 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Harmonize Cross-vendor X-ray Images by Non-linear Image Dynamics Correction
Apr 14, 2025In this paper, we explore how conventional image enhancement can improve model robustness in medical image analysis. By applying commonly used normalization methods to images from various vendors and studying their influence on model generalization in transfer learning, we show that the nonlinear characteristics of domain-specific image dynamics cannot be addressed by simple linear transforms. To tackle this issue, we reformulate the image harmonization task as an exposure correction problem and propose a method termed Global Deep Curve Estimation (GDCE) to reduce domain-specific exposure mismatch. GDCE performs enhancement via a pre-defined polynomial function and is trained with the help of a ``domain discriminator'', aiming to improve model transparency in downstream tasks compared to existing black-box methods.
Do ImageNet-trained models learn shortcuts? The impact of frequency shortcuts on generalization
Mar 05, 2025



Frequency shortcuts refer to specific frequency patterns that models heavily rely on for correct classification. Previous studies have shown that models trained on small image datasets often exploit such shortcuts, potentially impairing their generalization performance. However, existing methods for identifying frequency shortcuts require expensive computations and become impractical for analyzing models trained on large datasets. In this work, we propose the first approach to more efficiently analyze frequency shortcuts at a larger scale. We show that both CNN and transformer models learn frequency shortcuts on ImageNet. We also expose that frequency shortcut solutions can yield good performance on out-of-distribution (OOD) test sets which largely retain texture information. However, these shortcuts, mostly aligned with texture patterns, hinder model generalization on rendition-based OOD test sets. These observations suggest that current OOD evaluations often overlook the impact of frequency shortcuts on model generalization. Future benchmarks could thus benefit from explicitly assessing and accounting for these shortcuts to build models that generalize across a broader range of OOD scenarios.
Dynamic Sparse Training versus Dense Training: The Unexpected Winner in Image Corruption Robustness
Oct 03, 2024
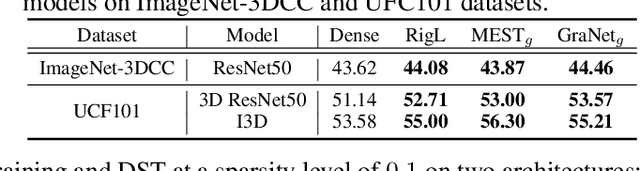
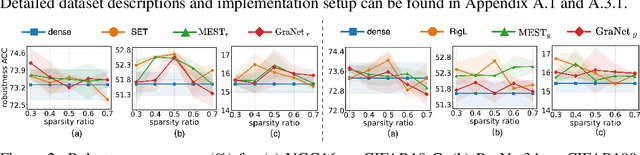

It is generally perceived that Dynamic Sparse Training opens the door to a new era of scalability and efficiency for artificial neural networks at, perhaps, some costs in accuracy performance for the classification task. At the same time, Dense Training is widely accepted as being the "de facto" approach to train artificial neural networks if one would like to maximize their robustness against image corruption. In this paper, we question this general practice. Consequently, we claim that, contrary to what is commonly thought, the Dynamic Sparse Training methods can consistently outperform Dense Training in terms of robustness accuracy, particularly if the efficiency aspect is not considered as a main objective (i.e., sparsity levels between 10% and up to 50%), without adding (or even reducing) resource cost. We validate our claim on two types of data, images and videos, using several traditional and modern deep learning architectures for computer vision and three widely studied Dynamic Sparse Training algorithms. Our findings reveal a new yet-unknown benefit of Dynamic Sparse Training and open new possibilities in improving deep learning robustness beyond the current state of the art.
Fourier-basis Functions to Bridge Augmentation Gap: Rethinking Frequency Augmentation in Image Classification
Mar 05, 2024Computer vision models normally witness degraded performance when deployed in real-world scenarios, due to unexpected changes in inputs that were not accounted for during training. Data augmentation is commonly used to address this issue, as it aims to increase data variety and reduce the distribution gap between training and test data. However, common visual augmentations might not guarantee extensive robustness of computer vision models. In this paper, we propose Auxiliary Fourier-basis Augmentation (AFA), a complementary technique targeting augmentation in the frequency domain and filling the augmentation gap left by visual augmentations. We demonstrate the utility of augmentation via Fourier-basis additive noise in a straightforward and efficient adversarial setting. Our results show that AFA benefits the robustness of models against common corruptions, OOD generalization, and consistency of performance of models against increasing perturbations, with negligible deficit to the standard performance of models. It can be seamlessly integrated with other augmentation techniques to further boost performance. Code and models can be found at: https://github.com/nis-research/afa-augment
DFM-X: Augmentation by Leveraging Prior Knowledge of Shortcut Learning
Aug 12, 2023



Neural networks are prone to learn easy solutions from superficial statistics in the data, namely shortcut learning, which impairs generalization and robustness of models. We propose a data augmentation strategy, named DFM-X, that leverages knowledge about frequency shortcuts, encoded in Dominant Frequencies Maps computed for image classification models. We randomly select X% training images of certain classes for augmentation, and process them by retaining the frequencies included in the DFMs of other classes. This strategy compels the models to leverage a broader range of frequencies for classification, rather than relying on specific frequency sets. Thus, the models learn more deep and task-related semantics compared to their counterpart trained with standard setups. Unlike other commonly used augmentation techniques which focus on increasing the visual variations of training data, our method targets exploiting the original data efficiently, by distilling prior knowledge about destructive learning behavior of models from data. Our experimental results demonstrate that DFM-X improves robustness against common corruptions and adversarial attacks. It can be seamlessly integrated with other augmentation techniques to further enhance the robustness of models.
Defocus Blur Synthesis and Deblurring via Interpolation and Extrapolation in Latent Space
Jul 28, 2023



Though modern microscopes have an autofocusing system to ensure optimal focus, out-of-focus images can still occur when cells within the medium are not all in the same focal plane, affecting the image quality for medical diagnosis and analysis of diseases. We propose a method that can deblur images as well as synthesize defocus blur. We train autoencoders with implicit and explicit regularization techniques to enforce linearity relations among the representations of different blur levels in the latent space. This allows for the exploration of different blur levels of an object by linearly interpolating/extrapolating the latent representations of images taken at different focal planes. Compared to existing works, we use a simple architecture to synthesize images with flexible blur levels, leveraging the linear latent space. Our regularized autoencoders can effectively mimic blur and deblur, increasing data variety as a data augmentation technique and improving the quality of microscopic images, which would be beneficial for further processing and analysis.
What do neural networks learn in image classification? A frequency shortcut perspective
Jul 19, 2023
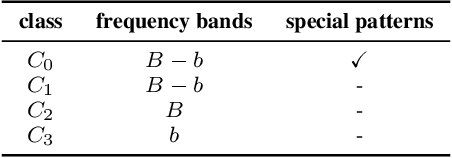
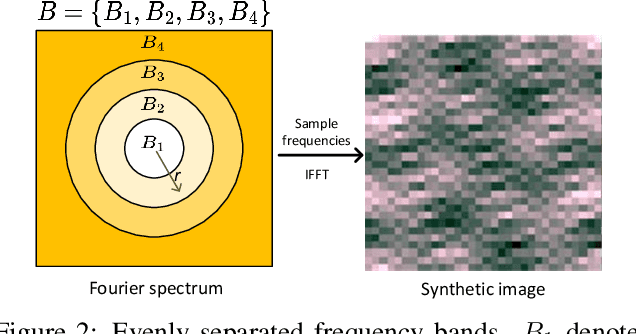
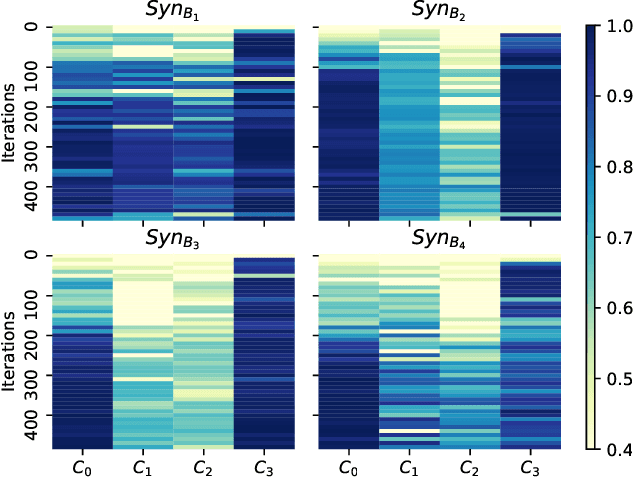
Frequency analysis is useful for understanding the mechanisms of representation learning in neural networks (NNs). Most research in this area focuses on the learning dynamics of NNs for regression tasks, while little for classification. This study empirically investigates the latter and expands the understanding of frequency shortcuts. First, we perform experiments on synthetic datasets, designed to have a bias in different frequency bands. Our results demonstrate that NNs tend to find simple solutions for classification, and what they learn first during training depends on the most distinctive frequency characteristics, which can be either low- or high-frequencies. Second, we confirm this phenomenon on natural images. We propose a metric to measure class-wise frequency characteristics and a method to identify frequency shortcuts. The results show that frequency shortcuts can be texture-based or shape-based, depending on what best simplifies the objective. Third, we validate the transferability of frequency shortcuts on out-of-distribution (OOD) test sets. Our results suggest that frequency shortcuts can be transferred across datasets and cannot be fully avoided by larger model capacity and data augmentation. We recommend that future research should focus on effective training schemes mitigating frequency shortcut learning.
The Robustness of Computer Vision Models against Common Corruptions: a Survey
May 10, 2023



The performance of computer vision models is susceptible to unexpected changes in input images when deployed in real scenarios. These changes are referred to as common corruptions. While they can hinder the applicability of computer vision models in real-world scenarios, they are not always considered as a testbed for model generalization and robustness. In this survey, we present a comprehensive and systematic overview of methods that improve corruption robustness of computer vision models. Unlike existing surveys that focus on adversarial attacks and label noise, we cover extensively the study of robustness to common corruptions that can occur when deploying computer vision models to work in practical applications. We describe different types of image corruption and provide the definition of corruption robustness. We then introduce relevant evaluation metrics and benchmark datasets. We categorize methods into four groups. We also cover indirect methods that show improvements in generalization and may improve corruption robustness as a byproduct. We report benchmark results collected from the literature and find that they are not evaluated in a unified manner, making it difficult to compare and analyze. We thus built a unified benchmark framework to obtain directly comparable results on benchmark datasets. Furthermore, we evaluate relevant backbone networks pre-trained on ImageNet using our framework, providing an overview of the base corruption robustness of existing models to help choose appropriate backbones for computer vision tasks. We identify that developing methods to handle a wide range of corruptions and efficiently learn with limited data and computational resources is crucial for future development. Additionally, we highlight the need for further investigation into the relationship among corruption robustness, OOD generalization, and shortcut learning.