 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Cooperative Inference Systems: The Case of Early Exit Networks
May 07, 2024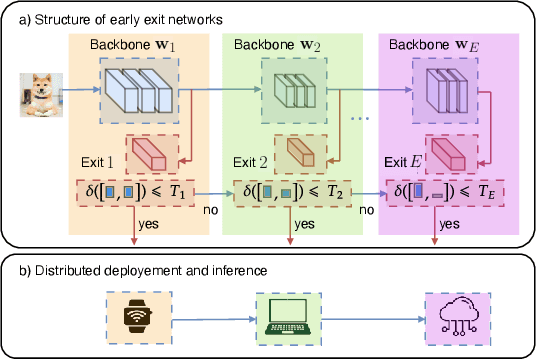
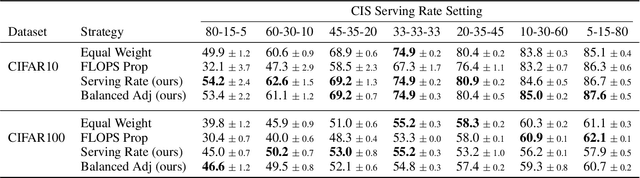
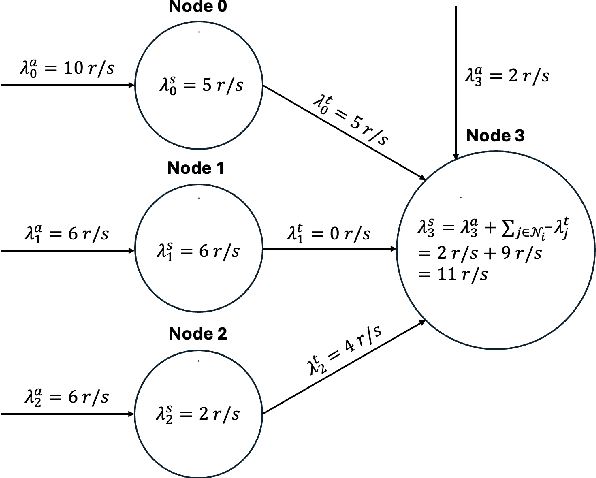
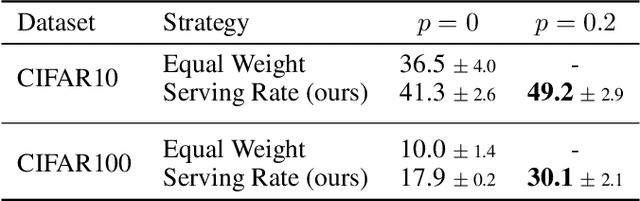
As Internet of Things (IoT) technology advances, end devices like sensors and smartphones are progressively equipped with AI models tailored to their local memory and computational constraints. Local inference reduces communication costs and latency; however, these smaller models typically underperform compared to more sophisticated models deployed on edge servers or in the cloud. Cooperative Inference Systems (CISs) address this performance trade-off by enabling smaller devices to offload part of their inference tasks to more capable devices. These systems often deploy hierarchical models that share numerous parameters, exemplified by Deep Neural Networks (DNNs) that utilize strategies like early exits or ordered dropout. In such instances, Federated Learning (FL) may be employed to jointly train the models within a CIS. Yet, traditional training methods have overlooked the operational dynamics of CISs during inference, particularly the potential high heterogeneity in serving rates across clients. To address this gap, we propose a novel FL approach designed explicitly for use in CISs that accounts for these variations in serving rates. Our framework not only offers rigorous theoretical guarantees, but also surpasses state-of-the-art (SOTA) training algorithms for CISs, especially in scenarios where inference request rates or data availability are uneven among clients.
An Empirical Analysis of Fairness Notions under Differential Privacy
Feb 06, 2023



Recent works have shown that selecting an optimal model architecture suited to the differential privacy setting is necessary to achieve the best possible utility for a given privacy budget using differentially private stochastic gradient descent (DP-SGD)(Tramer and Boneh 2020; Cheng et al. 2022). In light of these findings, we empirically analyse how different fairness notions, belonging to distinct classes of statistical fairness criteria (independence, separation and sufficiency), are impacted when one selects a model architecture suitable for DP-SGD, optimized for utility. Using standard datasets from ML fairness literature, we show using a rigorous experimental protocol, that by selecting the optimal model architecture for DP-SGD, the differences across groups concerning the relevant fairness metrics (demographic parity, equalized odds and predictive parity) more often decrease or are negligibly impacted, compared to the non-private baseline, for which optimal model architecture has also been selected to maximize utility. These findings challenge the understanding that differential privacy will necessarily exacerbate unfairness in deep learning models trained on biased datasets.