 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-Bench: Deep Learning Benchmark Dataset for Code Generation
Feb 26, 2025



Deep learning (DL) has revolutionized areas such as computer vision, natural language processing, and more. However, developing DL systems is challenging due to the complexity of DL workflows. Large Language Models (LLMs), such as GPT, Claude, Llama, Mistral, etc., have emerged as promising tools to assist in DL code generation, offering potential solutions to these challenges. Despite this, existing benchmarks such as DS-1000 are limited, as they primarily focus on small DL code snippets related to pre/post-processing tasks and lack a comprehensive coverage of the full DL pipeline, including different DL phases and input data types. To address this, we introduce DeepBench, a novel benchmark dataset designed for function-level DL code generation. DeepBench categorizes DL problems based on three key aspects: phases such as pre-processing, model construction, and training; tasks, including classification, regression, and recommendation; and input data types such as tabular, image, and text. GPT-4o -- the state-of-the-art LLM -- achieved 31% accuracy on DeepBench, significantly lower than its 60% on DS-1000. We observed similar difficulty for other LLMs (e.g., 28% vs. 54% for Claude, 21% vs. 41% for LLaMA, and 15% vs. 20% for Mistral). This result underscores DeepBench's greater complexity. We also construct a taxonomy of issues and bugs found in LLM-generated DL code, which highlights the distinct challenges that LLMs face when generating DL code compared to general code. Furthermore, our analysis also reveals substantial performance variations across categories, with differences of up to 7% among phases and 37% among tasks. These disparities suggest that DeepBench offers valuable insights into the LLMs' performance and areas for potential improvement in the DL domain.
Defect Prediction with Content-based Features
Sep 27, 2024



Traditional defect prediction approaches often use metrics that measure the complexity of the design or implementing code of a software system, such as the number of lines of code in a source file. In this paper, we explore a different approach based on content of source code. Our key assumption is that source code of a software system contains information about its technical aspects and those aspects might have different levels of defect-proneness. Thus, content-based features such as words, topics, data types, and package names extracted from a source code file could be used to predict its defects. We have performed an extensive empirical evaluation and found that: i) such content-based features have higher predictive power than code complexity metrics and ii) the use of feature selection, reduction, and combination further improves the prediction performance.
Task-oriented Prompt Enhancement via Script Generation
Sep 24, 2024



Large Language Models (LLMs) have demonstrated remarkable abilities across various tasks, leveraging advanced reasoning. Yet, they struggle with task-oriented prompts due to a lack of specific prior knowledge of the task answers. The current state-of-the-art approach, PAL, utilizes code generation to address this issue. However, PAL depends on manually crafted prompt templates and examples while still producing inaccurate results. In this work, we present TITAN-a novel strategy designed to enhance LLMs' performance on task-oriented prompts. TITAN achieves this by generating scripts using a universal approach and zero-shot learning. Unlike existing methods, TITAN eliminates the need for detailed task-specific instructions and extensive manual efforts. TITAN enhances LLMs' performance on various tasks by utilizing their analytical and code-generation capabilities in a streamlined process. TITAN employs two key techniques: (1) step-back prompting to extract the task's input specifications and (2) chain-of-thought prompting to identify required procedural steps. This information is used to improve the LLMs' code-generation process. TITAN further refines the generated script through post-processing and the script is executed to retrieve the final answer. Our comprehensive evaluation demonstrates TITAN's effectiveness in a diverse set of tasks. On average, TITAN outperforms the state-of-the-art zero-shot approach by 7.6% and 3.9% when paired with GPT-3.5 and GPT-4. Overall, without human annotation, TITAN achieves state-of-the-art performance in 8 out of 11 cases while only marginally losing to few-shot approaches (which needed human intervention) on three occasions by small margins. This work represents a significant advancement in addressing task-oriented prompts, offering a novel solution for effectively utilizing LLMs in everyday life tasks.
Selection of Prompt Engineering Techniques for Code Generation through Predicting Code Complexity
Sep 24, 2024



Large Language Models (LLMs) have demonstrated impressive performance in software engineering tasks. However, improving their accuracy in generating correct and reliable code remains challenging. Numerous prompt engineering techniques (PETs) have been developed to address this, but no single approach is universally optimal. Selecting the right PET for each query is difficult for two primary reasons: (1) interactive prompting techniques may not consistently deliver the expected benefits, especially for simpler queries, and (2) current automated prompt engineering methods lack adaptability and fail to fully utilize multi-stage responses. To overcome these challenges, we propose PET-Select, a PET-agnostic selection model that uses code complexity as a proxy to classify queries and select the most appropriate PET. By incorporating contrastive learning, PET-Select effectively distinguishes between simple and complex problems, allowing it to choose PETs that are best suited for each query's complexity level. Our evaluations on the MBPP and HumanEval benchmarks using GPT-3.5 Turbo and GPT-4o show up to a 1.9% improvement in pass@1 accuracy, along with a 74.8% reduction in token usage. Additionally, we provide both quantitative and qualitative results to demonstrate how PET-Select effectively selects the most appropriate techniques for each code generation query, further showcasing its efficiency in optimizing PET selection.
EPiC: Cost-effective Search-based Prompt Engineering of LLMs for Code Generation
Aug 20, 2024



Large Language Models (LLMs) have seen increasing use in various software development tasks, especially in code generation. The most advanced recent methods attempt to incorporate feedback from code execution into prompts to help guide LLMs in generating correct code, in an iterative process. While effective, these methods could be costly and time-consuming due to numerous interactions with the LLM and the extensive token usage. To address this issue, we propose an alternative approach named Evolutionary Prompt Engineering for Code (EPiC), which leverages a lightweight evolutionary algorithm to evolve the original prompts toward better ones that produce high-quality code, with minimal interactions with LLM. Our evaluation against state-of-the-art (SOTA) LLM-based code generation models shows that EPiC outperforms all the baselines in terms of cost-effectiveness.
Can ChatGPT Support Developers? An Empirical Evaluation of Large Language Models for Code Generation
Feb 18, 2024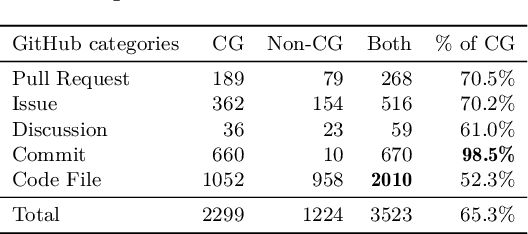

Large language models (LLMs) have demonstrated notable proficiency in code generation, with numerous prior studies showing their promising capabilities in various development scenarios. However, these studies mainly provide evaluations in research settings, which leaves a significant gap in understanding how effectively LLMs can support developers in real-world. To address this, we conducted an empirical analysis of conversations in DevGPT, a dataset collected from developers' conversations with ChatGPT (captured with the Share Link feature on platforms such as GitHub). Our empirical findings indicate that the current practice of using LLM-generated code is typically limited to either demonstrating high-level concepts or providing examples in documentation, rather than to be used as production-ready code. These findings indicate that there is much future work needed to improve LLMs in code generation before they can be integral parts of modern software development.
How Effective Are Neural Networks for Fixing Security Vulnerabilities
May 29, 2023Security vulnerability repair is a difficult task that is in dire need of automation. Two groups of techniques have shown promise: (1) large code language models (LLMs) that have been pre-trained on source code for tasks such as code completion, and (2) automated program repair (APR) techniques that use deep learning (DL) models to automatically fix software bugs. This paper is the first to study and compare Java vulnerability repair capabilities of LLMs and DL-based APR models. The contributions include that we (1) apply and evaluate five LLMs (Codex, CodeGen, CodeT5, PLBART and InCoder), four fine-tuned LLMs, and four DL-based APR techniques on two real-world Java vulnerability benchmarks (Vul4J and VJBench), (2) design code transformations to address the training and test data overlapping threat to Codex, (3) create a new Java vulnerability repair benchmark VJBench, and its transformed version VJBench-trans and (4) evaluate LLMs and APR techniques on the transformed vulnerabilities in VJBench-trans. Our findings include that (1) existing LLMs and APR models fix very few Java vulnerabilities. Codex fixes 10.2 (20.4%), the most number of vulnerabilities. (2) Fine-tuning with general APR data improves LLMs' vulnerability-fixing capabilities. (3) Our new VJBench reveals that LLMs and APR models fail to fix many Common Weakness Enumeration (CWE) types, such as CWE-325 Missing cryptographic step and CWE-444 HTTP request smuggling. (4) Codex still fixes 8.3 transformed vulnerabilities, outperforming all the other LLMs and APR models on transformed vulnerabilities. The results call for innovations to enhance automated Java vulnerability repair such as creating larger vulnerability repair training data, tuning LLMs with such data, and applying code simplification transformation to facilitate vulnerability repair.
Mining User Opinions in Mobile App Reviews: A Keyword-based Approach
Oct 26, 2015
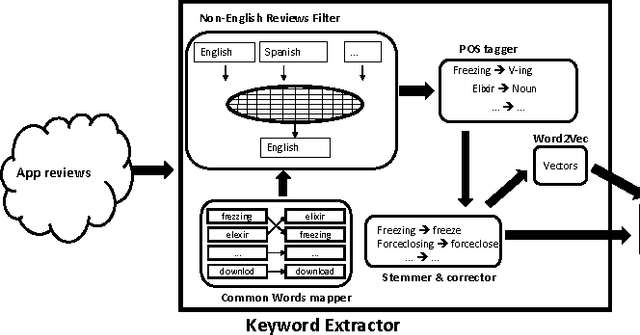
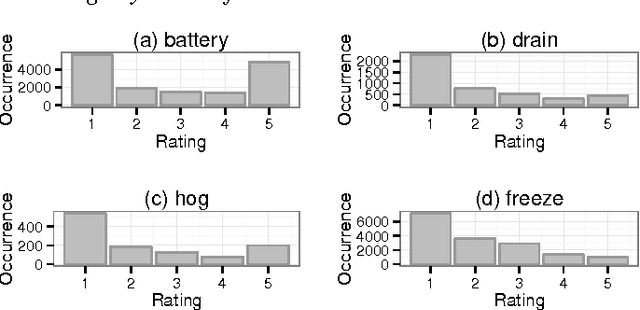

User reviews of mobile apps often contain complaints or suggestions which are valuable for app developers to improve user experience and satisfaction. However, due to the large volume and noisy-nature of those reviews, manually analyzing them for useful opinions is inherently challenging. To address this problem, we propose MARK, a keyword-based framework for semi-automated review analysis. MARK allows an analyst describing his interests in one or some mobile apps by a set of keywords. It then finds and lists the reviews most relevant to those keywords for further analysis. It can also draw the trends over time of those keywords and detect their sudden changes, which might indicate the occurrences of serious issues. To help analysts describe their interests more effectively, MARK can automatically extract keywords from raw reviews and rank them by their associations with negative reviews. In addition, based on a vector-based semantic representation of keywords, MARK can divide a large set of keywords into more cohesive subsets, or suggest keywords similar to the selected ones.