 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Generalization Techniques on the Interplay Among Privacy, Utility, and Fairness in Image Classification
Dec 16, 2024
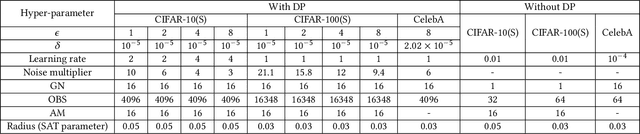


This study investigates the trade-offs between fairness, privacy, and utility in image classification using machine learning (ML). Recent research suggests that generalization techniques can improve the balance between privacy and utility. One focus of this work is sharpness-aware training (SAT) and its integration with differential privacy (DP-SAT) to further improve this balance. Additionally, we examine fairness in both private and non-private learning models trained on datasets with synthetic and real-world biases. We also measure the privacy risks involved in these scenarios by performing membership inference attacks (MIAs) and explore the consequences of eliminating high-privacy risk samples, termed outliers. Moreover, we introduce a new metric, named \emph{harmonic score}, which combines accuracy, privacy, and fairness into a single measure. Through empirical analysis using generalization techniques, we achieve an accuracy of 81.11\% under $(8, 10^{-5})$-DP on CIFAR-10, surpassing the 79.5\% reported by De et al. (2022). Moreover, our experiments show that memorization of training samples can begin before the overfitting point, and generalization techniques do not guarantee the prevention of this memorization. Our analysis of synthetic biases shows that generalization techniques can amplify model bias in both private and non-private models. Additionally, our results indicate that increased bias in training data leads to reduced accuracy, greater vulnerability to privacy attacks, and higher model bias. We validate these findings with the CelebA dataset, demonstrating that similar trends persist with real-world attribute imbalances. Finally, our experiments show that removing outlier data decreases accuracy and further amplifies model bias.
E2F-Net: Eyes-to-Face Inpainting via StyleGAN Latent Space
Mar 18, 2024Face inpainting, the technique of restoring missing or damaged regions in facial images, is pivotal for applications like face recognition in occluded scenarios and image analysis with poor-quality captures. This process not only needs to produce realistic visuals but also preserve individual identity characteristics. The aim of this paper is to inpaint a face given periocular region (eyes-to-face) through a proposed new Generative Adversarial Network (GAN)-based model called Eyes-to-Face Network (E2F-Net). The proposed approach extracts identity and non-identity features from the periocular region using two dedicated encoders have been used. The extracted features are then mapped to the latent space of a pre-trained StyleGAN generator to benefit from its state-of-the-art performance and its rich, diverse and expressive latent space without any additional training. We further improve the StyleGAN output to find the optimal code in the latent space using a new optimization for GAN inversion technique. Our E2F-Net requires a minimum training process reducing the computational complexity as a secondary benefit. Through extensive experiments, we show that our method successfully reconstructs the whole face with high quality, surpassing current techniques, despite significantly less training and supervision efforts. We have generated seven eyes-to-face datasets based on well-known public face datasets for training and verifying our proposed methods. The code and datasets are publicly available.
ChatGPT and biometrics: an assessment of face recognition, gender detection, and age estimation capabilities
Mar 05, 2024

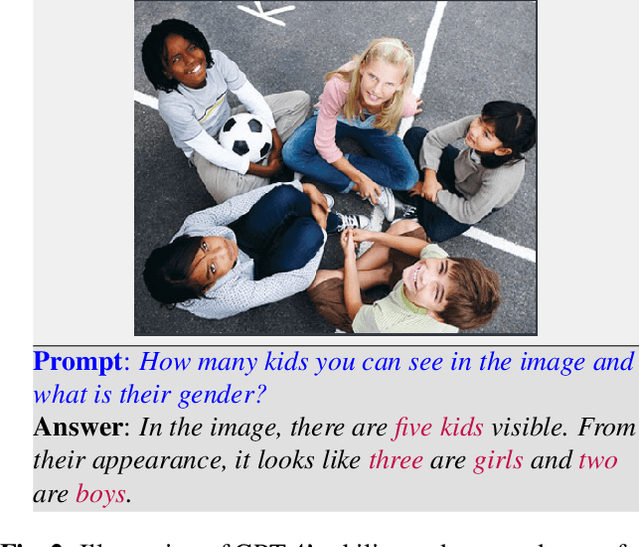

This paper explores the application of large language models (LLMs), like ChatGPT, for biometric tasks. We specifically examine the capabilities of ChatGPT in performing biometric-related tasks, with an emphasis on face recognition, gender detection, and age estimation. Since biometrics are considered as sensitive information, ChatGPT avoids answering direct prompts, and thus we crafted a prompting strategy to bypass its safeguard and evaluate the capabilities for biometrics tasks. Our study reveals that ChatGPT recognizes facial identities and differentiates between two facial images with considerable accuracy. Additionally, experimental results demonstrate remarkable performance in gender detection and reasonable accuracy for the age estimation tasks. Our findings shed light on the promising potentials in the application of LLMs and foundation models for biometrics.
Lightweight Face Recognition: An Improved MobileFaceNet Model
Nov 26, 2023



This paper presents an extensive exploration and comparative analysis of lightweight face recognition (FR) models, specifically focusing on MobileFaceNet and its modified variant, MMobileFaceNet. The need for efficient FR models on devices with limited computational resources has led to the development of models with reduced memory footprints and computational demands without sacrificing accuracy. Our research delves into the impact of dataset selection, model architecture, and optimization algorithms on the performance of FR models. We highlight our participation in the EFaR-2023 competition, where our models showcased exceptional performance, particularly in categories restricted by the number of parameters. By employing a subset of the Webface42M dataset and integrating sharpness-aware minimization (SAM) optimization, we achieved significant improvements in accuracy across various benchmarks, including those that test for cross-pose, cross-age, and cross-ethnicity performance. The results underscore the efficacy of our approach in crafting models that are not only computationally efficient but also maintain high accuracy in diverse conditions.
EFaR 2023: Efficient Face Recognition Competition
Aug 08, 2023



This paper presents the summary of the Efficient Face Recognition Competition (EFaR) held at the 2023 International Joint Conference on Biometrics (IJCB 2023). The competition received 17 submissions from 6 different teams. To drive further development of efficient face recognition models, the submitted solutions are ranked based on a weighted score of the achieved verification accuracies on a diverse set of benchmarks, as well as the deployability given by the number of floating-point operations and model size. The evaluation of submissions is extended to bias, cross-quality, and large-scale recognition benchmarks. Overall, the paper gives an overview of the achieved performance values of the submitted solutions as well as a diverse set of baselines. The submitted solutions use small, efficient network architectures to reduce the computational cost, some solutions apply model quantization. An outlook on possible techniques that are underrepresented in current solutions is given as well.