 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Hybrid Parallelism for Large Language Models: Comparative Study and System Design Guide
Feb 09, 2026With the rapid growth of large language models (LLMs), a wide range of methods have been developed to distribute computation and memory across hardware devices for efficient training and inference. While existing surveys provide descriptive overviews of these techniques, systematic analysis of their benefits and trade offs and how such insights can inform principled methodology for designing optimal distributed systems remain limited. This paper offers a comprehensive review of collective operations and distributed parallel strategies, complemented by mathematical formulations to deepen theoretical understanding. We further examine hybrid parallelization designs, emphasizing communication computation overlap across different stages of model deployment, including both training and inference. Recent advances in automated search for optimal hybrid parallelization strategies using cost models are also discussed. Moreover, we present case studies with mainstream architecture categories to reveal empirical insights to guide researchers and practitioners in parallelism strategy selection. Finally, we highlight open challenges and limitations of current LLM training paradigms and outline promising directions for the next generation of large scale model development.
EPAS: Efficient Training with Progressive Activation Sharing
Jan 27, 2026We present a novel method for Efficient training with Progressive Activation Sharing (EPAS). This method bridges progressive training paradigm with the phenomenon of redundant QK (or KV ) activations across deeper layers of transformers. EPAS gradually grows a sharing region during training by switching decoder layers to activation sharing mode. This results in throughput increase due to reduced compute. To utilize deeper layer redundancy, the sharing region starts from the deep end of the model and grows towards the shallow end. The EPAS trained models allow for variable region lengths of activation sharing for different compute budgets during inference. Empirical evaluations with QK activation sharing in LLaMA models ranging from 125M to 7B parameters show up to an 11.1% improvement in training throughput and up to a 29% improvement in inference throughput while maintaining similar loss curve to the baseline models. Furthermore, applying EPAS in continual pretraining to transform TinyLLaMA into an attention-sharing model yields up to a 10% improvement in average accuracy over state-of-the-art methods, emphasizing the significance of progressive training in cross layer activation sharing models.
FLOP-Efficient Training: Early Stopping Based on Test-Time Compute Awareness
Jan 04, 2026Scaling training compute, measured in FLOPs, has long been shown to improve the accuracy of large language models, yet training remains resource-intensive. Prior work shows that increasing test-time compute (TTC)-for example through iterative sampling-can allow smaller models to rival or surpass much larger ones at lower overall cost. We introduce TTC-aware training, where an intermediate checkpoint and a corresponding TTC configuration can together match or exceed the accuracy of a fully trained model while requiring substantially fewer training FLOPs. Building on this insight, we propose an early stopping algorithm that jointly selects a checkpoint and TTC configuration to minimize training compute without sacrificing accuracy. To make this practical, we develop an efficient TTC evaluation method that avoids exhaustive search, and we formalize a break-even bound that identifies when increased inference compute compensates for reduced training compute. Experiments demonstrate up to 92\% reductions in training FLOPs while maintaining and sometimes remarkably improving accuracy. These results highlight a new perspective for balancing training and inference compute in model development, enabling faster deployment cycles and more frequent model refreshes. Codes will be publicly released.
Bayesian Mixture of Experts For Large Language Models
Nov 12, 2025We present Bayesian Mixture of Experts (Bayesian-MoE), a post-hoc uncertainty estimation framework for fine-tuned large language models (LLMs) based on Mixture-of-Experts architectures. Our method applies a structured Laplace approximation to the second linear layer of each expert, enabling calibrated uncertainty estimation without modifying the original training procedure or introducing new parameters. Unlike prior approaches, which apply Bayesian inference to added adapter modules, Bayesian-MoE directly targets the expert pathways already present in MoE models, leveraging their modular design for tractable block-wise posterior estimation. We use Kronecker-factored low-rank approximations to model curvature and derive scalable estimates of predictive uncertainty and marginal likelihood. Experiments on common-sense reasoning benchmarks with Qwen1.5-MoE and DeepSeek-MoE demonstrate that Bayesian-MoE improves both expected calibration error (ECE) and negative log-likelihood (NLL) over baselines, confirming its effectiveness for reliable downstream decision-making.
Balancing Computation Load and Representation Expressivity in Parallel Hybrid Neural Networks
May 26, 2025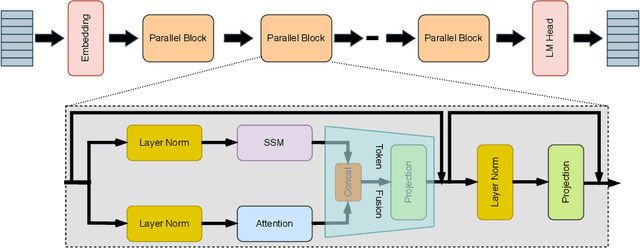
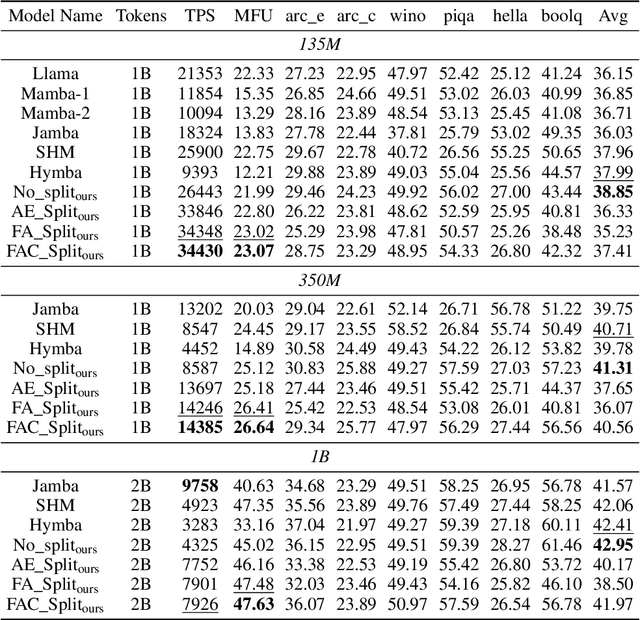
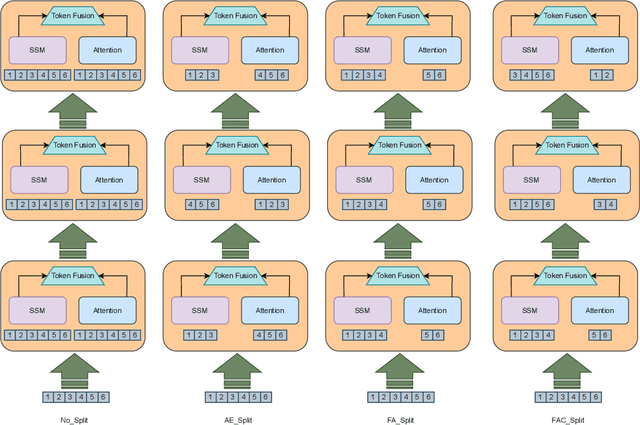
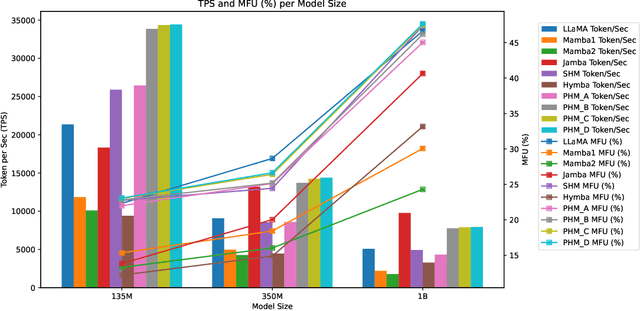
Attention and State-Space Models (SSMs) when combined in a hybrid network in sequence or in parallel provide complementary strengths. In a hybrid sequential pipeline they alternate between applying a transformer to the input and then feeding its output into a SSM. This results in idle periods in the individual components increasing end-to-end latency and lowering throughput caps. In the parallel hybrid architecture, the transformer operates independently in parallel with the SSM, and these pairs are cascaded, with output from one pair forming the input to the next. Two issues are (i) creating an expressive knowledge representation with the inherently divergent outputs from these separate branches, and (ii) load balancing the computation between these parallel branches, while maintaining representation fidelity. In this work we present FlowHN, a novel parallel hybrid network architecture that accommodates various strategies for load balancing, achieved through appropriate distribution of input tokens between the two branches. Two innovative differentiating factors in FlowHN include a FLOP aware dynamic token split between the attention and SSM branches yielding efficient balance in compute load, and secondly, a method to fuse the highly divergent outputs from individual branches for enhancing representation expressivity. Together they enable much better token processing speeds, avoid bottlenecks, and at the same time yield significantly improved accuracy as compared to other competing works. We conduct comprehensive experiments on autoregressive language modeling for models with 135M, 350M, and 1B parameters. FlowHN outperforms sequential hybrid models and its parallel counterpart, achieving up to 4* higher Tokens per Second (TPS) and 2* better Model FLOPs Utilization (MFU).
Continuous Self-Improvement of Large Language Models by Test-time Training with Verifier-Driven Sample Selection
May 26, 2025Learning to adapt pretrained language models to unlabeled, out-of-distribution data is a critical challenge, as models often falter on structurally novel reasoning tasks even while excelling within their training distribution. We introduce a new framework called VDS-TTT - Verifier-Driven Sample Selection for Test-Time Training to efficiently address this. We use a learned verifier to score a pool of generated responses and select only from high ranking pseudo-labeled examples for fine-tuned adaptation. Specifically, for each input query our LLM generates N candidate answers; the verifier assigns a reliability score to each, and the response with the highest confidence and above a fixed threshold is paired with its query for test-time training. We fine-tune only low-rank LoRA adapter parameters, ensuring adaptation efficiency and fast convergence. Our proposed self-supervised framework is the first to synthesize verifier driven test-time training data for continuous self-improvement of the model. Experiments across three diverse benchmarks and three state-of-the-art LLMs demonstrate that VDS-TTT yields up to a 32.29% relative improvement over the base model and a 6.66% gain compared to verifier-based methods without test-time training, highlighting its effectiveness and efficiency for on-the-fly large language model adaptation.
ECHO-LLaMA: Efficient Caching for High-Performance LLaMA Training
May 22, 2025This paper introduces ECHO-LLaMA, an efficient LLaMA architecture designed to improve both the training speed and inference throughput of LLaMA architectures while maintaining its learning capacity. ECHO-LLaMA transforms LLaMA models into shared KV caching across certain layers, significantly reducing KV computational complexity while maintaining or improving language performance. Experimental results demonstrate that ECHO-LLaMA achieves up to 77\% higher token-per-second throughput during training, up to 16\% higher Model FLOPs Utilization (MFU), and up to 14\% lower loss when trained on an equal number of tokens. Furthermore, on the 1.1B model, ECHO-LLaMA delivers approximately 7\% higher test-time throughput compared to the baseline. By introducing a computationally efficient adaptation mechanism, ECHO-LLaMA offers a scalable and cost-effective solution for pretraining and finetuning large language models, enabling faster and more resource-efficient training without compromising performance.
Accelerating the Low-Rank Decomposed Models
Jul 24, 2024
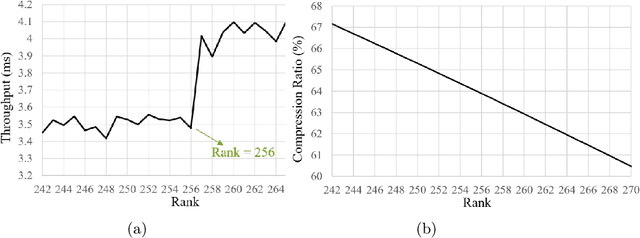
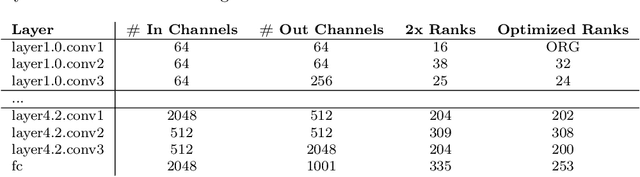
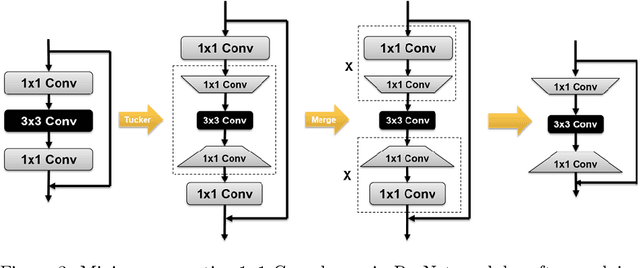
Tensor decomposition is a mathematically supported technique for data compression. It consists of applying some kind of a Low Rank Decomposition technique on the tensors or matrices in order to reduce the redundancy of the data. However, it is not a popular technique for compressing the AI models duo to the high number of new layers added to the architecture after decomposition. Although the number of parameters could shrink significantly, it could result in the model be more than twice deeper which could add some latency to the training or inference. In this paper, we present a comprehensive study about how to modify low rank decomposition technique in AI models so that we could benefit from both high accuracy and low memory consumption as well as speeding up the training and inference
Is 3D Convolution with 5D Tensors Really Necessary for Video Analysis?
Jul 23, 2024


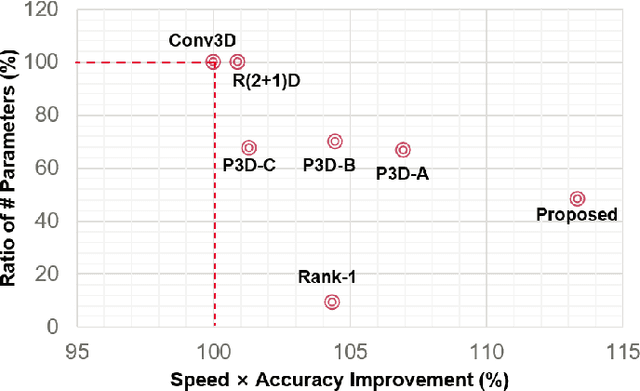
In this paper, we present a comprehensive study and propose several novel techniques for implementing 3D convolutional blocks using 2D and/or 1D convolutions with only 4D and/or 3D tensors. Our motivation is that 3D convolutions with 5D tensors are computationally very expensive and they may not be supported by some of the edge devices used in real-time applications such as robots. The existing approaches mitigate this by splitting the 3D kernels into spatial and temporal domains, but they still use 3D convolutions with 5D tensors in their implementations. We resolve this issue by introducing some appropriate 4D/3D tensor reshaping as well as new combination techniques for spatial and temporal splits. The proposed implementation methods show significant improvement both in terms of efficiency and accuracy. The experimental results confirm that the proposed spatio-temporal processing structure outperforms the original model in terms of speed and accuracy using only 4D tensors with fewer parameters.
SkipViT: Speeding Up Vision Transformers with a Token-Level Skip Connection
Jan 27, 2024Vision transformers are known to be more computationally and data-intensive than CNN models. These transformer models such as ViT, require all the input image tokens to learn the relationship among them. However, many of these tokens are not informative and may contain irrelevant information such as unrelated background or unimportant scenery. These tokens are overlooked by the multi-head self-attention (MHSA), resulting in many redundant and unnecessary computations in MHSA and the feed-forward network (FFN). In this work, we propose a method to optimize the amount of unnecessary interactions between unimportant tokens by separating and sending them through a different low-cost computational path. Our method does not add any parameters to the ViT model and aims to find the best trade-off between training throughput and achieving a 0% loss in the Top-1 accuracy of the final model. Our experimental results on training ViT-small from scratch show that SkipViT is capable of effectively dropping 55% of the tokens while gaining more than 13% training throughput and maintaining classification accuracy at the level of the baseline model on Huawei Ascend910A.