 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Generalization Techniques on the Interplay Among Privacy, Utility, and Fairness in Image Classification
Dec 16, 2024This study investigates the trade-offs between fairness, privacy, and utility in image classification using machine learning (ML). Recent research suggests that generalization techniques can improve the balance between privacy and utility. One focus of this work is sharpness-aware training (SAT) and its integration with differential privacy (DP-SAT) to further improve this balance. Additionally, we examine fairness in both private and non-private learning models trained on datasets with synthetic and real-world biases. We also measure the privacy risks involved in these scenarios by performing membership inference attacks (MIAs) and explore the consequences of eliminating high-privacy risk samples, termed outliers. Moreover, we introduce a new metric, named \emph{harmonic score}, which combines accuracy, privacy, and fairness into a single measure. Through empirical analysis using generalization techniques, we achieve an accuracy of 81.11\% under $(8, 10^{-5})$-DP on CIFAR-10, surpassing the 79.5\% reported by De et al. (2022). Moreover, our experiments show that memorization of training samples can begin before the overfitting point, and generalization techniques do not guarantee the prevention of this memorization. Our analysis of synthetic biases shows that generalization techniques can amplify model bias in both private and non-private models. Additionally, our results indicate that increased bias in training data leads to reduced accuracy, greater vulnerability to privacy attacks, and higher model bias. We validate these findings with the CelebA dataset, demonstrating that similar trends persist with real-world attribute imbalances. Finally, our experiments show that removing outlier data decreases accuracy and further amplifies model bias.
An Empirical Analysis of Fairness Notions under Differential Privacy
Feb 06, 2023



Recent works have shown that selecting an optimal model architecture suited to the differential privacy setting is necessary to achieve the best possible utility for a given privacy budget using differentially private stochastic gradient descent (DP-SGD)(Tramer and Boneh 2020; Cheng et al. 2022). In light of these findings, we empirically analyse how different fairness notions, belonging to distinct classes of statistical fairness criteria (independence, separation and sufficiency), are impacted when one selects a model architecture suitable for DP-SGD, optimized for utility. Using standard datasets from ML fairness literature, we show using a rigorous experimental protocol, that by selecting the optimal model architecture for DP-SGD, the differences across groups concerning the relevant fairness metrics (demographic parity, equalized odds and predictive parity) more often decrease or are negligibly impacted, compared to the non-private baseline, for which optimal model architecture has also been selected to maximize utility. These findings challenge the understanding that differential privacy will necessarily exacerbate unfairness in deep learning models trained on biased datasets.
Generalizing Adversarial Explanations with Grad-CAM
Apr 11, 2022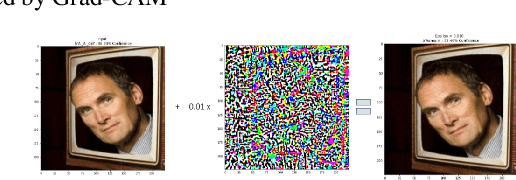
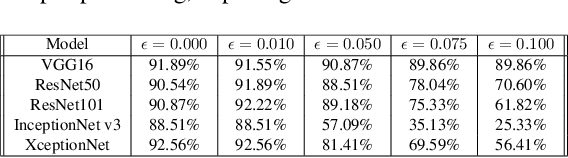

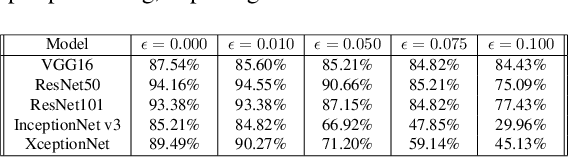
Gradient-weighted Class Activation Mapping (Grad- CAM), is an example-based explanation method that provides a gradient activation heat map as an explanation for Convolution Neural Network (CNN) models. The drawback of this method is that it cannot be used to generalize CNN behaviour. In this paper, we present a novel method that extends Grad-CAM from example-based explanations to a method for explaining global model behaviour. This is achieved by introducing two new metrics, (i) Mean Observed Dissimilarity (MOD) and (ii) Variation in Dissimilarity (VID), for model generalization. These metrics are computed by comparing a Normalized Inverted Structural Similarity Index (NISSIM) metric of the Grad-CAM generated heatmap for samples from the original test set and samples from the adversarial test set. For our experiment, we study adversarial attacks on deep models such as VGG16, ResNet50, and ResNet101, and wide models such as InceptionNetv3 and XceptionNet using Fast Gradient Sign Method (FGSM). We then compute the metrics MOD and VID for the automatic face recognition (AFR) use case with the VGGFace2 dataset. We observe a consistent shift in the region highlighted in the Grad-CAM heatmap, reflecting its participation to the decision making, across all models under adversarial attacks. The proposed method can be used to understand adversarial attacks and explain the behaviour of black box CNN models for image analysis.
Does Melania Trump have a body double from the perspective of automatic face recognition?
Sep 06, 2021
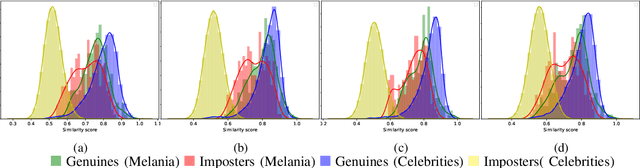
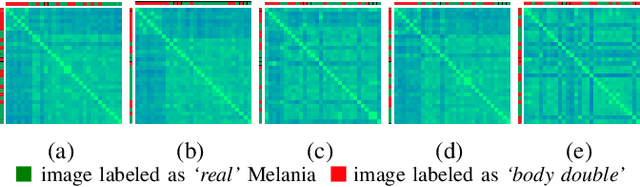
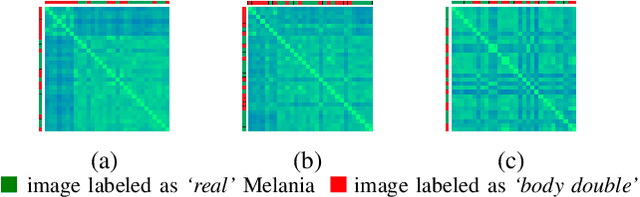
In this paper, we explore whether automatic face recognition can help in verifying widespread misinformation on social media, particularly conspiracy theories that are based on the existence of body doubles. The conspiracy theory addressed in this paper is the case of the Melania Trump body double. We employed four different state-of-the-art descriptors for face recognition to verify the integrity of the claim of the studied conspiracy theory. In addition, we assessed the impact of different image quality metrics on the variation of face recognition results. Two sets of image quality metrics were considered: acquisition-related metrics and subject-related metrics.
Multi-spectral Facial Landmark Detection
Jun 09, 2020



Thermal face image analysis is favorable for certain circumstances. For example, illumination-sensitive applications, like nighttime surveillance; and privacy-preserving demanded access control. However, the inadequate study on thermal face image analysis calls for attention in responding to the industry requirements. Detecting facial landmark points are important for many face analysis tasks, such as face recognition, 3D face reconstruction, and face expression recognition. In this paper, we propose a robust neural network enabled facial landmark detection, namely Deep Multi-Spectral Learning (DMSL). Briefly, DMSL consists of two sub-models, i.e. face boundary detection, and landmark coordinates detection. Such an architecture demonstrates the capability of detecting the facial landmarks on both visible and thermal images. Particularly, the proposed DMSL model is robust in facial landmark detection where the face is partially occluded, or facing different directions. The experiment conducted on Eurecom's visible and thermal paired database shows the superior performance of DMSL over the state-of-the-art for thermal facial landmark detection. In addition to that, we have annotated a thermal face dataset with their respective facial landmark for the purpose of experimentation.
Cascaded Generation of High-quality Color Visible Face Images from Thermal Captures
Oct 21, 2019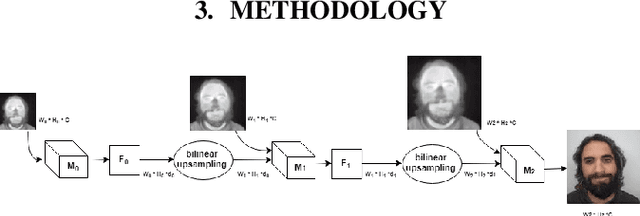



Generating visible-like face images from thermal images is essential to perform manual and automatic cross-spectrum face recognition. We successfully propose a solution based on cascaded refinement network that, unlike previous works, produces high quality generated color images without the need for face alignment, large databases, data augmentation, polarimetric sensors, computationally-intense training, or unrealistic restriction on the generated resolution. The training of our solution is based on the contextual loss, making it inherently scale (face area) and rotation invariant. We present generated image samples of unknown individuals under different poses and occlusion conditions.We also prove the high similarity in image quality between ground-truth images and generated ones by comparing seven quality metrics. We compare our results with two state-of-the-art approaches proving the superiority of our proposed approach.