 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKVCompose: Efficient Structured KV Cache Compression with Composite Tokens
Sep 05, 2025Large language models (LLMs) rely on key-value (KV) caches for efficient autoregressive decoding; however, cache size grows linearly with context length and model depth, becoming a major bottleneck in long-context inference. Prior KV cache compression methods either enforce rigid heuristics, disrupt tensor layouts with per-attention-head variability, or require specialized compute kernels. We propose a simple, yet effective, KV cache compression framework based on attention-guided, layer-adaptive composite tokens. Our method aggregates attention scores to estimate token importance, selects head-specific tokens independently, and aligns them into composite tokens that respect the uniform cache structure required by existing inference engines. A global allocation mechanism further adapts retention budgets across layers, assigning more capacity to layers with informative tokens. This approach achieves significant memory reduction while preserving accuracy, consistently outperforming prior structured and semi-structured methods. Crucially, our approach remains fully compatible with standard inference pipelines, offering a practical and scalable solution for efficient long-context LLM deployment.
Reasoning Language Models for Root Cause Analysis in 5G Wireless Networks
Jul 29, 2025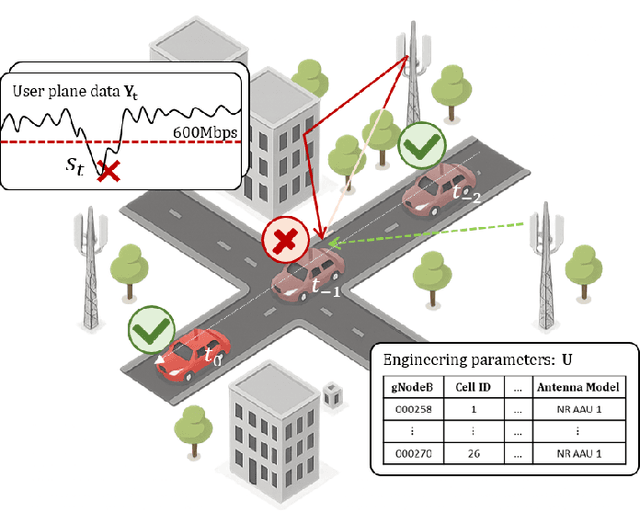
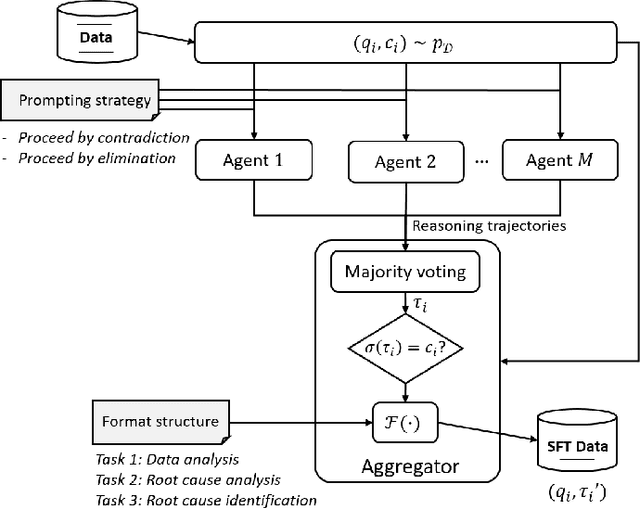

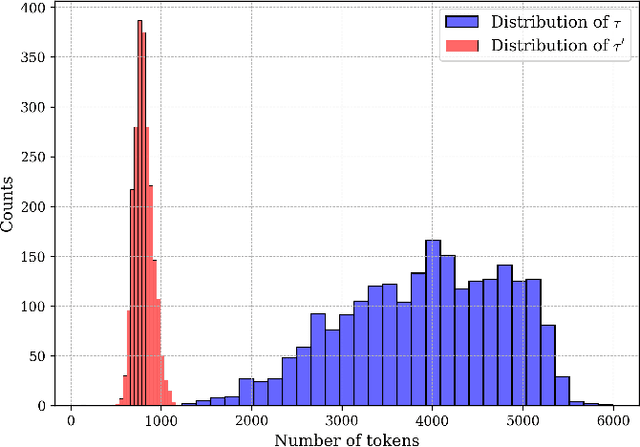
Root Cause Analysis (RCA) in mobile networks remains a challenging task due to the need for interpretability, domain expertise, and causal reasoning. In this work, we propose a lightweight framework that leverages Large Language Models (LLMs) for RCA. To do so, we introduce TeleLogs, a curated dataset of annotated troubleshooting problems designed to benchmark RCA capabilities. Our evaluation reveals that existing open-source reasoning LLMs struggle with these problems, underscoring the need for domain-specific adaptation. To address this issue, we propose a two-stage training methodology that combines supervised fine-tuning with reinforcement learning to improve the accuracy and reasoning quality of LLMs. The proposed approach fine-tunes a series of RCA models to integrate domain knowledge and generate structured, multi-step diagnostic explanations, improving both interpretability and effectiveness. Extensive experiments across multiple LLM sizes show significant performance gains over state-of-the-art reasoning and non-reasoning models, including strong generalization to randomized test variants. These results demonstrate the promise of domain-adapted, reasoning-enhanced LLMs for practical and explainable RCA in network operation and management.
TeleMath: A Benchmark for Large Language Models in Telecom Mathematical Problem Solving
Jun 12, 2025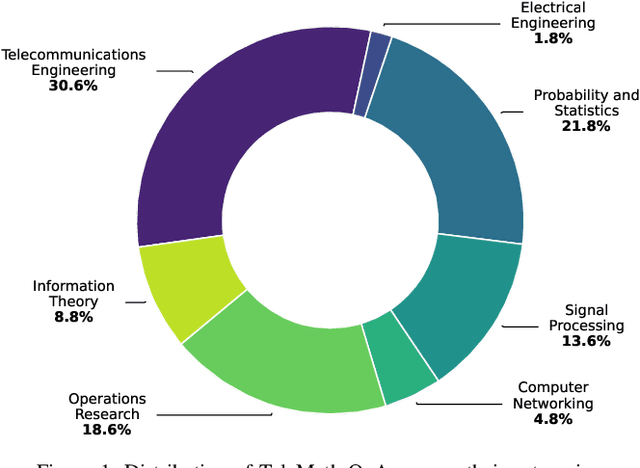


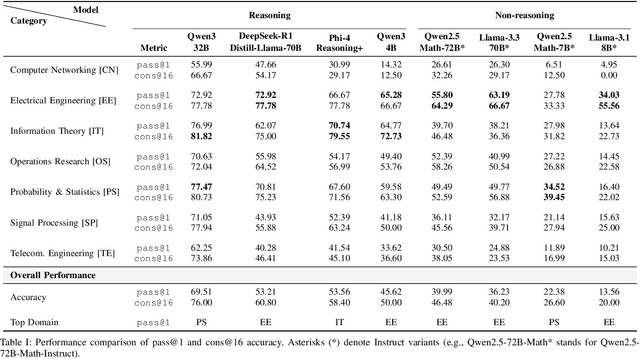
The increasing adoption of artificial intelligence in telecommunications has raised interest in the capability of Large Language Models (LLMs) to address domain-specific, mathematically intensive tasks. Although recent advancements have improved the performance of LLMs in general mathematical reasoning, their effectiveness within specialized domains, such as signal processing, network optimization, and performance analysis, remains largely unexplored. To address this gap, we introduce TeleMath, the first benchmark dataset specifically designed to evaluate LLM performance in solving mathematical problems with numerical solutions in the telecommunications domain. Comprising 500 question-answer (QnA) pairs, TeleMath covers a wide spectrum of topics in the telecommunications field. This paper outlines the proposed QnAs generation pipeline, starting from a selected seed of problems crafted by Subject Matter Experts. The evaluation of a wide range of open-source LLMs reveals that best performance on TeleMath is achieved by recent models explicitly designed for mathematical or logical reasoning. In contrast, general-purpose models, even those with a large number of parameters, often struggle with these challenges. We have released the dataset and the evaluation code to ease result reproducibility and support future research.
Telco-oRAG: Optimizing Retrieval-augmented Generation for Telecom Queries via Hybrid Retrieval and Neural Routing
May 17, 2025



Artificial intelligence will be one of the key pillars of the next generation of mobile networks (6G), as it is expected to provide novel added-value services and improve network performance. In this context, large language models have the potential to revolutionize the telecom landscape through intent comprehension, intelligent knowledge retrieval, coding proficiency, and cross-domain orchestration capabilities. This paper presents Telco-oRAG, an open-source Retrieval-Augmented Generation (RAG) framework optimized for answering technical questions in the telecommunications domain, with a particular focus on 3GPP standards. Telco-oRAG introduces a hybrid retrieval strategy that combines 3GPP domain-specific retrieval with web search, supported by glossary-enhanced query refinement and a neural router for memory-efficient retrieval. Our results show that Telco-oRAG improves the accuracy in answering 3GPP-related questions by up to 17.6% and achieves a 10.6% improvement in lexicon queries compared to baselines. Furthermore, Telco-oRAG reduces memory usage by 45% through targeted retrieval of relevant 3GPP series compared to baseline RAG, and enables open-source LLMs to reach GPT-4-level accuracy on telecom benchmarks.
Goal-Oriented Time-Series Forecasting: Foundation Framework Design
Apr 24, 2025Traditional time-series forecasting often focuses only on minimizing prediction errors, ignoring the specific requirements of real-world applications that employ them. This paper presents a new training methodology, which allows a forecasting model to dynamically adjust its focus based on the importance of forecast ranges specified by the end application. Unlike previous methods that fix these ranges beforehand, our training approach breaks down predictions over the entire signal range into smaller segments, which are then dynamically weighted and combined to produce accurate forecasts. We tested our method on standard datasets, including a new dataset from wireless communication, and found that not only it improves prediction accuracy but also improves the performance of end application employing the forecasting model. This research provides a basis for creating forecasting systems that better connect prediction and decision-making in various practical applications.
Capacity and Power Consumption of Multi-Layer 6G Networks Using the Upper Mid-Band
Nov 14, 2024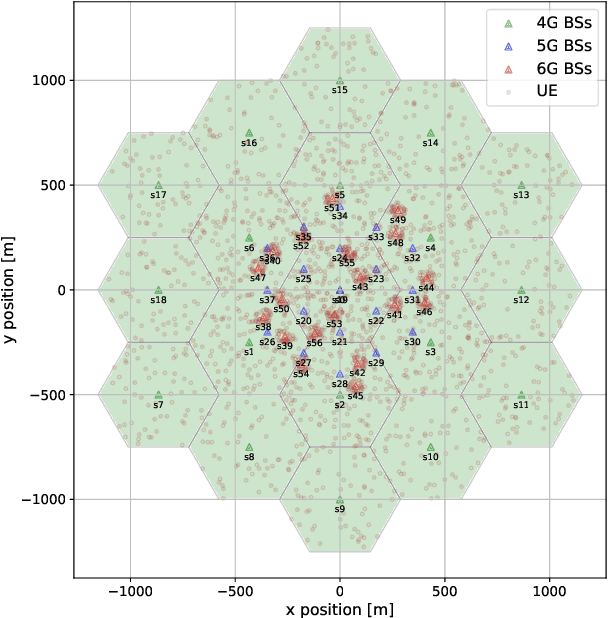
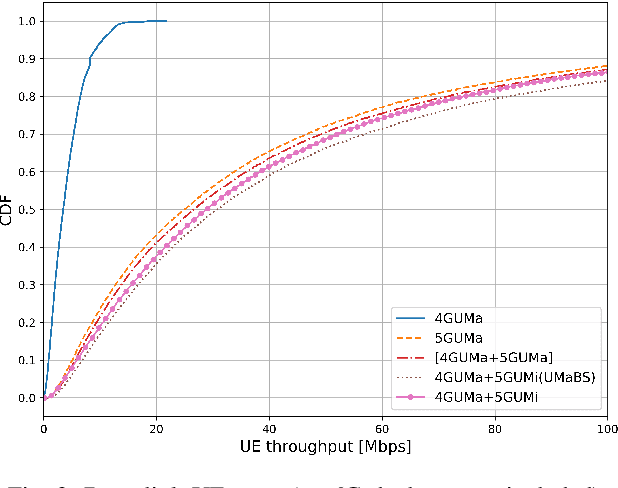
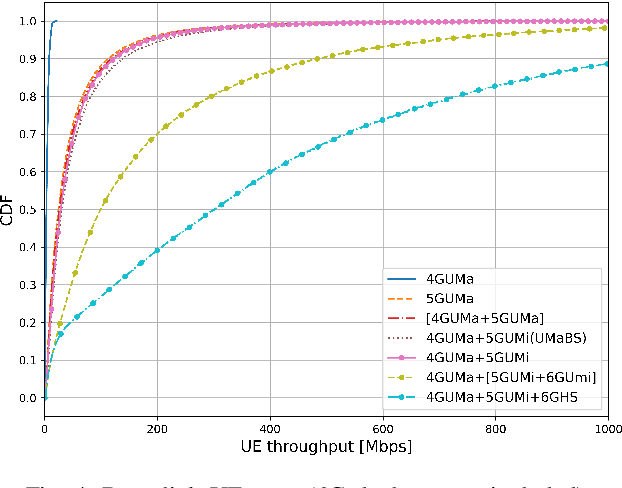
This paper presents a new system model to evaluate the capacity and power consumption of multi-layer 6G networks utilising the upper mid-band (FR3). The model captures heterogeneous 4G, 5G, and 6G deployments, analyzing their performance under different deployment strategies. Our results show that strategic 6G deployments, non-co-located with existing 5G sites, significantly enhance throughput, with median and peak user rates of 300 Mbps and exceeding 1 Gbps, respectively. We also emphasize the importance of priority-based cell reselection and beam configuration to fully leverage 6G capabilities. While 6G implementation increases power consumption by 33%, non-colocated deployments strike a balance between performance and power consumption.
Hermes: A Large Language Model Framework on the Journey to Autonomous Networks
Nov 10, 2024



The drive toward automating cellular network operations has grown with the increasing complexity of these systems. Despite advancements, full autonomy currently remains out of reach due to reliance on human intervention for modeling network behaviors and defining policies to meet target requirements. Network Digital Twins (NDTs) have shown promise in enhancing network intelligence, but the successful implementation of this technology is constrained by use case-specific architectures, limiting its role in advancing network autonomy. A more capable network intelligence, or "telecommunications brain", is needed to enable seamless, autonomous management of cellular network. Large Language Models (LLMs) have emerged as potential enablers for this vision but face challenges in network modeling, especially in reasoning and handling diverse data types. To address these gaps, we introduce Hermes, a chain of LLM agents that uses "blueprints" for constructing NDT instances through structured and explainable logical steps. Hermes allows automatic, reliable, and accurate network modeling of diverse use cases and configurations, thus marking progress toward fully autonomous network operations.
Modelling the 5G Energy Consumption using Real-world Data: Energy Fingerprint is All You Need
Jun 13, 2024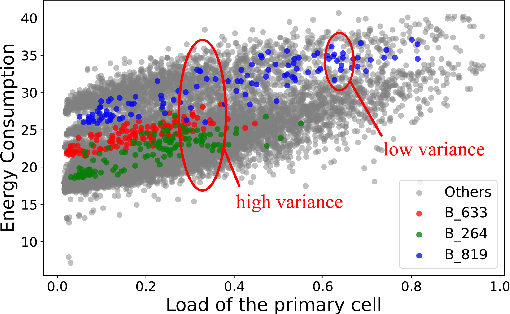
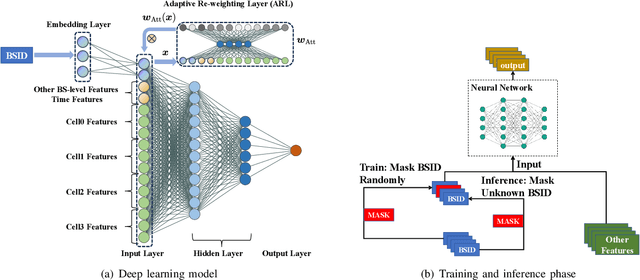
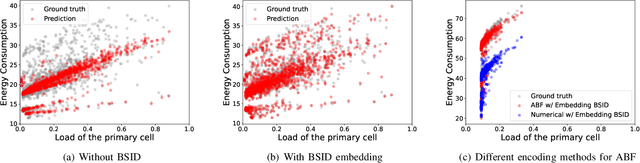
The introduction of fifth-generation (5G) radio technology has revolutionized communications, bringing unprecedented automation, capacity, connectivity, and ultra-fast, reliable communications. However, this technological leap comes with a substantial increase in energy consumption, presenting a significant challenge. To improve the energy efficiency of 5G networks, it is imperative to develop sophisticated models that accurately reflect the influence of base station (BS) attributes and operational conditions on energy usage.Importantly, addressing the complexity and interdependencies of these diverse features is particularly challenging, both in terms of data processing and model architecture design. This paper proposes a novel 5G base stations energy consumption modelling method by learning from a real-world dataset used in the ITU 5G Base Station Energy Consumption Modelling Challenge in which our model ranked second. Unlike existing methods that omit the Base Station Identifier (BSID) information and thus fail to capture the unique energy fingerprint in different base stations, we incorporate the BSID into the input features and encoding it with an embedding layer for precise representation. Additionally, we introduce a novel masked training method alongside an attention mechanism to further boost the model's generalization capabilities and accuracy. After evaluation, our method demonstrates significant improvements over existing models, reducing Mean Absolute Percentage Error (MAPE) from 12.75% to 4.98%, leading to a performance gain of more than 60%.
Waste Factor and Waste Figure: A Unified Theory for Modeling and Analyzing Wasted Power in Radio Access Networks for Improved Sustainability
May 13, 2024



This paper introduces Waste Factor (W), also denoted as Waste Figure (WF) in dB, a promising new metric for quantifying energy efficiency in a wide range of circuits and systems applications, including data centers and RANs. Also, the networks used to connect data centers and AI computing engines with users for ML applications must become more power efficient. This paper illustrates the limitations of existing energy efficiency metrics that inadequately capture the intricate energy dynamics of RAN components. We delineate the methodology for applying W across various network configurations, including MISO, SIMO, and MIMO systems, and demonstrate the effectiveness of W in identifying energy optimization opportunities. Our findings reveal that W not only offers nuanced insights into the energy performance of RANs but also facilitates informed decision-making for network design and operational efficiency. Furthermore, we show how W can be integrated with other KPIs to guide the development of optimal strategies for enhancing network energy efficiency under different operational conditions. Additionally, we present simulation results for a distributed multi-user MIMO system at 3.5, 17, and 28 GHz, demonstrating overall network power efficiency on a per square kilometer basis, and show how overall W decreases with an increasing number of base stations and increasing carrier frequency. This paper shows that adopting W as a figure of merit can significantly contribute to the sustainability and energy optimization of next-generation wireless communication networks, paving the way for greener and more sustainable, energy-efficient 5G and 6G technologies.
Telco-RAG: Navigating the Challenges of Retrieval-Augmented Language Models for Telecommunications
Apr 26, 2024



The application of Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) systems in the telecommunication domain presents unique challenges, primarily due to the complex nature of telecom standard documents and the rapid evolution of the field. The paper introduces Telco-RAG, an open-source RAG framework designed to handle the specific needs of telecommunications standards, particularly 3rd Generation Partnership Project (3GPP) documents. Telco-RAG addresses the critical challenges of implementing a RAG pipeline on highly technical content, paving the way for applying LLMs in telecommunications and offering guidelines for RAG implementation in other technical domains.