 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Differential and Collision Entropy for Finite-Regime QKD in Hybrid Quantum Noisy Channels
Jan 31, 2026In this work, a comparative study between three fundamental entropic measures, differential entropy, quantum Renyi entropy, and quantum collision entropy for a hybrid quantum channel (HQC) was investigated, where hybrid quantum noise (HQN) is characterized by both discrete and continuous variables (CV) noise components. Using a Gaussian mixture model (GMM) to statistically model the HQN, we construct as well as visualize the corresponding pointwise entropic functions in a given 3D probabilistic landscape. When integrated over the relevant state space, these entropic surfaces yield values of the respective global entropy. Through analytical and numerical evaluation, it is demonstrated that the differential entropy approaches the quantum collision entropy under certain mixing conditions, which aligns with the Renyi entropy for order $α= 2$. Within the HQC framework, the results establish a theoretical and computational equivalence between these measures. This provides a unified perspective on quantifying uncertainty in hybrid quantum communication systems. Extending the analysis to the operational domain of finite key QKD, we demonstrated that the same $10\%$ approximation threshold corresponds to an order-of-magnitude change in Eves success probability and a measurable reduction in the secure key rate.
$α^3$-SecBench: A Large-Scale Evaluation Suite of Security, Resilience, and Trust for LLM-based UAV Agents over 6G Networks
Jan 26, 2026Autonomous unmanned aerial vehicle (UAV) systems are increasingly deployed in safety-critical, networked environments where they must operate reliably in the presence of malicious adversaries. While recent benchmarks have evaluated large language model (LLM)-based UAV agents in reasoning, navigation, and efficiency, systematic assessment of security, resilience, and trust under adversarial conditions remains largely unexplored, particularly in emerging 6G-enabled settings. We introduce $α^{3}$-SecBench, the first large-scale evaluation suite for assessing the security-aware autonomy of LLM-based UAV agents under realistic adversarial interference. Building on multi-turn conversational UAV missions from $α^{3}$-Bench, the framework augments benign episodes with 20,000 validated security overlay attack scenarios targeting seven autonomy layers, including sensing, perception, planning, control, communication, edge/cloud infrastructure, and LLM reasoning. $α^{3}$-SecBench evaluates agents across three orthogonal dimensions: security (attack detection and vulnerability attribution), resilience (safe degradation behavior), and trust (policy-compliant tool usage). We evaluate 23 state-of-the-art LLMs from major industrial providers and leading AI labs using thousands of adversarially augmented UAV episodes sampled from a corpus of 113,475 missions spanning 175 threat types. While many models reliably detect anomalous behavior, effective mitigation, vulnerability attribution, and trustworthy control actions remain inconsistent. Normalized overall scores range from 12.9% to 57.1%, highlighting a significant gap between anomaly detection and security-aware autonomous decision-making. We release $α^{3}$-SecBench on GitHub: https://github.com/maferrag/AlphaSecBench
AgentDrive: An Open Benchmark Dataset for Agentic AI Reasoning with LLM-Generated Scenarios in Autonomous Systems
Jan 23, 2026The rapid advancement of large language models (LLMs) has sparked growing interest in their integration into autonomous systems for reasoning-driven perception, planning, and decision-making. However, evaluating and training such agentic AI models remains challenging due to the lack of large-scale, structured, and safety-critical benchmarks. This paper introduces AgentDrive, an open benchmark dataset containing 300,000 LLM-generated driving scenarios designed for training, fine-tuning, and evaluating autonomous agents under diverse conditions. AgentDrive formalizes a factorized scenario space across seven orthogonal axes: scenario type, driver behavior, environment, road layout, objective, difficulty, and traffic density. An LLM-driven prompt-to-JSON pipeline generates semantically rich, simulation-ready specifications that are validated against physical and schema constraints. Each scenario undergoes simulation rollouts, surrogate safety metric computation, and rule-based outcome labeling. To complement simulation-based evaluation, we introduce AgentDrive-MCQ, a 100,000-question multiple-choice benchmark spanning five reasoning dimensions: physics, policy, hybrid, scenario, and comparative reasoning. We conduct a large-scale evaluation of fifty leading LLMs on AgentDrive-MCQ. Results show that while proprietary frontier models perform best in contextual and policy reasoning, advanced open models are rapidly closing the gap in structured and physics-grounded reasoning. We release the AgentDrive dataset, AgentDrive-MCQ benchmark, evaluation code, and related materials at https://github.com/maferrag/AgentDrive
LiQSS: Post-Transformer Linear Quantum-Inspired State-Space Tensor Networks for Real-Time 6G
Jan 18, 2026Proactive and agentic control in Sixth-Generation (6G) Open Radio Access Networks (O-RAN) requires control-grade prediction under stringent Near-Real-Time (Near-RT) latency and computational constraints. While Transformer-based models are effective for sequence modeling, their quadratic complexity limits scalability in Near-RT RAN Intelligent Controller (RIC) analytics. This paper investigates a post-Transformer design paradigm for efficient radio telemetry forecasting. We propose a quantum-inspired many-body state-space tensor network that replaces self-attention with stable structured state-space dynamics kernels, enabling linear-time sequence modeling. Tensor-network factorizations in the form of Tensor Train (TT) / Matrix Product State (MPS) representations are employed to reduce parameterization and data movement in both input projections and prediction heads, while lightweight channel gating and mixing layers capture non-stationary cross-Key Performance Indicator (KPI) dependencies. The proposed model is instantiated as an agentic perceive-predict xApp and evaluated on a bespoke O-RAN KPI time-series dataset comprising 59,441 sliding windows across 13 KPIs, using Reference Signal Received Power (RSRP) forecasting as a representative use case. Our proposed Linear Quantum-Inspired State-Space (LiQSS) model is 10.8x-15.8x smaller and approximately 1.4x faster than prior structured state-space baselines. Relative to Transformer-based models, LiQSS achieves up to a 155x reduction in parameter count and up to 2.74x faster inference, without sacrificing forecasting accuracy.
$α^3$-Bench: A Unified Benchmark of Safety, Robustness, and Efficiency for LLM-Based UAV Agents over 6G Networks
Jan 01, 2026Large Language Models (LLMs) are increasingly used as high level controllers for autonomous Unmanned Aerial Vehicle (UAV) missions. However, existing evaluations rarely assess whether such agents remain safe, protocol compliant, and effective under realistic next generation networking constraints. This paper introduces $α^3$-Bench, a benchmark for evaluating LLM driven UAV autonomy as a multi turn conversational reasoning and control problem operating under dynamic 6G conditions. Each mission is formulated as a language mediated control loop between an LLM based UAV agent and a human operator, where decisions must satisfy strict schema validity, mission policies, speaker alternation, and safety constraints while adapting to fluctuating network slices, latency, jitter, packet loss, throughput, and edge load variations. To reflect modern agentic workflows, $α^3$-Bench integrates a dual action layer supporting both tool calls and agent to agent coordination, enabling evaluation of tool use consistency and multi agent interactions. We construct a large scale corpus of 113k conversational UAV episodes grounded in UAVBench scenarios and evaluate 17 state of the art LLMs using a fixed subset of 50 episodes per scenario under deterministic decoding. We propose a composite $α^3$ metric that unifies six pillars: Task Outcome, Safety Policy, Tool Consistency, Interaction Quality, Network Robustness, and Communication Cost, with efficiency normalized scores per second and per thousand tokens. Results show that while several models achieve high mission success and safety compliance, robustness and efficiency vary significantly under degraded 6G conditions, highlighting the need for network aware and resource efficient LLM based UAV agents. The dataset is publicly available on GitHub : https://github.com/maferrag/AlphaBench
Lightweight Foundation Model for Wireless Time Series Downstream Tasks on Edge Devices
Nov 18, 2025



While machine learning is widely used to optimize wireless networks, training a separate model for each task in communication and localization is becoming increasingly unsustainable due to the significant costs associated with training and deployment. Foundation models offer a more scalable alternative by enabling a single model to be adapted across multiple tasks through fine-tuning with limited samples. However, current foundation models mostly rely on large-scale Transformer architectures, resulting in computationally intensive models unsuitable for deployment on typical edge devices. This paper presents a lightweight foundation model based on simple Multi-Layer-Perceptron (MLP) encoders that independently process input patches. Our model supports 4 types of downstream tasks (long-range technology recognition, short-range technology recognition, modulation recognition and line-of-sight-detection) from multiple input types (IQ and CIR) and different sampling rates. We show that, unlike Transformers, which can exhibit performance drops as downstream tasks are added, our MLP model maintains robust generalization performance, achieving over 97% accurate fine-tuning results for previously unseen data classes. These results are achieved despite having only 21K trainable parameters, allowing an inference time of 0.33 ms on common edge devices, making the model suitable for constrained real-time deployments.
UAVBench: An Open Benchmark Dataset for Autonomous and Agentic AI UAV Systems via LLM-Generated Flight Scenarios
Nov 14, 2025



Autonomous aerial systems increasingly rely on large language models (LLMs) for mission planning, perception, and decision-making, yet the lack of standardized and physically grounded benchmarks limits systematic evaluation of their reasoning capabilities. To address this gap, we introduce UAVBench, an open benchmark dataset comprising 50,000 validated UAV flight scenarios generated through taxonomy-guided LLM prompting and multi-stage safety validation. Each scenario is encoded in a structured JSON schema that includes mission objectives, vehicle configuration, environmental conditions, and quantitative risk labels, providing a unified representation of UAV operations across diverse domains. Building on this foundation, we present UAVBench_MCQ, a reasoning-oriented extension containing 50,000 multiple-choice questions spanning ten cognitive and ethical reasoning styles, ranging from aerodynamics and navigation to multi-agent coordination and integrated reasoning. This framework enables interpretable and machine-checkable assessment of UAV-specific cognition under realistic operational contexts. We evaluate 32 state-of-the-art LLMs, including GPT-5, ChatGPT-4o, Gemini 2.5 Flash, DeepSeek V3, Qwen3 235B, and ERNIE 4.5 300B, and find strong performance in perception and policy reasoning but persistent challenges in ethics-aware and resource-constrained decision-making. UAVBench establishes a reproducible and physically grounded foundation for benchmarking agentic AI in autonomous aerial systems and advancing next-generation UAV reasoning intelligence. To support open science and reproducibility, we release the UAVBench dataset, the UAVBench_MCQ benchmark, evaluation scripts, and all related materials on GitHub at https://github.com/maferrag/UAVBench
Reading Radio from Camera: Visually-Grounded, Lightweight, and Interpretable RSSI Prediction
Oct 29, 2025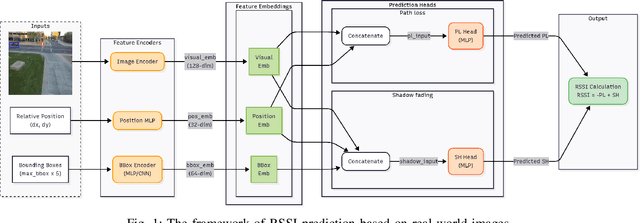
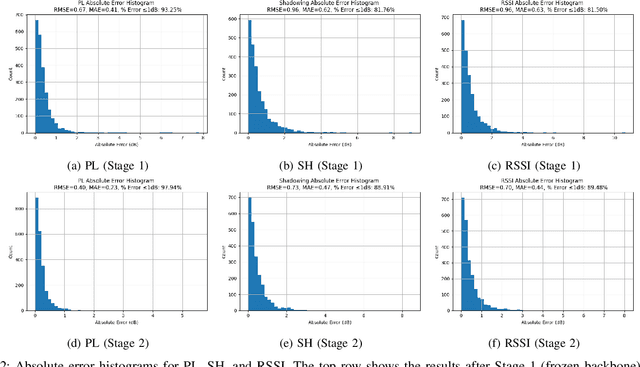
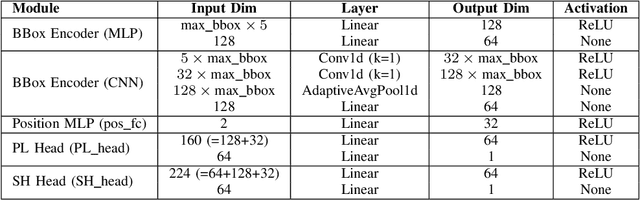
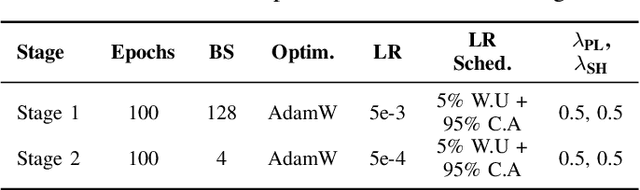
Accurate, real-time wireless signal prediction is essential for next-generation networks. However, existing vision-based frameworks often rely on computationally intensive models and are also sensitive to environmental interference. To overcome these limitations, we propose a novel, physics-guided and light-weighted framework that predicts the received signal strength indicator (RSSI) from camera images. By decomposing RSSI into its physically interpretable components, path loss and shadow fading, we significantly reduce the model's learning difficulty and exhibit interpretability. Our approach establishes a new state-of-the-art by demonstrating exceptional robustness to environmental interference, a critical flaw in prior work. Quantitatively, our model reduces the prediction root mean squared error (RMSE) by 50.3% under conventional conditions and still achieves an 11.5% lower RMSE than the previous benchmark's interference-eliminated results. This superior performance is achieved with a remarkably lightweight framework, utilizing a MobileNet-based model up to 19 times smaller than competing solutions. The combination of high accuracy, robustness to interference, and computational efficiency makes our framework highly suitable for real-time, on-device deployment in edge devices, paving the way for more intelligent and reliable wireless communication systems.
Communication-Efficient Zero-Order and First-Order Federated Learning Methods over Wireless Networks
Aug 11, 2025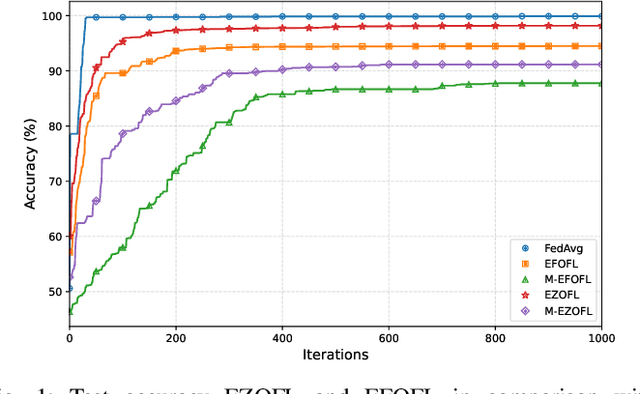
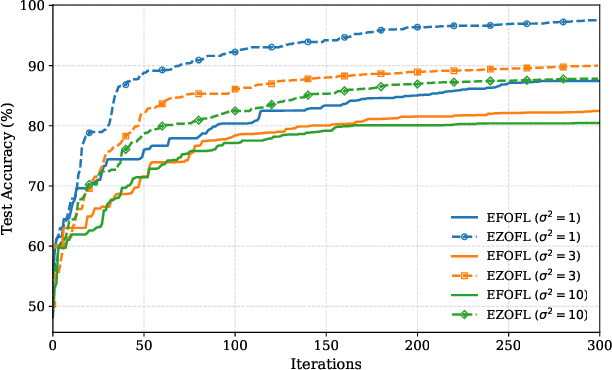
Federated Learning (FL) is an emerging learning framework that enables edge devices to collaboratively train ML models without sharing their local data. FL faces, however, a significant challenge due to the high amount of information that must be exchanged between the devices and the aggregator in the training phase, which can exceed the limited capacity of wireless systems. In this paper, two communication-efficient FL methods are considered where communication overhead is reduced by communicating scalar values instead of long vectors and by allowing high number of users to send information simultaneously. The first approach employs a zero-order optimization technique with two-point gradient estimator, while the second involves a first-order gradient computation strategy. The novelty lies in leveraging channel information in the learning algorithms, eliminating hence the need for additional resources to acquire channel state information (CSI) and to remove its impact, as well as in considering asynchronous devices. We provide a rigorous analytical framework for the two methods, deriving convergence guarantees and establishing appropriate performance bounds.
Reasoning Language Models for Root Cause Analysis in 5G Wireless Networks
Jul 29, 2025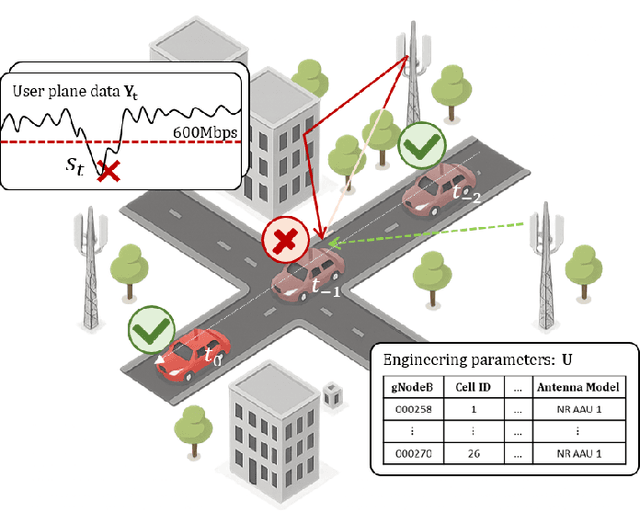
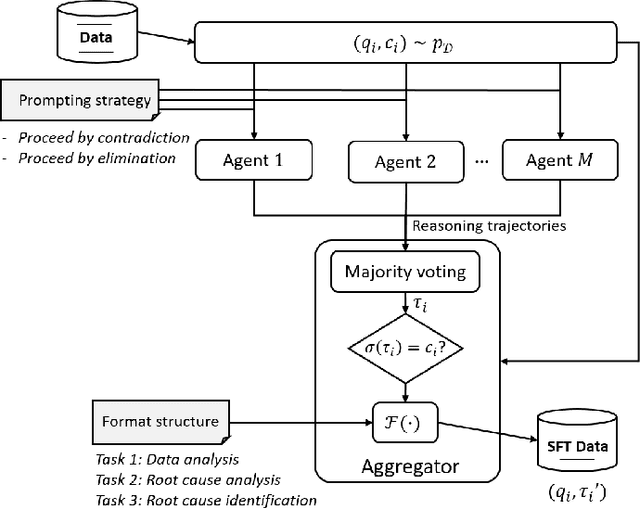

Root Cause Analysis (RCA) in mobile networks remains a challenging task due to the need for interpretability, domain expertise, and causal reasoning. In this work, we propose a lightweight framework that leverages Large Language Models (LLMs) for RCA. To do so, we introduce TeleLogs, a curated dataset of annotated troubleshooting problems designed to benchmark RCA capabilities. Our evaluation reveals that existing open-source reasoning LLMs struggle with these problems, underscoring the need for domain-specific adaptation. To address this issue, we propose a two-stage training methodology that combines supervised fine-tuning with reinforcement learning to improve the accuracy and reasoning quality of LLMs. The proposed approach fine-tunes a series of RCA models to integrate domain knowledge and generate structured, multi-step diagnostic explanations, improving both interpretability and effectiveness. Extensive experiments across multiple LLM sizes show significant performance gains over state-of-the-art reasoning and non-reasoning models, including strong generalization to randomized test variants. These results demonstrate the promise of domain-adapted, reasoning-enhanced LLMs for practical and explainable RCA in network operation and management.