 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandits in Flux: Adversarial Constraints in Dynamic Environments
Jan 27, 2026We investigate the challenging problem of adversarial multi-armed bandits operating under time-varying constraints, a scenario motivated by numerous real-world applications. To address this complex setting, we propose a novel primal-dual algorithm that extends online mirror descent through the incorporation of suitable gradient estimators and effective constraint handling. We provide theoretical guarantees establishing sublinear dynamic regret and sublinear constraint violation for our proposed policy. Our algorithm achieves state-of-the-art performance in terms of both regret and constraint violation. Empirical evaluations demonstrate the superiority of our approach.
KVCompose: Efficient Structured KV Cache Compression with Composite Tokens
Sep 05, 2025Large language models (LLMs) rely on key-value (KV) caches for efficient autoregressive decoding; however, cache size grows linearly with context length and model depth, becoming a major bottleneck in long-context inference. Prior KV cache compression methods either enforce rigid heuristics, disrupt tensor layouts with per-attention-head variability, or require specialized compute kernels. We propose a simple, yet effective, KV cache compression framework based on attention-guided, layer-adaptive composite tokens. Our method aggregates attention scores to estimate token importance, selects head-specific tokens independently, and aligns them into composite tokens that respect the uniform cache structure required by existing inference engines. A global allocation mechanism further adapts retention budgets across layers, assigning more capacity to layers with informative tokens. This approach achieves significant memory reduction while preserving accuracy, consistently outperforming prior structured and semi-structured methods. Crucially, our approach remains fully compatible with standard inference pipelines, offering a practical and scalable solution for efficient long-context LLM deployment.
A Multi-Armed Bandit Framework for Online Optimisation in Green Integrated Terrestrial and Non-Terrestrial Networks
Jun 10, 2025Integrated terrestrial and non-terrestrial network (TN-NTN) architectures offer a promising solution for expanding coverage and improving capacity for the network. While non-terrestrial networks (NTNs) are primarily exploited for these specific reasons, their role in alleviating terrestrial network (TN) load and enabling energy-efficient operation has received comparatively less attention. In light of growing concerns associated with the densification of terrestrial deployments, this work aims to explore the potential of NTNs in supporting a more sustainable network. In this paper, we propose a novel online optimisation framework for integrated TN-NTN architectures, built on a multi-armed bandit (MAB) formulation and leveraging the Bandit-feedback Constrained Online Mirror Descent (BCOMD) algorithm. Our approach adaptively optimises key system parameters--including bandwidth allocation, user equipment (UE) association, and macro base station (MBS) shutdown--to balance network capacity and energy efficiency in real time. Extensive system-level simulations over a 24-hour period show that our framework significantly reduces the proportion of unsatisfied UEs during peak hours and achieves up to 19% throughput gains and 5% energy savings in low-traffic periods, outperforming standard network settings following 3GPP recommendations.
Telco-oRAG: Optimizing Retrieval-augmented Generation for Telecom Queries via Hybrid Retrieval and Neural Routing
May 17, 2025Artificial intelligence will be one of the key pillars of the next generation of mobile networks (6G), as it is expected to provide novel added-value services and improve network performance. In this context, large language models have the potential to revolutionize the telecom landscape through intent comprehension, intelligent knowledge retrieval, coding proficiency, and cross-domain orchestration capabilities. This paper presents Telco-oRAG, an open-source Retrieval-Augmented Generation (RAG) framework optimized for answering technical questions in the telecommunications domain, with a particular focus on 3GPP standards. Telco-oRAG introduces a hybrid retrieval strategy that combines 3GPP domain-specific retrieval with web search, supported by glossary-enhanced query refinement and a neural router for memory-efficient retrieval. Our results show that Telco-oRAG improves the accuracy in answering 3GPP-related questions by up to 17.6% and achieves a 10.6% improvement in lexicon queries compared to baselines. Furthermore, Telco-oRAG reduces memory usage by 45% through targeted retrieval of relevant 3GPP series compared to baseline RAG, and enables open-source LLMs to reach GPT-4-level accuracy on telecom benchmarks.
Goal-Oriented Time-Series Forecasting: Foundation Framework Design
Apr 24, 2025Traditional time-series forecasting often focuses only on minimizing prediction errors, ignoring the specific requirements of real-world applications that employ them. This paper presents a new training methodology, which allows a forecasting model to dynamically adjust its focus based on the importance of forecast ranges specified by the end application. Unlike previous methods that fix these ranges beforehand, our training approach breaks down predictions over the entire signal range into smaller segments, which are then dynamically weighted and combined to produce accurate forecasts. We tested our method on standard datasets, including a new dataset from wireless communication, and found that not only it improves prediction accuracy but also improves the performance of end application employing the forecasting model. This research provides a basis for creating forecasting systems that better connect prediction and decision-making in various practical applications.
Federated Learning for Cooperative Inference Systems: The Case of Early Exit Networks
May 07, 2024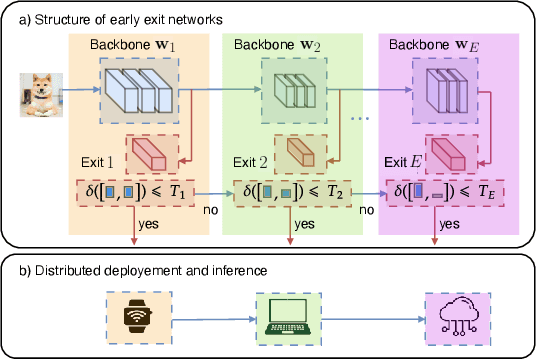
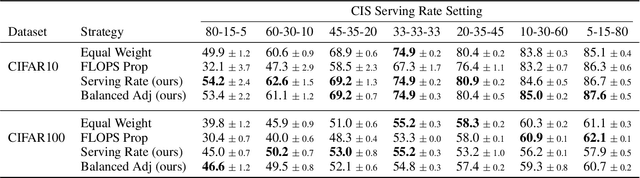
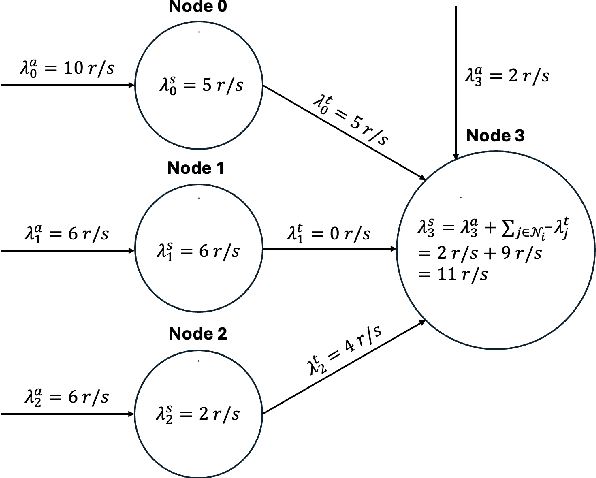
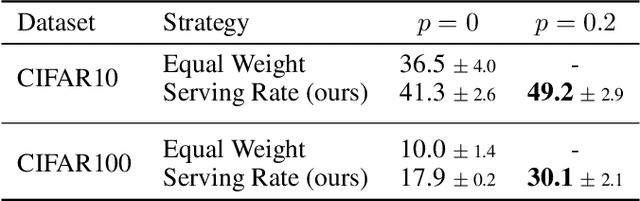
As Internet of Things (IoT) technology advances, end devices like sensors and smartphones are progressively equipped with AI models tailored to their local memory and computational constraints. Local inference reduces communication costs and latency; however, these smaller models typically underperform compared to more sophisticated models deployed on edge servers or in the cloud. Cooperative Inference Systems (CISs) address this performance trade-off by enabling smaller devices to offload part of their inference tasks to more capable devices. These systems often deploy hierarchical models that share numerous parameters, exemplified by Deep Neural Networks (DNNs) that utilize strategies like early exits or ordered dropout. In such instances, Federated Learning (FL) may be employed to jointly train the models within a CIS. Yet, traditional training methods have overlooked the operational dynamics of CISs during inference, particularly the potential high heterogeneity in serving rates across clients. To address this gap, we propose a novel FL approach designed explicitly for use in CISs that accounts for these variations in serving rates. Our framework not only offers rigorous theoretical guarantees, but also surpasses state-of-the-art (SOTA) training algorithms for CISs, especially in scenarios where inference request rates or data availability are uneven among clients.
AÇAI: Ascent Similarity Caching with Approximate Indexes
Jul 02, 2021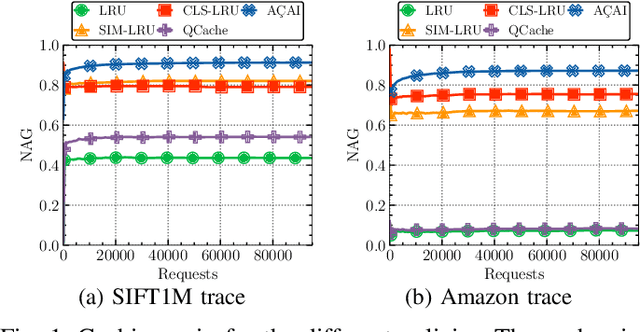
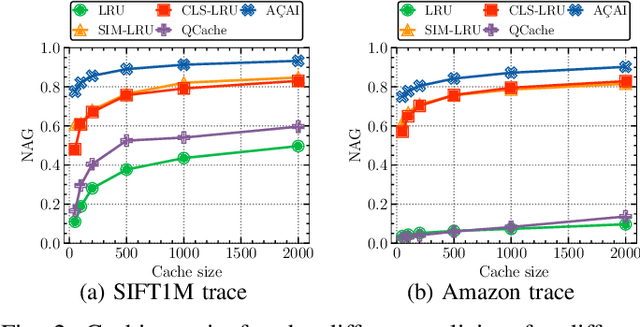
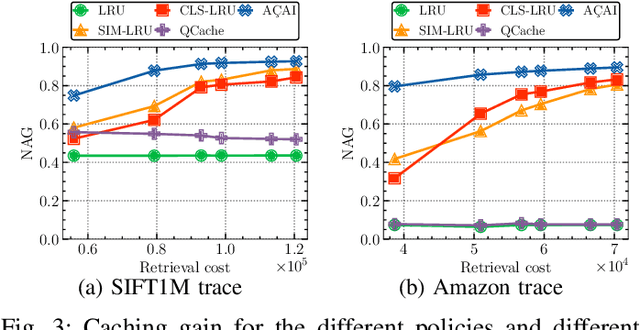
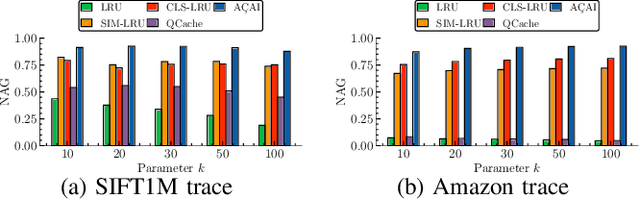
Similarity search is a key operation in multimedia retrieval systems and recommender systems, and it will play an important role also for future machine learning and augmented reality applications. When these systems need to serve large objects with tight delay constraints, edge servers close to the end-user can operate as similarity caches to speed up the retrieval. In this paper we present A\c{C}AI, a new similarity caching policy which improves on the state of the art by using (i) an (approximate) index for the whole catalog to decide which objects to serve locally and which to retrieve from the remote server, and (ii) a mirror ascent algorithm to update the set of local objects with strong guarantees even when the request process does not exhibit any statistical regularity.
No-Regret Caching via Online Mirror Descent
Feb 08, 2021
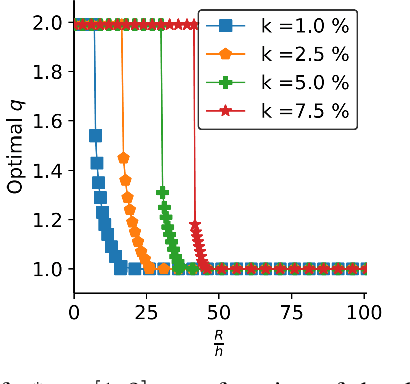
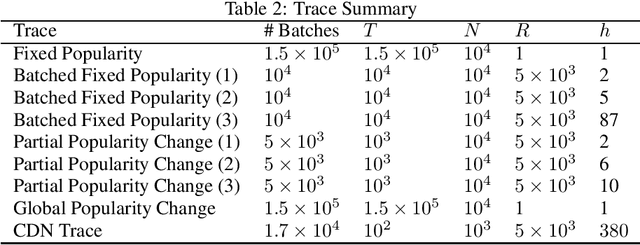
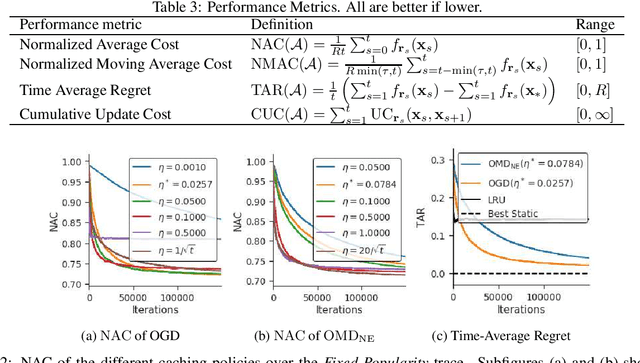
We study an online caching problem in which requests can be served by a local cache to avoid retrieval costs from a remote server. The cache can update its state after a batch of requests and store an arbitrarily small fraction of each content. We study no-regret algorithms based on Online Mirror Descent (OMD) strategies. We show that the optimal OMD strategy depends on the request diversity present in a batch. We also prove that, when the cache must store the entire content, rather than a fraction, OMD strategies can be coupled with a randomized rounding scheme that preserves regret guarantees.