 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo ImageNet-trained models learn shortcuts? The impact of frequency shortcuts on generalization
Mar 05, 2025



Frequency shortcuts refer to specific frequency patterns that models heavily rely on for correct classification. Previous studies have shown that models trained on small image datasets often exploit such shortcuts, potentially impairing their generalization performance. However, existing methods for identifying frequency shortcuts require expensive computations and become impractical for analyzing models trained on large datasets. In this work, we propose the first approach to more efficiently analyze frequency shortcuts at a larger scale. We show that both CNN and transformer models learn frequency shortcuts on ImageNet. We also expose that frequency shortcut solutions can yield good performance on out-of-distribution (OOD) test sets which largely retain texture information. However, these shortcuts, mostly aligned with texture patterns, hinder model generalization on rendition-based OOD test sets. These observations suggest that current OOD evaluations often overlook the impact of frequency shortcuts on model generalization. Future benchmarks could thus benefit from explicitly assessing and accounting for these shortcuts to build models that generalize across a broader range of OOD scenarios.
Unveiling the Power of Sparse Neural Networks for Feature Selection
Aug 08, 2024



Sparse Neural Networks (SNNs) have emerged as powerful tools for efficient feature selection. Leveraging the dynamic sparse training (DST) algorithms within SNNs has demonstrated promising feature selection capabilities while drastically reducing computational overheads. Despite these advancements, several critical aspects remain insufficiently explored for feature selection. Questions persist regarding the choice of the DST algorithm for network training, the choice of metric for ranking features/neurons, and the comparative performance of these methods across diverse datasets when compared to dense networks. This paper addresses these gaps by presenting a comprehensive systematic analysis of feature selection with sparse neural networks. Moreover, we introduce a novel metric considering sparse neural network characteristics, which is designed to quantify feature importance within the context of SNNs. Our findings show that feature selection with SNNs trained with DST algorithms can achieve, on average, more than $50\%$ memory and $55\%$ FLOPs reduction compared to the dense networks, while outperforming them in terms of the quality of the selected features. Our code and the supplementary material are available on GitHub (\url{https://github.com/zahraatashgahi/Neuron-Attribution}).
E2F-Net: Eyes-to-Face Inpainting via StyleGAN Latent Space
Mar 18, 2024Face inpainting, the technique of restoring missing or damaged regions in facial images, is pivotal for applications like face recognition in occluded scenarios and image analysis with poor-quality captures. This process not only needs to produce realistic visuals but also preserve individual identity characteristics. The aim of this paper is to inpaint a face given periocular region (eyes-to-face) through a proposed new Generative Adversarial Network (GAN)-based model called Eyes-to-Face Network (E2F-Net). The proposed approach extracts identity and non-identity features from the periocular region using two dedicated encoders have been used. The extracted features are then mapped to the latent space of a pre-trained StyleGAN generator to benefit from its state-of-the-art performance and its rich, diverse and expressive latent space without any additional training. We further improve the StyleGAN output to find the optimal code in the latent space using a new optimization for GAN inversion technique. Our E2F-Net requires a minimum training process reducing the computational complexity as a secondary benefit. Through extensive experiments, we show that our method successfully reconstructs the whole face with high quality, surpassing current techniques, despite significantly less training and supervision efforts. We have generated seven eyes-to-face datasets based on well-known public face datasets for training and verifying our proposed methods. The code and datasets are publicly available.
NeutrEx: A 3D Quality Component Measure on Facial Expression Neutrality
Aug 19, 2023Accurate face recognition systems are increasingly important in sensitive applications like border control or migration management. Therefore, it becomes crucial to quantify the quality of facial images to ensure that low-quality images are not affecting recognition accuracy. In this context, the current draft of ISO/IEC 29794-5 introduces the concept of component quality to estimate how single factors of variation affect recognition outcomes. In this study, we propose a quality measure (NeutrEx) based on the accumulated distances of a 3D face reconstruction to a neutral expression anchor. Our evaluations demonstrate the superiority of our proposed method compared to baseline approaches obtained by training Support Vector Machines on face embeddings extracted from a pre-trained Convolutional Neural Network for facial expression classification. Furthermore, we highlight the explainable nature of our NeutrEx measures by computing per-vertex distances to unveil the most impactful face regions and allow operators to give actionable feedback to subjects.
DFM-X: Augmentation by Leveraging Prior Knowledge of Shortcut Learning
Aug 12, 2023



Neural networks are prone to learn easy solutions from superficial statistics in the data, namely shortcut learning, which impairs generalization and robustness of models. We propose a data augmentation strategy, named DFM-X, that leverages knowledge about frequency shortcuts, encoded in Dominant Frequencies Maps computed for image classification models. We randomly select X% training images of certain classes for augmentation, and process them by retaining the frequencies included in the DFMs of other classes. This strategy compels the models to leverage a broader range of frequencies for classification, rather than relying on specific frequency sets. Thus, the models learn more deep and task-related semantics compared to their counterpart trained with standard setups. Unlike other commonly used augmentation techniques which focus on increasing the visual variations of training data, our method targets exploiting the original data efficiently, by distilling prior knowledge about destructive learning behavior of models from data. Our experimental results demonstrate that DFM-X improves robustness against common corruptions and adversarial attacks. It can be seamlessly integrated with other augmentation techniques to further enhance the robustness of models.
Defocus Blur Synthesis and Deblurring via Interpolation and Extrapolation in Latent Space
Jul 28, 2023



Though modern microscopes have an autofocusing system to ensure optimal focus, out-of-focus images can still occur when cells within the medium are not all in the same focal plane, affecting the image quality for medical diagnosis and analysis of diseases. We propose a method that can deblur images as well as synthesize defocus blur. We train autoencoders with implicit and explicit regularization techniques to enforce linearity relations among the representations of different blur levels in the latent space. This allows for the exploration of different blur levels of an object by linearly interpolating/extrapolating the latent representations of images taken at different focal planes. Compared to existing works, we use a simple architecture to synthesize images with flexible blur levels, leveraging the linear latent space. Our regularized autoencoders can effectively mimic blur and deblur, increasing data variety as a data augmentation technique and improving the quality of microscopic images, which would be beneficial for further processing and analysis.
What do neural networks learn in image classification? A frequency shortcut perspective
Jul 19, 2023
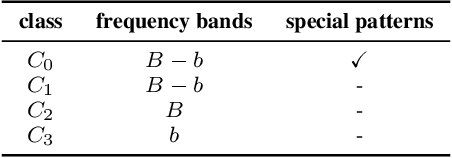
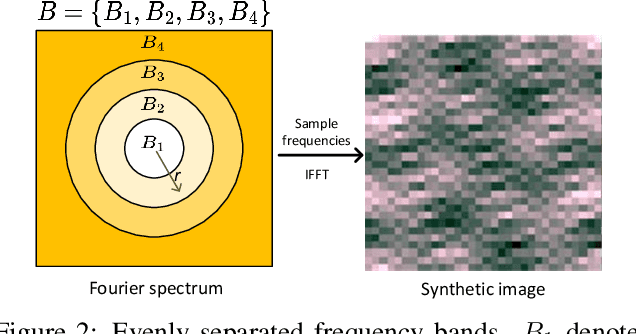
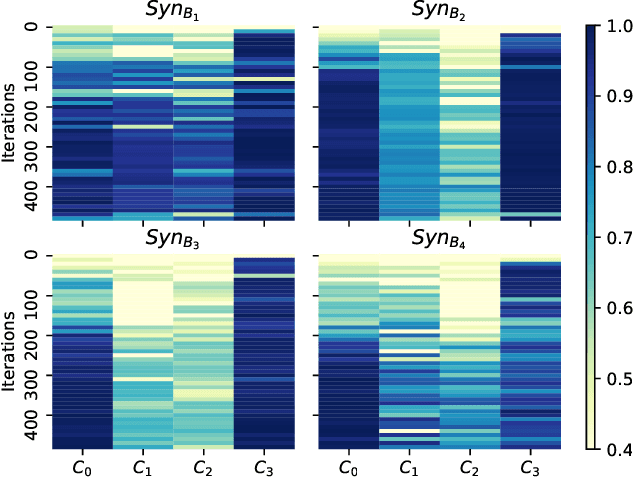
Frequency analysis is useful for understanding the mechanisms of representation learning in neural networks (NNs). Most research in this area focuses on the learning dynamics of NNs for regression tasks, while little for classification. This study empirically investigates the latter and expands the understanding of frequency shortcuts. First, we perform experiments on synthetic datasets, designed to have a bias in different frequency bands. Our results demonstrate that NNs tend to find simple solutions for classification, and what they learn first during training depends on the most distinctive frequency characteristics, which can be either low- or high-frequencies. Second, we confirm this phenomenon on natural images. We propose a metric to measure class-wise frequency characteristics and a method to identify frequency shortcuts. The results show that frequency shortcuts can be texture-based or shape-based, depending on what best simplifies the objective. Third, we validate the transferability of frequency shortcuts on out-of-distribution (OOD) test sets. Our results suggest that frequency shortcuts can be transferred across datasets and cannot be fully avoided by larger model capacity and data augmentation. We recommend that future research should focus on effective training schemes mitigating frequency shortcut learning.
Adaptive Sparsity Level during Training for Efficient Time Series Forecasting with Transformers
May 28, 2023Efficient time series forecasting has become critical for real-world applications, particularly with deep neural networks (DNNs). Efficiency in DNNs can be achieved through sparse connectivity and reducing the model size. However, finding the sparsity level automatically during training remains a challenging task due to the heterogeneity in the loss-sparsity tradeoffs across the datasets. In this paper, we propose \enquote{\textbf{P}runing with \textbf{A}daptive \textbf{S}parsity \textbf{L}evel} (\textbf{PALS}), to automatically seek an optimal balance between loss and sparsity, all without the need for a predefined sparsity level. PALS draws inspiration from both sparse training and during-training methods. It introduces the novel "expand" mechanism in training sparse neural networks, allowing the model to dynamically shrink, expand, or remain stable to find a proper sparsity level. In this paper, we focus on achieving efficiency in transformers known for their excellent time series forecasting performance but high computational cost. Nevertheless, PALS can be applied directly to any DNN. In the scope of these arguments, we demonstrate its effectiveness also on the DLinear model. Experimental results on six benchmark datasets and five state-of-the-art transformer variants show that PALS substantially reduces model size while maintaining comparable performance to the dense model. More interestingly, PALS even outperforms the dense model, in 12 and 14 cases out of 30 cases in terms of MSE and MAE loss, respectively, while reducing 65% parameter count and 63% FLOPs on average. Our code will be publicly available upon acceptance of the paper.
The Robustness of Computer Vision Models against Common Corruptions: a Survey
May 10, 2023



The performance of computer vision models is susceptible to unexpected changes in input images when deployed in real scenarios. These changes are referred to as common corruptions. While they can hinder the applicability of computer vision models in real-world scenarios, they are not always considered as a testbed for model generalization and robustness. In this survey, we present a comprehensive and systematic overview of methods that improve corruption robustness of computer vision models. Unlike existing surveys that focus on adversarial attacks and label noise, we cover extensively the study of robustness to common corruptions that can occur when deploying computer vision models to work in practical applications. We describe different types of image corruption and provide the definition of corruption robustness. We then introduce relevant evaluation metrics and benchmark datasets. We categorize methods into four groups. We also cover indirect methods that show improvements in generalization and may improve corruption robustness as a byproduct. We report benchmark results collected from the literature and find that they are not evaluated in a unified manner, making it difficult to compare and analyze. We thus built a unified benchmark framework to obtain directly comparable results on benchmark datasets. Furthermore, we evaluate relevant backbone networks pre-trained on ImageNet using our framework, providing an overview of the base corruption robustness of existing models to help choose appropriate backbones for computer vision tasks. We identify that developing methods to handle a wide range of corruptions and efficiently learn with limited data and computational resources is crucial for future development. Additionally, we highlight the need for further investigation into the relationship among corruption robustness, OOD generalization, and shortcut learning.
Supervised Feature Selection with Neuron Evolution in Sparse Neural Networks
Mar 14, 2023



Feature selection that selects an informative subset of variables from data not only enhances the model interpretability and performance but also alleviates the resource demands. Recently, there has been growing attention on feature selection using neural networks. However, existing methods usually suffer from high computational costs when applied to high-dimensional datasets. In this paper, inspired by evolution processes, we propose a novel resource-efficient supervised feature selection method using sparse neural networks, named \enquote{NeuroFS}. By gradually pruning the uninformative features from the input layer of a sparse neural network trained from scratch, NeuroFS derives an informative subset of features efficiently. By performing several experiments on $11$ low and high-dimensional real-world benchmarks of different types, we demonstrate that NeuroFS achieves the highest ranking-based score among the considered state-of-the-art supervised feature selection models. The code is available on GitHub.