 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Role of Fault Localization Context for LLM-Based Program Repair
Apr 07, 2026Fault Localization (FL) is a key component of Large Language Model (LLM)-based Automated Program Repair (APR), yet its impact remains underexplored. In particular, it is unclear how much localization is needed, whether additional context beyond the predicted buggy location is beneficial, and how such context should be retrieved. We conduct a large-scale empirical study on 500 SWE-bench Verified instances using GPT-5-mini, evaluating 61 configurations that vary file-level, element-level, and line-level context. Our results show that more context does not consistently improve repair performance. File-level localization is the dominant factor, yielding a 15-17x improvement over a no-file baseline. Expanding file context is often associated with improved performance, with successful repairs most commonly observed in configurations with approximately 6-10 relevant files. Element-level context expansion provides conditional gains that depend strongly on the file context quality, while line-level context expansion frequently degrades performance due to noise amplification. LLM-based retrieval generally outperforms structural heuristics while using fewer files and tokens. Overall, the most effective FL context strategy typically combines a broad semantic understanding at higher abstraction levels with precise line-level localization. These findings challenge our assumption that increasing the localization context uniformly improves APR, and provide practical guidance for designing LLM-based FL strategies.
Enhancing LLM-Based Code Generation with Complexity Metrics: A Feedback-Driven Approach
May 29, 2025Automatic code generation has gained significant momentum with the advent of Large Language Models (LLMs) such as GPT-4. Although many studies focus on improving the effectiveness of LLMs for code generation, very limited work tries to understand the generated code's characteristics and leverage that to improve failed cases. In this paper, as the most straightforward characteristic of code, we investigate the relationship between code complexity and the success of LLM generated code. Using a large set of standard complexity metrics, we first conduct an empirical analysis to explore their correlation with LLM's performance on code generation (i.e., Pass@1). Using logistic regression models, we identify which complexity metrics are most predictive of code correctness. Building on these findings, we propose an iterative feedback method, where LLMs are prompted to generate correct code based on complexity metrics from previous failed outputs. We validate our approach across multiple benchmarks (i.e., HumanEval, MBPP, LeetCode, and BigCodeBench) and various LLMs (i.e., GPT-4o, GPT-3.5 Turbo, Llama 3.1, and GPT-o3 mini), comparing the results with two baseline methods: (a) zero-shot generation, and (b) iterative execution-based feedback without our code complexity insights. Experiment results show that our approach makes notable improvements, particularly with a smaller LLM (GPT3.5 Turbo), where, e.g., Pass@1 increased by 35.71% compared to the baseline's improvement of 12.5% on the HumanEval dataset. The study expands experiments to BigCodeBench and integrates the method with the Reflexion code generation agent, leading to Pass@1 improvements of 20% (GPT-4o) and 23.07% (GPT-o3 mini). The results highlight that complexity-aware feedback enhances both direct LLM prompting and agent-based workflows.
Deep-Bench: Deep Learning Benchmark Dataset for Code Generation
Feb 26, 2025



Deep learning (DL) has revolutionized areas such as computer vision, natural language processing, and more. However, developing DL systems is challenging due to the complexity of DL workflows. Large Language Models (LLMs), such as GPT, Claude, Llama, Mistral, etc., have emerged as promising tools to assist in DL code generation, offering potential solutions to these challenges. Despite this, existing benchmarks such as DS-1000 are limited, as they primarily focus on small DL code snippets related to pre/post-processing tasks and lack a comprehensive coverage of the full DL pipeline, including different DL phases and input data types. To address this, we introduce DeepBench, a novel benchmark dataset designed for function-level DL code generation. DeepBench categorizes DL problems based on three key aspects: phases such as pre-processing, model construction, and training; tasks, including classification, regression, and recommendation; and input data types such as tabular, image, and text. GPT-4o -- the state-of-the-art LLM -- achieved 31% accuracy on DeepBench, significantly lower than its 60% on DS-1000. We observed similar difficulty for other LLMs (e.g., 28% vs. 54% for Claude, 21% vs. 41% for LLaMA, and 15% vs. 20% for Mistral). This result underscores DeepBench's greater complexity. We also construct a taxonomy of issues and bugs found in LLM-generated DL code, which highlights the distinct challenges that LLMs face when generating DL code compared to general code. Furthermore, our analysis also reveals substantial performance variations across categories, with differences of up to 7% among phases and 37% among tasks. These disparities suggest that DeepBench offers valuable insights into the LLMs' performance and areas for potential improvement in the DL domain.
VALTEST: Automated Validation of Language Model Generated Test Cases
Nov 13, 2024Large Language Models (LLMs) have demonstrated significant potential in automating software testing, specifically in generating unit test cases. However, the validation of LLM-generated test cases remains a challenge, particularly when the ground truth is unavailable. This paper introduces VALTEST, a novel framework designed to automatically validate test cases generated by LLMs by leveraging token probabilities. We evaluate VALTEST using nine test suites generated from three datasets (HumanEval, MBPP, and LeetCode) across three LLMs (GPT-4o, GPT-3.5-turbo, and LLama3.1 8b). By extracting statistical features from token probabilities, we train a machine learning model to predict test case validity. VALTEST increases the validity rate of test cases by 6.2% to 24%, depending on the dataset and LLM. Our results suggest that token probabilities are reliable indicators for distinguishing between valid and invalid test cases, which provides a robust solution for improving the correctness of LLM-generated test cases in software testing. In addition, we found that replacing the identified invalid test cases by VALTEST, using a Chain-of-Thought prompting results in a more effective test suite while keeping the high validity rates.
EPiC: Cost-effective Search-based Prompt Engineering of LLMs for Code Generation
Aug 20, 2024



Large Language Models (LLMs) have seen increasing use in various software development tasks, especially in code generation. The most advanced recent methods attempt to incorporate feedback from code execution into prompts to help guide LLMs in generating correct code, in an iterative process. While effective, these methods could be costly and time-consuming due to numerous interactions with the LLM and the extensive token usage. To address this issue, we propose an alternative approach named Evolutionary Prompt Engineering for Code (EPiC), which leverages a lightweight evolutionary algorithm to evolve the original prompts toward better ones that produce high-quality code, with minimal interactions with LLM. Our evaluation against state-of-the-art (SOTA) LLM-based code generation models shows that EPiC outperforms all the baselines in terms of cost-effectiveness.
Can ChatGPT Support Developers? An Empirical Evaluation of Large Language Models for Code Generation
Feb 18, 2024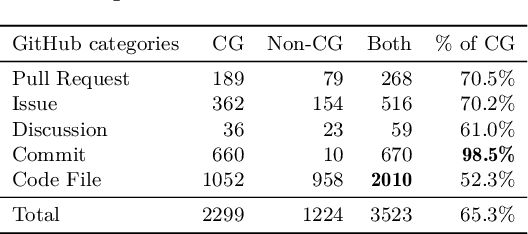
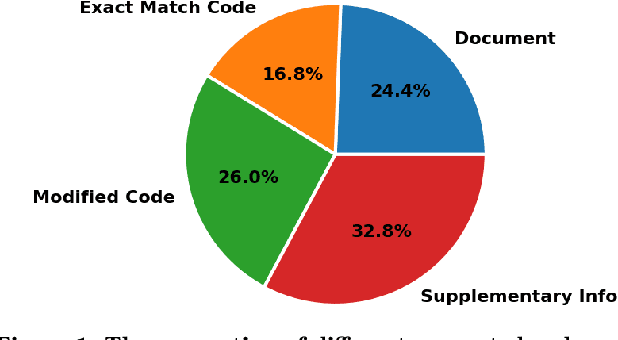

Large language models (LLMs) have demonstrated notable proficiency in code generation, with numerous prior studies showing their promising capabilities in various development scenarios. However, these studies mainly provide evaluations in research settings, which leaves a significant gap in understanding how effectively LLMs can support developers in real-world. To address this, we conducted an empirical analysis of conversations in DevGPT, a dataset collected from developers' conversations with ChatGPT (captured with the Share Link feature on platforms such as GitHub). Our empirical findings indicate that the current practice of using LLM-generated code is typically limited to either demonstrating high-level concepts or providing examples in documentation, rather than to be used as production-ready code. These findings indicate that there is much future work needed to improve LLMs in code generation before they can be integral parts of modern software development.
I came, I saw, I certified: some perspectives on the safety assurance of cyber-physical systems
Jan 30, 2024The execution failure of cyber-physical systems (e.g., autonomous driving systems, unmanned aerial systems, and robotic systems) could result in the loss of life, severe injuries, large-scale environmental damage, property destruction, and major economic loss. Hence, such systems usually require a strong justification that they will effectively support critical requirements (e.g., safety, security, and reliability) for which they were designed. Thus, it is often mandatory to develop compelling assurance cases to support that justification and allow regulatory bodies to certify such systems. In such contexts, detecting assurance deficits, relying on patterns to improve the structure of assurance cases, improving existing assurance case notations, and (semi-)automating the generation of assurance cases are key to develop compelling assurance cases and foster consumer acceptance. We therefore explore challenges related to such assurance enablers and outline some potential directions that could be explored to tackle them.
Log-based Anomaly Detection of Enterprise Software: An Empirical Study
Oct 31, 2023Most enterprise applications use logging as a mechanism to diagnose anomalies, which could help with reducing system downtime. Anomaly detection using software execution logs has been explored in several prior studies, using both classical and deep neural network-based machine learning models. In recent years, the research has largely focused in using variations of sequence-based deep neural networks (e.g., Long-Short Term Memory and Transformer-based models) for log-based anomaly detection on open-source data. However, they have not been applied in industrial datasets, as often. In addition, the studied open-source datasets are typically very large in size with logging statements that do not change much over time, which may not be the case with a dataset from an industrial service that is relatively new. In this paper, we evaluate several state-of-the-art anomaly detection models on an industrial dataset from our research partner, which is much smaller and loosely structured than most large scale open-source benchmark datasets. Results show that while all models are capable of detecting anomalies, certain models are better suited for less-structured datasets. We also see that model effectiveness changes when a common data leak associated with a random train-test split in some prior work is removed. A qualitative study of the defects' characteristics identified by the developers on the industrial dataset further shows strengths and weaknesses of the models in detecting different types of anomalies. Finally, we explore the effect of limited training data by gradually increasing the training set size, to evaluate if the model effectiveness does depend on the training set size.
Assessing Evaluation Metrics for Neural Test Oracle Generation
Oct 11, 2023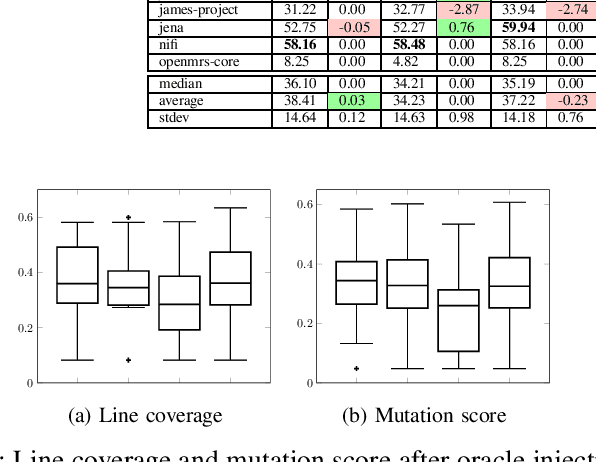


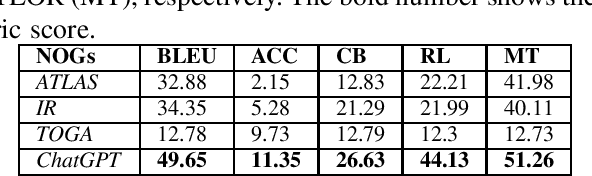
In this work, we revisit existing oracle generation studies plus ChatGPT to empirically investigate the current standing of their performance in both NLG-based and test adequacy metrics. Specifically, we train and run four state-of-the-art test oracle generation models on five NLG-based and two test adequacy metrics for our analysis. We apply two different correlation analyses between these two different sets of metrics. Surprisingly, we found no significant correlation between the NLG-based metrics and test adequacy metrics. For instance, oracles generated from ChatGPT on the project activemq-artemis had the highest performance on all the NLG-based metrics among the studied NOGs, however, it had the most number of projects with a decrease in test adequacy metrics compared to all the studied NOGs. We further conduct a qualitative analysis to explore the reasons behind our observations, we found that oracles with high NLG-based metrics but low test adequacy metrics tend to have complex or multiple chained method invocations within the oracle's parameters, making it hard for the model to generate completely, affecting the test adequacy metrics. On the other hand, oracles with low NLG-based metrics but high test adequacy metrics tend to have to call different assertion types or a different method that functions similarly to the ones in the ground truth. Overall, this work complements prior studies on test oracle generation with an extensive performance evaluation with both NLG and test adequacy metrics and provides guidelines for better assessment of deep learning applications in software test generation in the future.
Gray-box Adversarial Attack of Deep Reinforcement Learning-based Trading Agents
Sep 26, 2023



In recent years, deep reinforcement learning (Deep RL) has been successfully implemented as a smart agent in many systems such as complex games, self-driving cars, and chat-bots. One of the interesting use cases of Deep RL is its application as an automated stock trading agent. In general, any automated trading agent is prone to manipulations by adversaries in the trading environment. Thus studying their robustness is vital for their success in practice. However, typical mechanism to study RL robustness, which is based on white-box gradient-based adversarial sample generation techniques (like FGSM), is obsolete for this use case, since the models are protected behind secure international exchange APIs, such as NASDAQ. In this research, we demonstrate that a "gray-box" approach for attacking a Deep RL-based trading agent is possible by trading in the same stock market, with no extra access to the trading agent. In our proposed approach, an adversary agent uses a hybrid Deep Neural Network as its policy consisting of Convolutional layers and fully-connected layers. On average, over three simulated trading market configurations, the adversary policy proposed in this research is able to reduce the reward values by 214.17%, which results in reducing the potential profits of the baseline by 139.4%, ensemble method by 93.7%, and an automated trading software developed by our industrial partner by 85.5%, while consuming significantly less budget than the victims (427.77%, 187.16%, and 66.97%, respectively).