 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Parent Family: A Spectrum of Family Members from a Single Pre-Trained Foundation Model
Jun 28, 2024


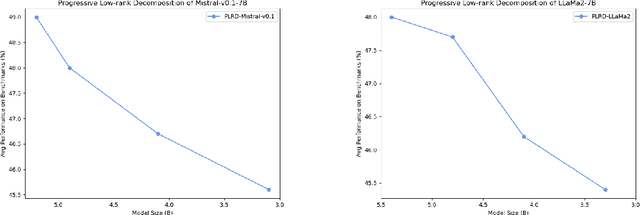
This paper introduces a novel method of Progressive Low Rank Decomposition (PLRD) tailored for the compression of large language models. Our approach leverages a pre-trained model, which is then incrementally decompressed to smaller sizes using progressively lower ranks. This method allows for significant reductions in computational overhead and energy consumption, as subsequent models are derived from the original without the need for retraining from scratch. We detail the implementation of PLRD, which strategically decreases the tensor ranks, thus optimizing the trade-off between model performance and resource usage. The efficacy of PLRD is demonstrated through extensive experiments showing that models trained with PLRD method on only 1B tokens maintain comparable performance with traditionally trained models while using 0.1% of the tokens. The versatility of PLRD is highlighted by its ability to generate multiple model sizes from a single foundational model, adapting fluidly to varying computational and memory budgets. Our findings suggest that PLRD could set a new standard for the efficient scaling of LLMs, making advanced AI more feasible on diverse platforms.
SkipViT: Speeding Up Vision Transformers with a Token-Level Skip Connection
Jan 27, 2024Vision transformers are known to be more computationally and data-intensive than CNN models. These transformer models such as ViT, require all the input image tokens to learn the relationship among them. However, many of these tokens are not informative and may contain irrelevant information such as unrelated background or unimportant scenery. These tokens are overlooked by the multi-head self-attention (MHSA), resulting in many redundant and unnecessary computations in MHSA and the feed-forward network (FFN). In this work, we propose a method to optimize the amount of unnecessary interactions between unimportant tokens by separating and sending them through a different low-cost computational path. Our method does not add any parameters to the ViT model and aims to find the best trade-off between training throughput and achieving a 0% loss in the Top-1 accuracy of the final model. Our experimental results on training ViT-small from scratch show that SkipViT is capable of effectively dropping 55% of the tokens while gaining more than 13% training throughput and maintaining classification accuracy at the level of the baseline model on Huawei Ascend910A.
SwiftLearn: A Data-Efficient Training Method of Deep Learning Models using Importance Sampling
Nov 25, 2023

In this paper, we present SwiftLearn, a data-efficient approach to accelerate training of deep learning models using a subset of data samples selected during the warm-up stages of training. This subset is selected based on an importance criteria measured over the entire dataset during warm-up stages, aiming to preserve the model performance with fewer examples during the rest of training. The importance measure we propose could be updated during training every once in a while, to make sure that all of the data samples have a chance to return to the training loop if they show a higher importance. The model architecture is unchanged but since the number of data samples controls the number of forward and backward passes during training, we can reduce the training time by reducing the number of training samples used in each epoch of training. Experimental results on a variety of CV and NLP models during both pretraining and finetuning show that the model performance could be preserved while achieving a significant speed-up during training. More specifically, BERT finetuning on GLUE benchmark shows that almost 90% of the data can be dropped achieving an end-to-end average speedup of 3.36x while keeping the average accuracy drop less than 0.92%.
GQKVA: Efficient Pre-training of Transformers by Grouping Queries, Keys, and Values
Nov 06, 2023


Massive transformer-based models face several challenges, including slow and computationally intensive pre-training and over-parametrization. This paper addresses these challenges by proposing a versatile method called GQKVA, which generalizes query, key, and value grouping techniques. GQKVA is designed to speed up transformer pre-training while reducing the model size. Our experiments with various GQKVA variants highlight a clear trade-off between performance and model size, allowing for customized choices based on resource and time limitations. Our findings also indicate that the conventional multi-head attention approach is not always the best choice, as there are lighter and faster alternatives available. We tested our method on ViT, which achieved an approximate 0.3% increase in accuracy while reducing the model size by about 4% in the task of image classification. Additionally, our most aggressive model reduction experiment resulted in a reduction of approximately 15% in model size, with only around a 1% drop in accuracy.
Gray-box Adversarial Attack of Deep Reinforcement Learning-based Trading Agents
Sep 26, 2023



In recent years, deep reinforcement learning (Deep RL) has been successfully implemented as a smart agent in many systems such as complex games, self-driving cars, and chat-bots. One of the interesting use cases of Deep RL is its application as an automated stock trading agent. In general, any automated trading agent is prone to manipulations by adversaries in the trading environment. Thus studying their robustness is vital for their success in practice. However, typical mechanism to study RL robustness, which is based on white-box gradient-based adversarial sample generation techniques (like FGSM), is obsolete for this use case, since the models are protected behind secure international exchange APIs, such as NASDAQ. In this research, we demonstrate that a "gray-box" approach for attacking a Deep RL-based trading agent is possible by trading in the same stock market, with no extra access to the trading agent. In our proposed approach, an adversary agent uses a hybrid Deep Neural Network as its policy consisting of Convolutional layers and fully-connected layers. On average, over three simulated trading market configurations, the adversary policy proposed in this research is able to reduce the reward values by 214.17%, which results in reducing the potential profits of the baseline by 139.4%, ensemble method by 93.7%, and an automated trading software developed by our industrial partner by 85.5%, while consuming significantly less budget than the victims (427.77%, 187.16%, and 66.97%, respectively).
Behavioral Model Inference of Black-box Software using Deep Neural Networks
Jan 13, 2021


Many software engineering tasks, such as testing, and anomaly detection can benefit from the ability to infer a behavioral model of the software.Most existing inference approaches assume access to code to collect execution sequences. In this paper, we investigate a black-box scenario, where the system under analysis cannot be instrumented, in this granular fashion.This scenario is particularly prevalent with control systems' log analysis in the form of continuous signals. In this situation, an execution trace amounts to a multivariate time-series of input and output signals, where different states of the system correspond to different `phases` in the time-series. The main challenge is to detect when these phase changes take place. Unfortunately, most existing solutions are either univariate, make assumptions on the data distribution, or have limited learning power.Therefore, we propose a hybrid deep neural network that accepts as input a multivariate time series and applies a set of convolutional and recurrent layers to learn the non-linear correlations between signals and the patterns over time.We show how this approach can be used to accurately detect state changes, and how the inferred models can be successfully applied to transfer-learning scenarios, to accurately process traces from different products with similar execution characteristics. Our experimental results on two UAV autopilot case studies indicate that our approach is highly accurate (over 90% F1 score for state classification) and significantly improves baselines (by up to 102% for change point detection).Using transfer learning we also show that up to 90% of the maximum achievable F1 scores in the open-source case study can be achieved by reusing the trained models from the industrial case and only fine tuning them using as low as 5 labeled samples, which reduces the manual labeling effort by 98%.