 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Parent Family: A Spectrum of Family Members from a Single Pre-Trained Foundation Model
Paper and Code



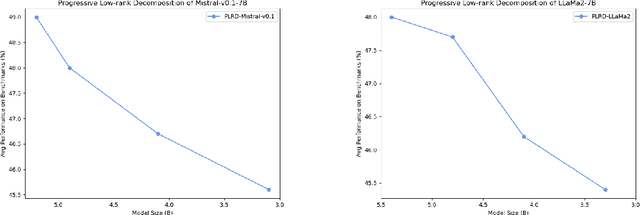
This paper introduces a novel method of Progressive Low Rank Decomposition (PLRD) tailored for the compression of large language models. Our approach leverages a pre-trained model, which is then incrementally decompressed to smaller sizes using progressively lower ranks. This method allows for significant reductions in computational overhead and energy consumption, as subsequent models are derived from the original without the need for retraining from scratch. We detail the implementation of PLRD, which strategically decreases the tensor ranks, thus optimizing the trade-off between model performance and resource usage. The efficacy of PLRD is demonstrated through extensive experiments showing that models trained with PLRD method on only 1B tokens maintain comparable performance with traditionally trained models while using 0.1% of the tokens. The versatility of PLRD is highlighted by its ability to generate multiple model sizes from a single foundational model, adapting fluidly to varying computational and memory budgets. Our findings suggest that PLRD could set a new standard for the efficient scaling of LLMs, making advanced AI more feasible on diverse platforms.