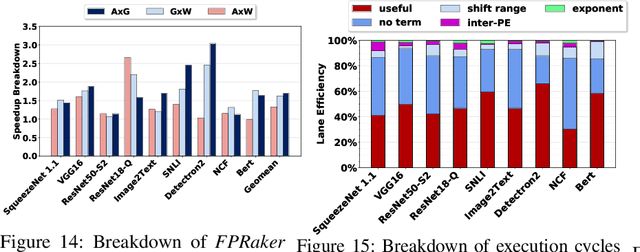
We present FPRaker, a processing element for composing training accelerators. FPRaker processes several floating-point multiply-accumulation operations concurrently and accumulates their result into a higher precision accumulator. FPRaker boosts performance and energy efficiency during training by taking advantage of the values that naturally appear during training. Specifically, it processes the significand of the operands of each multiply-accumulate as a series of signed powers of two. The conversion to this form is done on-the-fly. This exposes ineffectual work that can be skipped: values when encoded have few terms and some of them can be discarded as they would fall outside the range of the accumulator given the limited precision of floating-point. We demonstrate that FPRaker can be used to compose an accelerator for training and that it can improve performance and energy efficiency compared to using conventional floating-point units under ISO-compute area constraints. We also demonstrate that FPRaker delivers additional benefits when training incorporates pruning and quantization. Finally, we show that FPRaker naturally amplifies performance with training methods that use a different precision per layer.
TensorDash: Exploiting Sparsity to Accelerate Deep Neural Network Training and Inference
Sep 01, 2020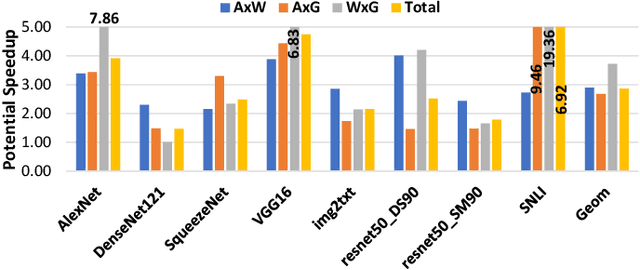
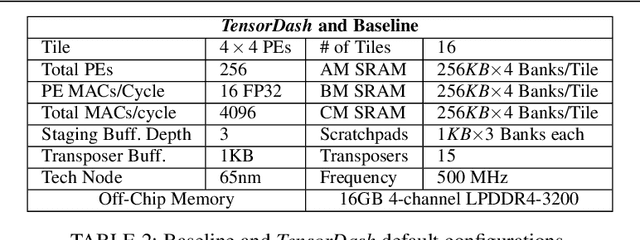
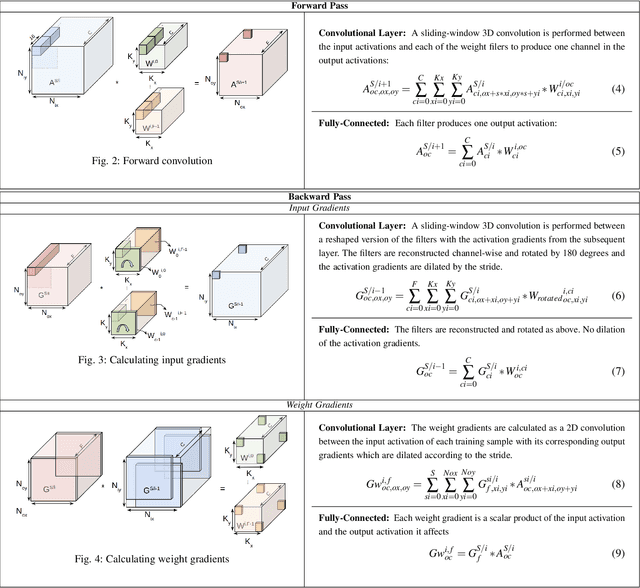
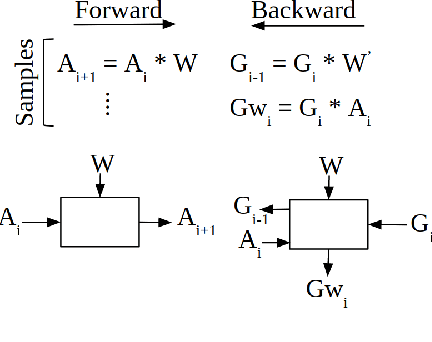
TensorDash is a hardware level technique for enabling data-parallel MAC units to take advantage of sparsity in their input operand streams. When used to compose a hardware accelerator for deep learning, TensorDash can speedup the training process while also increasing energy efficiency. TensorDash combines a low-cost, sparse input operand interconnect comprising an 8-input multiplexer per multiplier input, with an area-efficient hardware scheduler. While the interconnect allows a very limited set of movements per operand, the scheduler can effectively extract sparsity when it is present in the activations, weights or gradients of neural networks. Over a wide set of models covering various applications, TensorDash accelerates the training process by $1.95{\times}$ while being $1.89\times$ more energy-efficient, $1.6\times$ more energy efficient when taking on-chip and off-chip memory accesses into account. While TensorDash works with any datatype, we demonstrate it with both single-precision floating-point units and bfloat16.