 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntelligent System of Emergent Knowledge: A Coordination Fabric for Billions of Minds
Jun 11, 2025The Intelligent System of Emergent Knowledge (ISEK) establishes a decentralized network where human and artificial intelligence agents collaborate as peers, forming a self-organizing cognitive ecosystem. Built on Web3 infrastructure, ISEK combines three fundamental principles: (1) a decentralized multi-agent architecture resistant to censorship, (2) symbiotic AI-human collaboration with equal participation rights, and (3) resilient self-adaptation through distributed consensus mechanisms. The system implements an innovative coordination protocol featuring a six-phase workflow (Publish, Discover, Recruit, Execute, Settle, Feedback) for dynamic task allocation, supported by robust fault tolerance and a multidimensional reputation system. Economic incentives are governed by the native $ISEK token, facilitating micropayments, governance participation, and reputation tracking, while agent sovereignty is maintained through NFT-based identity management. This synthesis of blockchain technology, artificial intelligence, and incentive engineering creates an infrastructure that actively facilitates emergent intelligence. ISEK represents a paradigm shift from conventional platforms, enabling the organic development of large-scale, decentralized cognitive systems where autonomous agents collectively evolve beyond centralized constraints.
A Survey on Query-based API Recommendation
Dec 21, 2023Application Programming Interfaces (APIs) are designed to help developers build software more effectively. Recommending the right APIs for specific tasks has gained increasing attention among researchers and developers in recent years. To comprehensively understand this research domain, we have surveyed to analyze API recommendation studies published in the last 10 years. Our study begins with an overview of the structure of API recommendation tools. Subsequently, we systematically analyze prior research and pose four key research questions. For RQ1, we examine the volume of published papers and the venues in which these papers appear within the API recommendation field. In RQ2, we categorize and summarize the prevalent data sources and collection methods employed in API recommendation research. In RQ3, we explore the types of data and common data representations utilized by API recommendation approaches. We also investigate the typical data extraction procedures and collection approaches employed by the existing approaches. RQ4 delves into the modeling techniques employed by API recommendation approaches, encompassing both statistical and deep learning models. Additionally, we compile an overview of the prevalent ranking strategies and evaluation metrics used for assessing API recommendation tools. Drawing from our survey findings, we identify current challenges in API recommendation research that warrant further exploration, along with potential avenues for future research.
Assessing Evaluation Metrics for Neural Test Oracle Generation
Oct 11, 2023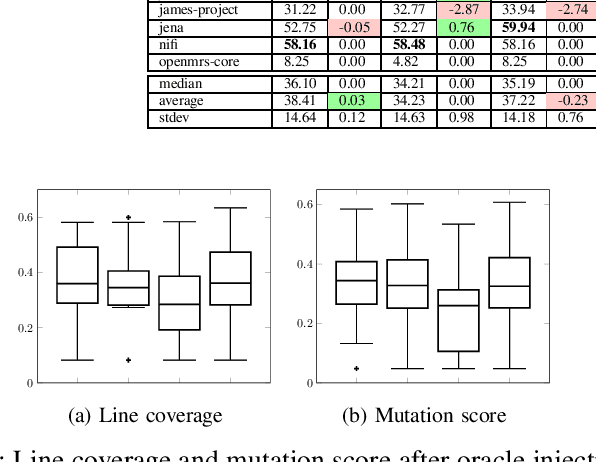


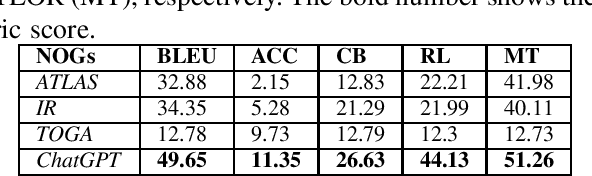
In this work, we revisit existing oracle generation studies plus ChatGPT to empirically investigate the current standing of their performance in both NLG-based and test adequacy metrics. Specifically, we train and run four state-of-the-art test oracle generation models on five NLG-based and two test adequacy metrics for our analysis. We apply two different correlation analyses between these two different sets of metrics. Surprisingly, we found no significant correlation between the NLG-based metrics and test adequacy metrics. For instance, oracles generated from ChatGPT on the project activemq-artemis had the highest performance on all the NLG-based metrics among the studied NOGs, however, it had the most number of projects with a decrease in test adequacy metrics compared to all the studied NOGs. We further conduct a qualitative analysis to explore the reasons behind our observations, we found that oracles with high NLG-based metrics but low test adequacy metrics tend to have complex or multiple chained method invocations within the oracle's parameters, making it hard for the model to generate completely, affecting the test adequacy metrics. On the other hand, oracles with low NLG-based metrics but high test adequacy metrics tend to have to call different assertion types or a different method that functions similarly to the ones in the ground truth. Overall, this work complements prior studies on test oracle generation with an extensive performance evaluation with both NLG and test adequacy metrics and provides guidelines for better assessment of deep learning applications in software test generation in the future.
Dynamic Encoding and Decoding of Information for Split Learning in Mobile-Edge Computing: Leveraging Information Bottleneck Theory
Sep 06, 2023Split learning is a privacy-preserving distributed learning paradigm in which an ML model (e.g., a neural network) is split into two parts (i.e., an encoder and a decoder). The encoder shares so-called latent representation, rather than raw data, for model training. In mobile-edge computing, network functions (such as traffic forecasting) can be trained via split learning where an encoder resides in a user equipment (UE) and a decoder resides in the edge network. Based on the data processing inequality and the information bottleneck (IB) theory, we present a new framework and training mechanism to enable a dynamic balancing of the transmission resource consumption with the informativeness of the shared latent representations, which directly impacts the predictive performance. The proposed training mechanism offers an encoder-decoder neural network architecture featuring multiple modes of complexity-relevance tradeoffs, enabling tunable performance. The adaptability can accommodate varying real-time network conditions and application requirements, potentially reducing operational expenditure and enhancing network agility. As a proof of concept, we apply the training mechanism to a millimeter-wave (mmWave)-enabled throughput prediction problem. We also offer new insights and highlight some challenges related to recurrent neural networks from the perspective of the IB theory. Interestingly, we find a compression phenomenon across the temporal domain of the sequential model, in addition to the compression phase that occurs with the number of training epochs.
ENCORE: Ensemble Learning using Convolution Neural Machine Translation for Automatic Program Repair
Jun 20, 2019
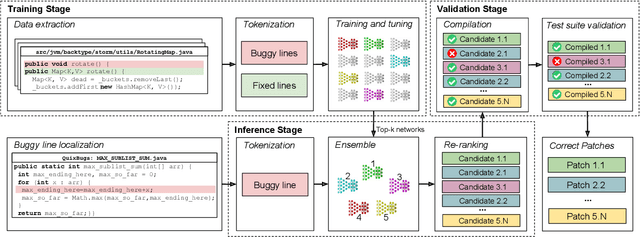
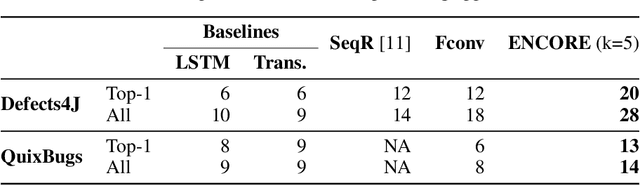
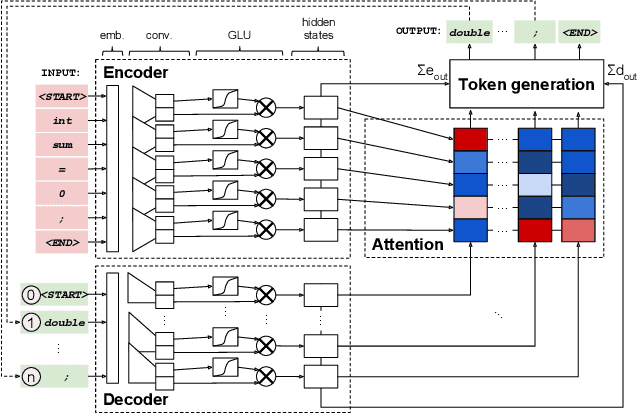
Automated generate-and-validate (G&V) program repair techniques typically rely on hard-coded rules, only fix bugs following specific patterns, and are hard to adapt to different programming languages. We propose ENCORE, a new G&V technique, which uses ensemble learning on convolutional neural machine translation (NMT) models to automatically fix bugs in multiple programming languages. We take advantage of the randomness in hyper-parameter tuning to build multiple models that fix different bugs and combine them using ensemble learning. This new convolutional NMT approach outperforms the standard long short-term memory (LSTM) approach used in previous work, as it better captures both local and long-distance connections between tokens. Our evaluation on two popular benchmarks, Defects4J and QuixBugs, shows that ENCORE fixed 42 bugs, including 16 that have not been fixed by existing techniques. In addition, ENCORE is the first G&V repair technique to be applied to four popular programming languages (Java, C++, Python, and JavaScript), fixing a total of 67 bugs across five benchmarks.