 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Pareto-Optimal Token Merging for Edge Transformer Models in Semantic Communication
Sep 11, 2025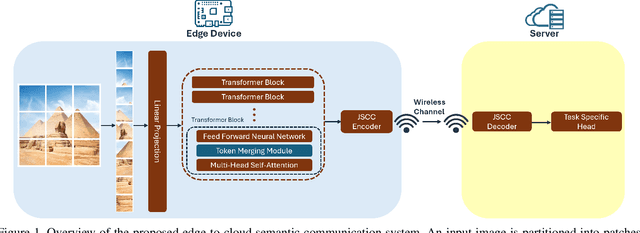
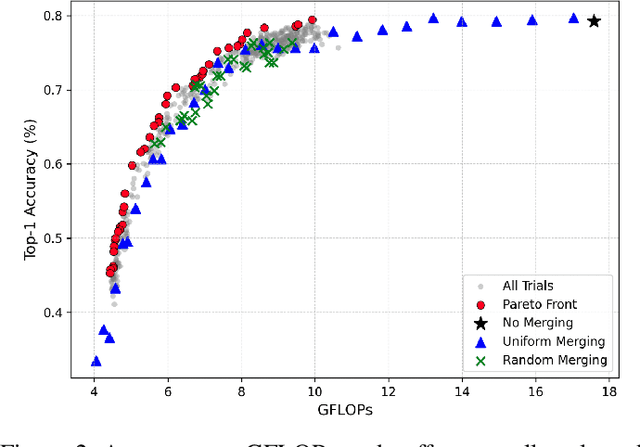
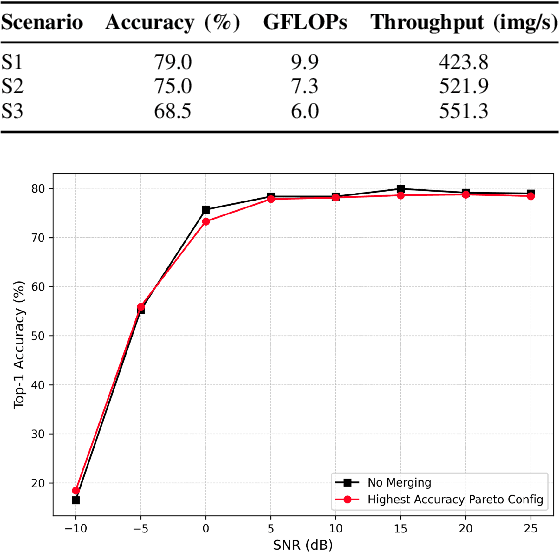
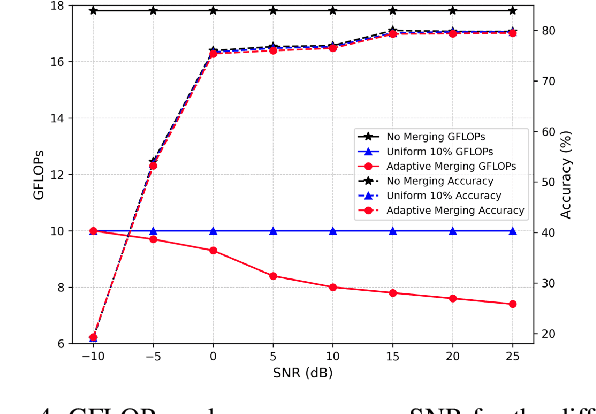
Large-scale transformer models have emerged as a powerful tool for semantic communication systems, enabling edge devices to extract rich representations for robust inference across noisy wireless channels. However, their substantial computational demands remain a major barrier to practical deployment in resource-constrained 6G networks. In this paper, we present a training-free framework for adaptive token merging in pretrained vision transformers to jointly reduce inference time and transmission resource usage. We formulate the selection of per-layer merging proportions as a multi-objective optimization problem to balance accuracy and computational cost. We employ Gaussian process-based Bayesian optimization to construct a Pareto frontier of optimal configurations, enabling flexible runtime adaptation to dynamic application requirements and channel conditions. Extensive experiments demonstrate that our method consistently outperforms other baselines and achieves significant reductions in floating-point operations while maintaining competitive accuracy across a wide range of signal-to-noise ratio (SNR) conditions. Additional results highlight the effectiveness of adaptive policies that adjust merging aggressiveness in response to channel quality, providing a practical mechanism to trade off latency and semantic fidelity on demand. These findings establish a scalable and efficient approach for deploying transformer-based semantic communication in future edge intelligence systems.
TeleOracle: Fine-Tuned Retrieval-Augmented Generation with Long-Context Support for Network
Nov 04, 2024The telecommunications industry's rapid evolution demands intelligent systems capable of managing complex networks and adapting to emerging technologies. While large language models (LLMs) show promise in addressing these challenges, their deployment in telecom environments faces significant constraints due to edge device limitations and inconsistent documentation. To bridge this gap, we present TeleOracle, a telecom-specialized retrieval-augmented generation (RAG) system built on the Phi-2 small language model (SLM). To improve context retrieval, TeleOracle employs a two-stage retriever that incorporates semantic chunking and hybrid keyword and semantic search. Additionally, we expand the context window during inference to enhance the model's performance on open-ended queries. We also employ low-rank adaption for efficient fine-tuning. A thorough analysis of the model's performance indicates that our RAG framework is effective in aligning Phi-2 to the telecom domain in a downstream question and answer (QnA) task, achieving a 30% improvement in accuracy over the base Phi-2 model, reaching an overall accuracy of 81.20%. Notably, we show that our model not only performs on par with the much larger LLMs but also achieves a higher faithfulness score, indicating higher adherence to the retrieved context.
Contrastive Learning and Adversarial Disentanglement for Privacy-Preserving Task-Oriented Semantic Communications
Oct 30, 2024



Task-oriented semantic communication systems have emerged as a promising approach to achieving efficient and intelligent data transmission, where only information relevant to a specific task is communicated. However, existing methods struggle to fully disentangle task-relevant and task-irrelevant information, leading to privacy concerns and subpar performance. To address this, we propose an information-bottleneck method, named CLAD (contrastive learning and adversarial disentanglement). CLAD leverages contrastive learning to effectively capture task-relevant features while employing adversarial disentanglement to discard task-irrelevant information. Additionally, due to the lack of reliable and reproducible methods to gain insight into the informativeness and minimality of the encoded feature vectors, we introduce a new technique to compute the information retention index (IRI), a comparative metric used as a proxy for the mutual information between the encoded features and the input, reflecting the minimality of the encoded features. The IRI quantifies the minimality and informativeness of the encoded feature vectors across different task-oriented communication techniques. Our extensive experiments demonstrate that CLAD outperforms state-of-the-art baselines in terms of task performance, privacy preservation, and IRI. CLAD achieves a predictive performance improvement of around 2.5-3%, along with a 77-90% reduction in IRI and a 57-76% decrease in adversarial accuracy.
Leveraging Fine-Tuned Retrieval-Augmented Generation with Long-Context Support: For 3GPP Standards
Aug 21, 2024



Recent studies show that large language models (LLMs) struggle with technical standards in telecommunications. We propose a fine-tuned retrieval-augmented generation (RAG) system based on the Phi-2 small language model (SLM) to serve as an oracle for communication networks. Our developed system leverages forward-looking semantic chunking to adaptively determine parsing breakpoints based on embedding similarity, enabling effective processing of diverse document formats. To handle the challenge of multiple similar contexts in technical standards, we employ a re-ranking algorithm to prioritize the most relevant retrieved chunks. Recognizing the limitations of Phi-2's small context window, we implement a recent technique, namely SelfExtend, to expand the context window during inference, which not only boosts the performance but also can accommodate a wider range of user queries and design requirements from customers to specialized technicians. For fine-tuning, we utilize the low-rank adaptation (LoRA) technique to enhance computational efficiency during training and enable effective fine-tuning on small datasets. Our comprehensive experiments demonstrate substantial improvements over existing question-answering approaches in the telecom domain, achieving performance that exceeds larger language models such as GPT-4 (which is about 880 times larger in size). This work presents a novel approach to leveraging SLMs for communication networks, offering a balance of efficiency and performance. This work can serve as a foundation towards agentic language models for networks.
Large Language Model-Driven Curriculum Design for Mobile Networks
May 28, 2024
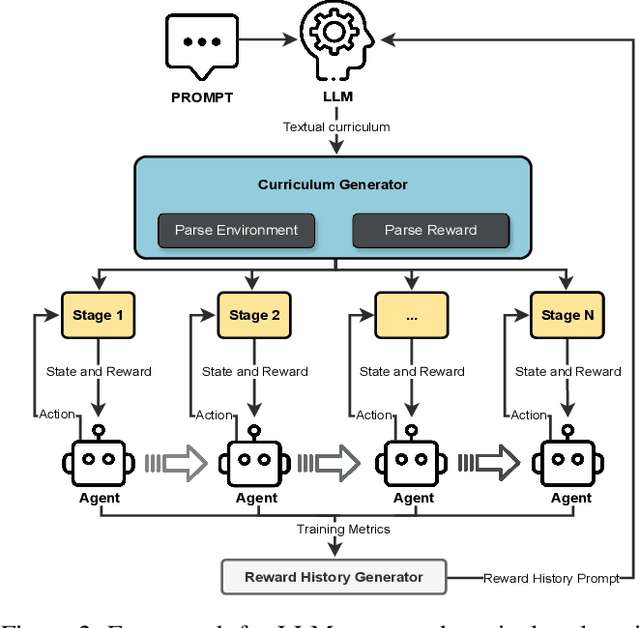
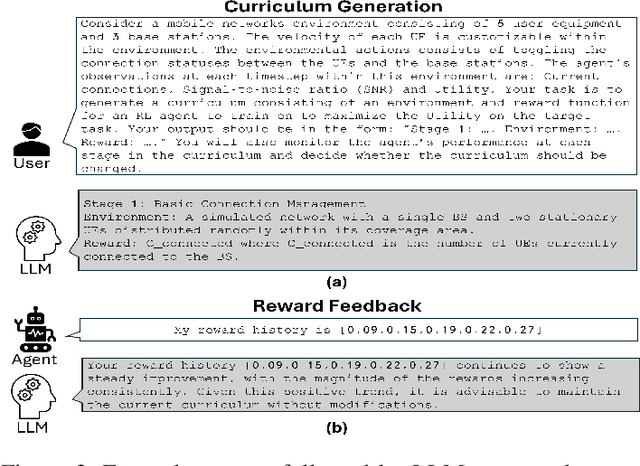
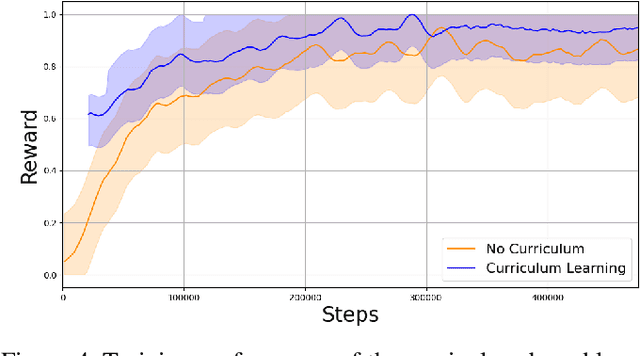
This paper proposes a novel framework that leverages large language models (LLMs) to automate curriculum design, thereby enhancing the application of reinforcement learning (RL) in mobile networks. As mobile networks evolve towards the 6G era, managing their increasing complexity and dynamic nature poses significant challenges. Conventional RL approaches often suffer from slow convergence and poor generalization due to conflicting objectives and the large state and action spaces associated with mobile networks. To address these shortcomings, we introduce curriculum learning, a method that systematically exposes the RL agent to progressively challenging tasks, improving convergence and generalization. However, curriculum design typically requires extensive domain knowledge and manual human effort. Our framework mitigates this by utilizing the generative capabilities of LLMs to automate the curriculum design process, significantly reducing human effort while improving the RL agent's convergence and performance. We deploy our approach within a simulated mobile network environment and demonstrate improved RL convergence rates, generalization to unseen scenarios, and overall performance enhancements. As a case study, we consider autonomous coordination and user association in mobile networks. Our obtained results highlight the potential of combining LLM-based curriculum generation with RL for managing next-generation wireless networks, marking a significant step towards fully autonomous network operations.