 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopology-Preserving Deep Joint Source-Channel Coding for Semantic Communication
Mar 17, 2026Many wireless vision applications, such as autonomous driving, require preservation of global structural information rather than only per-pixel fidelity. However, existing Deep joint source-channel coding (DeepJSCC) schemes mainly optimize pixel-wise losses and provide no explicit protection of connectivity or topology. This letter proposes TopoJSCC, a topology-aware DeepJSCC framework that integrates persistent-homology regularizers to end-to-end training. Specifically, we enforce topological consistency by penalizing Wasserstein distances between cubical persistence diagrams of original and reconstructed images, and between Vietoris--Rips persistence of latent features before and after the channel to promote a robust latent manifold. TopoJSCC is based on end-to-end learning and requires no side information. Experiments show improved topology preservation and peak signal-to-noise ratio (PSNR) in low signal-to-noise ratio (SNR) and bandwidth-ratio regimes.
Two-Layer Reinforcement Learning-Assisted Joint Beamforming and Trajectory Optimization for Multi-UAV Downlink Communications
Jan 19, 2026Unmanned aerial vehicles (UAVs) are pivotal for future 6G non-terrestrial networks, yet their high mobility creates a complex coupled optimization problem for beamforming and trajectory design. Existing numerical methods suffer from prohibitive latency, while standard deep learning often ignores dynamic interference topology, limiting scalability. To address these issues, this paper proposes a hierarchically decoupled framework synergizing graph neural networks (GNNs) with multi-agent reinforcement learning. Specifically, on the short timescale, we develop a topology-aware GNN beamformer by incorporating GraphNorm. By modeling the dynamic UAV-user association as a time-varying heterogeneous graph, this method explicitly extracts interference patterns to achieve sub-millisecond inference. On the long timescale, trajectory planning is modeled as a decentralized partially observable Markov decision process and solved via the multi-agent proximal policy optimization algorithm under the centralized training with decentralized execution paradigm, facilitating cooperative behaviors. Extensive simulation results demonstrate that the proposed framework significantly outperforms state-of-the-art optimization heuristics and deep learning baselines in terms of system sum rate, convergence speed, and generalization capability.
Adaptive Pareto-Optimal Token Merging for Edge Transformer Models in Semantic Communication
Sep 11, 2025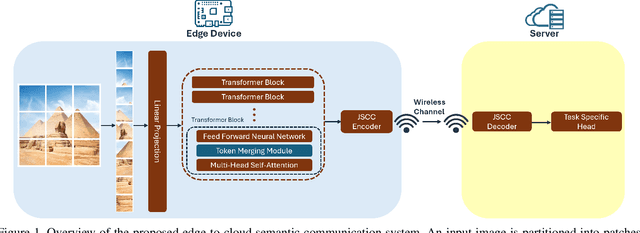
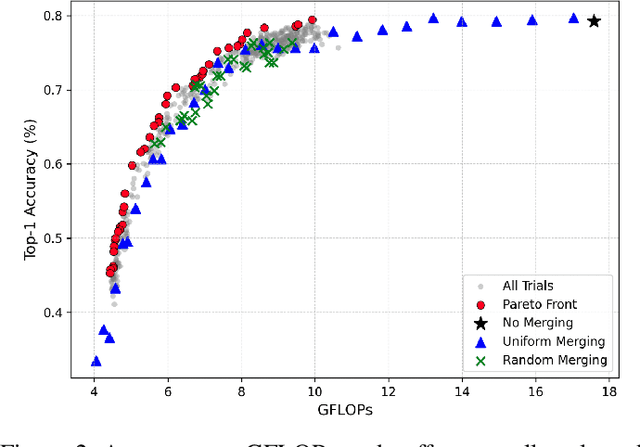
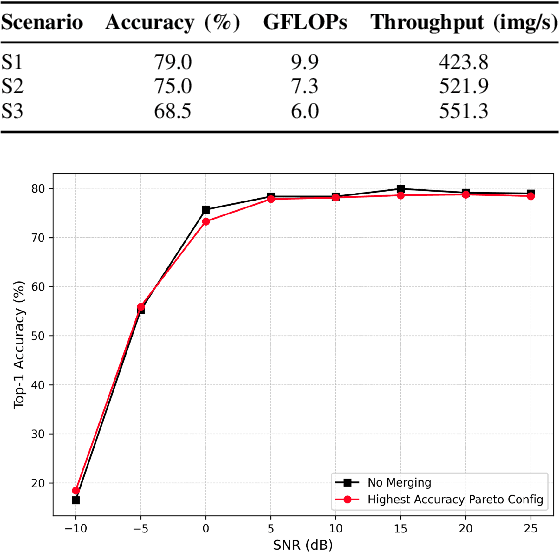
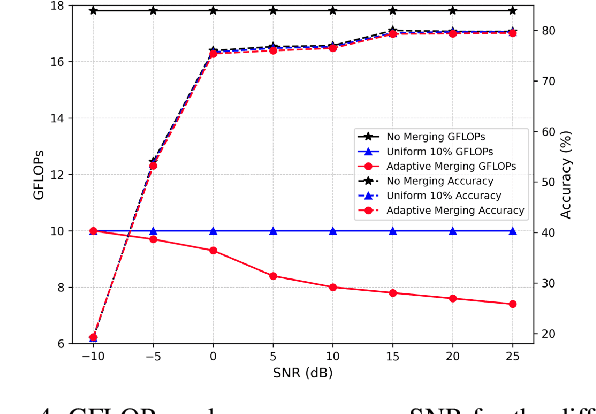
Large-scale transformer models have emerged as a powerful tool for semantic communication systems, enabling edge devices to extract rich representations for robust inference across noisy wireless channels. However, their substantial computational demands remain a major barrier to practical deployment in resource-constrained 6G networks. In this paper, we present a training-free framework for adaptive token merging in pretrained vision transformers to jointly reduce inference time and transmission resource usage. We formulate the selection of per-layer merging proportions as a multi-objective optimization problem to balance accuracy and computational cost. We employ Gaussian process-based Bayesian optimization to construct a Pareto frontier of optimal configurations, enabling flexible runtime adaptation to dynamic application requirements and channel conditions. Extensive experiments demonstrate that our method consistently outperforms other baselines and achieves significant reductions in floating-point operations while maintaining competitive accuracy across a wide range of signal-to-noise ratio (SNR) conditions. Additional results highlight the effectiveness of adaptive policies that adjust merging aggressiveness in response to channel quality, providing a practical mechanism to trade off latency and semantic fidelity on demand. These findings establish a scalable and efficient approach for deploying transformer-based semantic communication in future edge intelligence systems.
Hybrid Quantum-Classical Maximum-Likelihood Detection via Grover-based Adaptive Search for RIS-assisted Broadband Wireless Systems
May 06, 2025The escalating complexity and stringent performance demands of sixth-generation wireless systems necessitate advanced signal processing methods capable of simultaneously achieving high spectral efficiency and low computational complexity, especially under frequency-selective propagation conditions. In this paper, we propose a hybrid quantum-classical detection framework for broadband systems enhanced by reconfigurable intelligent surfaces (RISs). We address the maximum likelihood detection (MLD) problem for RIS-aided broadband wireless communications by formulating it as a quadratic unconstrained binary optimization problem, that is then solved using Grover adaptive search (GAS). To accelerate convergence, we initialize the GAS algorithm with a threshold based on a classical minimum mean-squared error detector. The simulation results show that the proposed hybrid classical-quantum detection scheme achieves near-optimal MLD performance while substantially reducing query complexity. These findings highlight the potential of quantum-enhanced detection strategies combined with RIS technology, offering efficient and near-optimal solutions for broadband wireless communications.
Rethinking Strategic Mechanism Design In The Age Of Large Language Models: New Directions For Communication Systems
Nov 30, 2024



This paper explores the application of large language models (LLMs) in designing strategic mechanisms -- including auctions, contracts, and games -- for specific purposes in communication networks. Traditionally, strategic mechanism design in telecommunications has relied on human expertise to craft solutions based on game theory, auction theory, and contract theory. However, the evolving landscape of telecom networks, characterized by increasing abstraction, emerging use cases, and novel value creation opportunities, calls for more adaptive and efficient approaches. We propose leveraging LLMs to automate or semi-automate the process of strategic mechanism design, from intent specification to final formulation. This paradigm shift introduces both semi-automated and fully-automated design pipelines, raising crucial questions about faithfulness to intents, incentive compatibility, algorithmic stability, and the balance between human oversight and artificial intelligence (AI) autonomy. The paper discusses potential frameworks, such as retrieval-augmented generation (RAG)-based systems, to implement LLM-driven mechanism design in communication networks contexts. We examine key challenges, including LLM limitations in capturing domain-specific constraints, ensuring strategy proofness, and integrating with evolving telecom standards. By providing an in-depth analysis of the synergies and tensions between LLMs and strategic mechanism design within the IoT ecosystem, this work aims to stimulate discussion on the future of AI-driven information economic mechanisms in telecommunications and their potential to address complex, dynamic network management scenarios.
TeleOracle: Fine-Tuned Retrieval-Augmented Generation with Long-Context Support for Network
Nov 04, 2024The telecommunications industry's rapid evolution demands intelligent systems capable of managing complex networks and adapting to emerging technologies. While large language models (LLMs) show promise in addressing these challenges, their deployment in telecom environments faces significant constraints due to edge device limitations and inconsistent documentation. To bridge this gap, we present TeleOracle, a telecom-specialized retrieval-augmented generation (RAG) system built on the Phi-2 small language model (SLM). To improve context retrieval, TeleOracle employs a two-stage retriever that incorporates semantic chunking and hybrid keyword and semantic search. Additionally, we expand the context window during inference to enhance the model's performance on open-ended queries. We also employ low-rank adaption for efficient fine-tuning. A thorough analysis of the model's performance indicates that our RAG framework is effective in aligning Phi-2 to the telecom domain in a downstream question and answer (QnA) task, achieving a 30% improvement in accuracy over the base Phi-2 model, reaching an overall accuracy of 81.20%. Notably, we show that our model not only performs on par with the much larger LLMs but also achieves a higher faithfulness score, indicating higher adherence to the retrieved context.
Contrastive Learning and Adversarial Disentanglement for Privacy-Preserving Task-Oriented Semantic Communications
Oct 30, 2024



Task-oriented semantic communication systems have emerged as a promising approach to achieving efficient and intelligent data transmission, where only information relevant to a specific task is communicated. However, existing methods struggle to fully disentangle task-relevant and task-irrelevant information, leading to privacy concerns and subpar performance. To address this, we propose an information-bottleneck method, named CLAD (contrastive learning and adversarial disentanglement). CLAD leverages contrastive learning to effectively capture task-relevant features while employing adversarial disentanglement to discard task-irrelevant information. Additionally, due to the lack of reliable and reproducible methods to gain insight into the informativeness and minimality of the encoded feature vectors, we introduce a new technique to compute the information retention index (IRI), a comparative metric used as a proxy for the mutual information between the encoded features and the input, reflecting the minimality of the encoded features. The IRI quantifies the minimality and informativeness of the encoded feature vectors across different task-oriented communication techniques. Our extensive experiments demonstrate that CLAD outperforms state-of-the-art baselines in terms of task performance, privacy preservation, and IRI. CLAD achieves a predictive performance improvement of around 2.5-3%, along with a 77-90% reduction in IRI and a 57-76% decrease in adversarial accuracy.
LPUF-AuthNet: A Lightweight PUF-Based IoT Authentication via Tandem Neural Networks and Split Learning
Oct 16, 2024

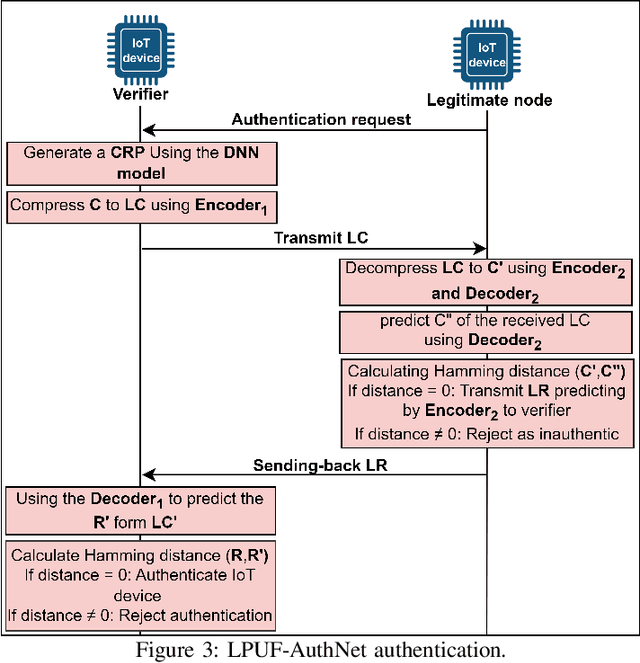

By 2025, the internet of things (IoT) is projected to connect over 75 billion devices globally, fundamentally altering how we interact with our environments in both urban and rural settings. However, IoT device security remains challenging, particularly in the authentication process. Traditional cryptographic methods often struggle with the constraints of IoT devices, such as limited computational power and storage. This paper considers physical unclonable functions (PUFs) as robust security solutions, utilizing their inherent physical uniqueness to authenticate devices securely. However, traditional PUF systems are vulnerable to machine learning (ML) attacks and burdened by large datasets. Our proposed solution introduces a lightweight PUF mechanism, called LPUF-AuthNet, combining tandem neural networks (TNN) with a split learning (SL) paradigm. The proposed approach provides scalability, supports mutual authentication, and enhances security by resisting various types of attacks, paving the way for secure integration into future 6G technologies.
Leveraging Fine-Tuned Retrieval-Augmented Generation with Long-Context Support: For 3GPP Standards
Aug 21, 2024



Recent studies show that large language models (LLMs) struggle with technical standards in telecommunications. We propose a fine-tuned retrieval-augmented generation (RAG) system based on the Phi-2 small language model (SLM) to serve as an oracle for communication networks. Our developed system leverages forward-looking semantic chunking to adaptively determine parsing breakpoints based on embedding similarity, enabling effective processing of diverse document formats. To handle the challenge of multiple similar contexts in technical standards, we employ a re-ranking algorithm to prioritize the most relevant retrieved chunks. Recognizing the limitations of Phi-2's small context window, we implement a recent technique, namely SelfExtend, to expand the context window during inference, which not only boosts the performance but also can accommodate a wider range of user queries and design requirements from customers to specialized technicians. For fine-tuning, we utilize the low-rank adaptation (LoRA) technique to enhance computational efficiency during training and enable effective fine-tuning on small datasets. Our comprehensive experiments demonstrate substantial improvements over existing question-answering approaches in the telecom domain, achieving performance that exceeds larger language models such as GPT-4 (which is about 880 times larger in size). This work presents a novel approach to leveraging SLMs for communication networks, offering a balance of efficiency and performance. This work can serve as a foundation towards agentic language models for networks.
Active ML for 6G: Towards Efficient Data Generation, Acquisition, and Annotation
Jun 05, 2024This paper explores the integration of active machine learning (ML) for 6G networks, an area that remains under-explored yet holds potential. Unlike passive ML systems, active ML can be made to interact with the network environment. It actively selects informative and representative data points for training, thereby reducing the volume of data needed while accelerating the learning process. While active learning research mainly focuses on data annotation, we call for a network-centric active learning framework that considers both annotation (i.e., what is the label) and data acquisition (i.e., which and how many samples to collect). Moreover, we explore the synergy between generative artificial intelligence (AI) and active learning to overcome existing limitations in both active learning and generative AI. This paper also features a case study on a mmWave throughput prediction problem to demonstrate the practical benefits and improved performance of active learning for 6G networks. Furthermore, we discuss how the implications of active learning extend to numerous 6G network use cases. We highlight the potential of active learning based 6G networks to enhance computational efficiency, data annotation and acquisition efficiency, adaptability, and overall network intelligence. We conclude with a discussion on challenges and future research directions for active learning in 6G networks, including development of novel query strategies, distributed learning integration, and inclusion of human- and machine-in-the-loop learning.