 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJupOtter: Cell-Level Bug Detection in Jupyter Notebooks
Jun 22, 2026Jupyter Notebooks are an increasingly popular coding environment used across many domains, especially in Python-based data science and scientific computing. Originally used for prototyping and interactive exploration, notebooks are increasingly used to develop more complex programs, leading to a rapid rise in buggy notebooks on platforms like GitHub. To address this trend, we present JupOtter, a bug detection system designed specifically for Jupyter Notebooks. JupOtter features three novel contributions: (1) a notebook-specific tokenization strategy that preserves cell structure, (2) a cell-level bug prediction technique, and (3) a new labeled dataset, OtterDataset, containing over 21,000 notebooks annotated for fine-grained cell-level bug detection. JupOtter achieves cell-level bug detection F1 scores that surpass static analyzers and large language models in two out of three evaluation datasets.
How Effective Are Neural Networks for Fixing Security Vulnerabilities
May 29, 2023



Security vulnerability repair is a difficult task that is in dire need of automation. Two groups of techniques have shown promise: (1) large code language models (LLMs) that have been pre-trained on source code for tasks such as code completion, and (2) automated program repair (APR) techniques that use deep learning (DL) models to automatically fix software bugs. This paper is the first to study and compare Java vulnerability repair capabilities of LLMs and DL-based APR models. The contributions include that we (1) apply and evaluate five LLMs (Codex, CodeGen, CodeT5, PLBART and InCoder), four fine-tuned LLMs, and four DL-based APR techniques on two real-world Java vulnerability benchmarks (Vul4J and VJBench), (2) design code transformations to address the training and test data overlapping threat to Codex, (3) create a new Java vulnerability repair benchmark VJBench, and its transformed version VJBench-trans and (4) evaluate LLMs and APR techniques on the transformed vulnerabilities in VJBench-trans. Our findings include that (1) existing LLMs and APR models fix very few Java vulnerabilities. Codex fixes 10.2 (20.4%), the most number of vulnerabilities. (2) Fine-tuning with general APR data improves LLMs' vulnerability-fixing capabilities. (3) Our new VJBench reveals that LLMs and APR models fail to fix many Common Weakness Enumeration (CWE) types, such as CWE-325 Missing cryptographic step and CWE-444 HTTP request smuggling. (4) Codex still fixes 8.3 transformed vulnerabilities, outperforming all the other LLMs and APR models on transformed vulnerabilities. The results call for innovations to enhance automated Java vulnerability repair such as creating larger vulnerability repair training data, tuning LLMs with such data, and applying code simplification transformation to facilitate vulnerability repair.
KNOD: Domain Knowledge Distilled Tree Decoder for Automated Program Repair
Feb 03, 2023Automated Program Repair (APR) improves software reliability by generating patches for a buggy program automatically. Recent APR techniques leverage deep learning (DL) to build models to learn to generate patches from existing patches and code corpora. While promising, DL-based APR techniques suffer from the abundant syntactically or semantically incorrect patches in the patch space. These patches often disobey the syntactic and semantic domain knowledge of source code and thus cannot be the correct patches to fix a bug. We propose a DL-based APR approach KNOD, which incorporates domain knowledge to guide patch generation in a direct and comprehensive way. KNOD has two major novelties, including (1) a novel three-stage tree decoder, which directly generates Abstract Syntax Trees of patched code according to the inherent tree structure, and (2) a novel domain-rule distillation, which leverages syntactic and semantic rules and teacher-student distributions to explicitly inject the domain knowledge into the decoding procedure during both the training and inference phases. We evaluate KNOD on three widely-used benchmarks. KNOD fixes 72 bugs on the Defects4J v1.2, 25 bugs on the QuixBugs, and 50 bugs on the additional Defects4J v2.0 benchmarks, outperforming all existing APR tools.
CURE: Code-Aware Neural Machine Translation for Automatic Program Repair
Feb 26, 2021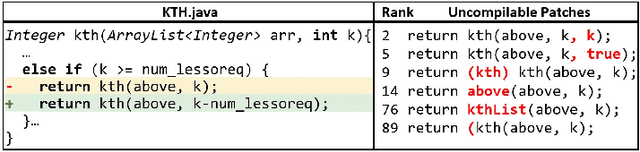
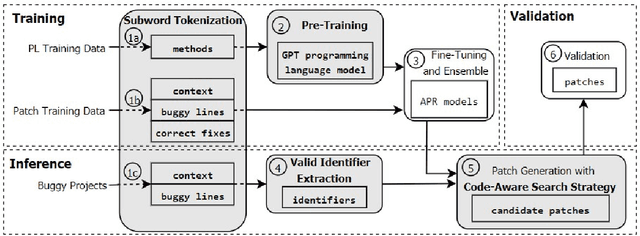

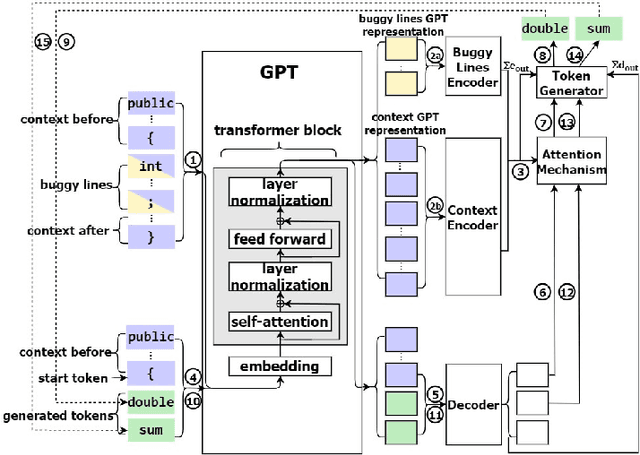
Automatic program repair (APR) is crucial to improve software reliability. Recently, neural machine translation (NMT) techniques have been used to fix software bugs automatically. While promising, these approaches have two major limitations. Their search space often does not contain the correct fix, and their search strategy ignores software knowledge such as strict code syntax. Due to these limitations, existing NMT-based techniques underperform the best template-based approaches. We propose CURE, a new NMT-based APR technique with three major novelties. First, CURE pre-trains a programming language (PL) model on a large software codebase to learn developer-like source code before the APR task. Second, CURE designs a new code-aware search strategy that finds more correct fixes by focusing on compilable patches and patches that are close in length to the buggy code. Finally, CURE uses a subword tokenization technique to generate a smaller search space that contains more correct fixes. Our evaluation on two widely-used benchmarks shows that CURE correctly fixes 57 Defects4J bugs and 26 QuixBugs bugs, outperforming all existing APR techniques on both benchmarks.
ENCORE: Ensemble Learning using Convolution Neural Machine Translation for Automatic Program Repair
Jun 20, 2019
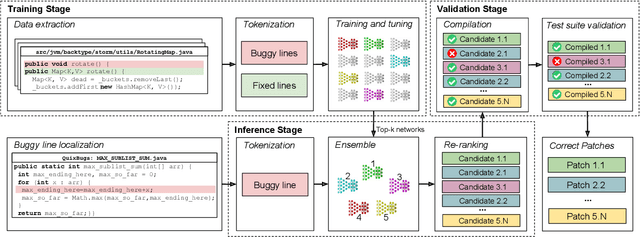
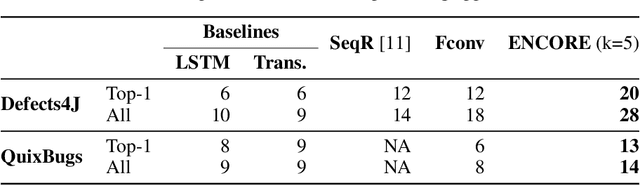
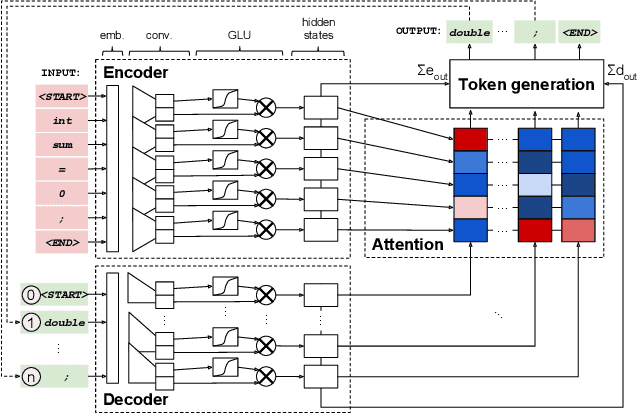
Automated generate-and-validate (G&V) program repair techniques typically rely on hard-coded rules, only fix bugs following specific patterns, and are hard to adapt to different programming languages. We propose ENCORE, a new G&V technique, which uses ensemble learning on convolutional neural machine translation (NMT) models to automatically fix bugs in multiple programming languages. We take advantage of the randomness in hyper-parameter tuning to build multiple models that fix different bugs and combine them using ensemble learning. This new convolutional NMT approach outperforms the standard long short-term memory (LSTM) approach used in previous work, as it better captures both local and long-distance connections between tokens. Our evaluation on two popular benchmarks, Defects4J and QuixBugs, shows that ENCORE fixed 42 bugs, including 16 that have not been fixed by existing techniques. In addition, ENCORE is the first G&V repair technique to be applied to four popular programming languages (Java, C++, Python, and JavaScript), fixing a total of 67 bugs across five benchmarks.