 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Data Is Scarce: Scaling Sparse Language Models with Repeated Training
May 31, 2026Scaling laws for dense LLMs under infinite data are well explored, but how sparsity interacts with limited data is not. In this work, we study sparse training in data-constrained regimes where limited unique tokens require multi-epoch training. Our experiments span models up to 1.92B parameters in the fitting set, sparsity up to 93.75%, unique data budgets up to 2.6B tokens, and total training tokens up to 41.6B over 16 epochs; we further validate extrapolation on held-out dense-equivalent models up to 7.68B parameters. We find that: 1. Sparse scaling in data-limited settings: We introduce a scaling law that models loss as a function of active parameters, unique tokens, data repetition, and sparsity, accurately predicting performance across compute and data budgets. 2. Delayed data saturation: sparse training postpones diminishing returns from repeated data, making multi-epoch training more effective. 3. Resource trade-offs: With fixed data, loss-optimal sparsity is moderate ~ 50%, while compute-optimal sparsity is higher and grows with data scale. Overall, sparsity is not just a tool for efficiency, but a mechanism for improving scaling trade-offs under data scarcity. Our code is available at: https://github.com/boqian333/sparse-dc-scaling.
Memory-Efficient LLM Training with Dynamic Sparsity: From Stability to Practical Scaling
May 30, 2026Dynamic Sparse Training (DST) offers a promising paradigm for improving the training and inference efficiency of deep neural networks; however, we find that in large language model training, DST can suffer from optimization instability, manifested as loss spikes after topology updates. In this work, we show that the naive use of standard Adam-based optimizers leads to a cold-start issue for newly regrown parameters, resulting in excessively large updates and disrupted training dynamics. To address this issue, we propose Sparse Memory-Efficient Training (SMET), which stabilizes DST with optimizer warm-up and improves training progress through density-aware learning-rate scaling. SMET further reduces memory consumption by storing gradients and optimizer states only for active parameters. We provide a theoretical analysis of the update behaviors under SMET, showing improved optimization stability. Extensive experiments demonstrate that SMET enables stable, scalable, and memory-efficient sparse pre-training of LLMs, paving the way for sparse training as a practical alternative to dense training. Our code is publicly available at: https://github.com/QiaoXiao7282/SMET.
NeuroTrails: Training with Dynamic Sparse Heads as the Key to Effective Ensembling
May 23, 2025Model ensembles have long been a cornerstone for improving generalization and robustness in deep learning. However, their effectiveness often comes at the cost of substantial computational overhead. To address this issue, state-of-the-art methods aim to replicate ensemble-class performance without requiring multiple independently trained networks. Unfortunately, these algorithms often still demand considerable compute at inference. In response to these limitations, we introduce $\textbf{NeuroTrails}$, a sparse multi-head architecture with dynamically evolving topology. This unexplored model-agnostic training paradigm improves ensemble performance while reducing the required resources. We analyze the underlying reason for its effectiveness and observe that the various neural trails induced by dynamic sparsity attain a $\textit{Goldilocks zone}$ of prediction diversity. NeuroTrails displays efficacy with convolutional and transformer-based architectures on computer vision and language tasks. Experiments on ResNet-50/ImageNet, LLaMA-350M/C4, among many others, demonstrate increased accuracy and stronger robustness in zero-shot generalization, while requiring significantly fewer parameters.
Dynamic Sparse Training versus Dense Training: The Unexpected Winner in Image Corruption Robustness
Oct 03, 2024
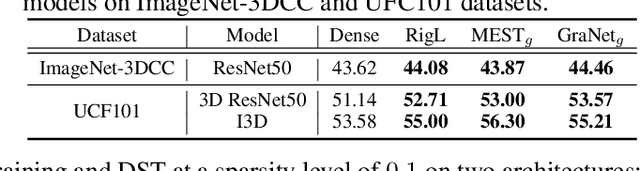
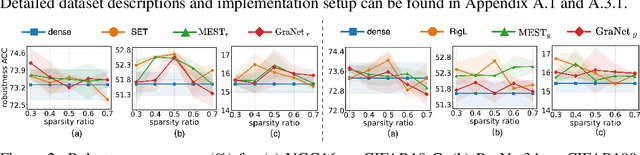

It is generally perceived that Dynamic Sparse Training opens the door to a new era of scalability and efficiency for artificial neural networks at, perhaps, some costs in accuracy performance for the classification task. At the same time, Dense Training is widely accepted as being the "de facto" approach to train artificial neural networks if one would like to maximize their robustness against image corruption. In this paper, we question this general practice. Consequently, we claim that, contrary to what is commonly thought, the Dynamic Sparse Training methods can consistently outperform Dense Training in terms of robustness accuracy, particularly if the efficiency aspect is not considered as a main objective (i.e., sparsity levels between 10% and up to 50%), without adding (or even reducing) resource cost. We validate our claim on two types of data, images and videos, using several traditional and modern deep learning architectures for computer vision and three widely studied Dynamic Sparse Training algorithms. Our findings reveal a new yet-unknown benefit of Dynamic Sparse Training and open new possibilities in improving deep learning robustness beyond the current state of the art.
E2ENet: Dynamic Sparse Feature Fusion for Accurate and Efficient 3D Medical Image Segmentation
Dec 07, 2023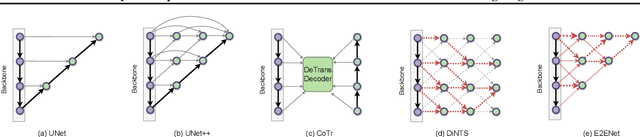
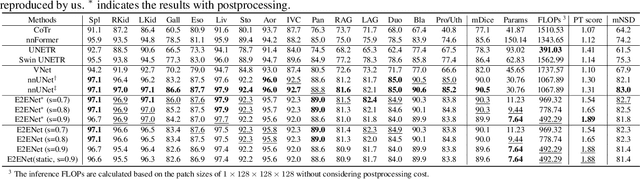
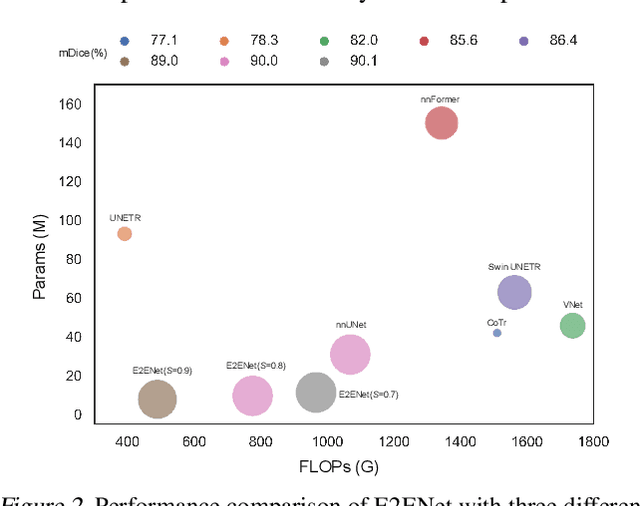
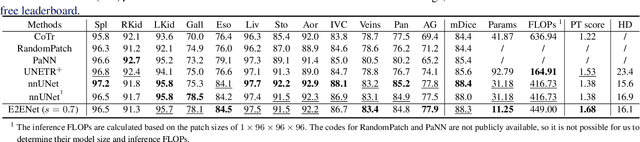
Deep neural networks have evolved as the leading approach in 3D medical image segmentation due to their outstanding performance. However, the ever-increasing model size and computation cost of deep neural networks have become the primary barrier to deploying them on real-world resource-limited hardware. In pursuit of improving performance and efficiency, we propose a 3D medical image segmentation model, named Efficient to Efficient Network (E2ENet), incorporating two parametrically and computationally efficient designs. i. Dynamic sparse feature fusion (DSFF) mechanism: it adaptively learns to fuse informative multi-scale features while reducing redundancy. ii. Restricted depth-shift in 3D convolution: it leverages the 3D spatial information while keeping the model and computational complexity as 2D-based methods. We conduct extensive experiments on BTCV, AMOS-CT and Brain Tumor Segmentation Challenge, demonstrating that E2ENet consistently achieves a superior trade-off between accuracy and efficiency than prior arts across various resource constraints. E2ENet achieves comparable accuracy on the large-scale challenge AMOS-CT, while saving over 68\% parameter count and 29\% FLOPs in the inference phase, compared with the previous best-performing method. Our code has been made available at: https://github.com/boqian333/E2ENet-Medical.
Automatic Noise Filtering with Dynamic Sparse Training in Deep Reinforcement Learning
Feb 13, 2023Tomorrow's robots will need to distinguish useful information from noise when performing different tasks. A household robot for instance may continuously receive a plethora of information about the home, but needs to focus on just a small subset to successfully execute its current chore. Filtering distracting inputs that contain irrelevant data has received little attention in the reinforcement learning literature. To start resolving this, we formulate a problem setting in reinforcement learning called the $\textit{extremely noisy environment}$ (ENE), where up to $99\%$ of the input features are pure noise. Agents need to detect which features provide task-relevant information about the state of the environment. Consequently, we propose a new method termed $\textit{Automatic Noise Filtering}$ (ANF), which uses the principles of dynamic sparse training in synergy with various deep reinforcement learning algorithms. The sparse input layer learns to focus its connectivity on task-relevant features, such that ANF-SAC and ANF-TD3 outperform standard SAC and TD3 by a large margin, while using up to $95\%$ fewer weights. Furthermore, we devise a transfer learning setting for ENEs, by permuting all features of the environment after 1M timesteps to simulate the fact that other information sources can become relevant as the world evolves. Again, ANF surpasses the baselines in final performance and sample complexity. Our code is available at https://github.com/bramgrooten/automatic-noise-filtering
Dynamic Sparse Network for Time Series Classification: Learning What to "see''
Dec 19, 2022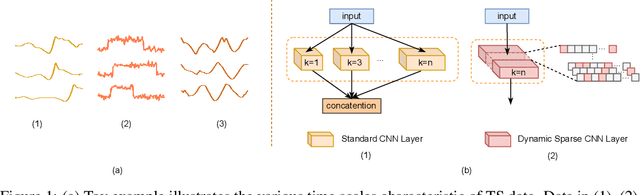

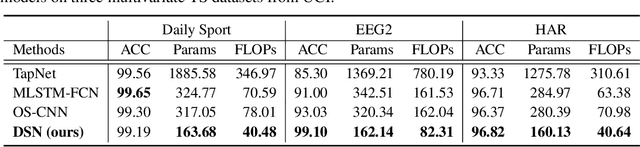
The receptive field (RF), which determines the region of time series to be ``seen'' and used, is critical to improve the performance for time series classification (TSC). However, the variation of signal scales across and within time series data, makes it challenging to decide on proper RF sizes for TSC. In this paper, we propose a dynamic sparse network (DSN) with sparse connections for TSC, which can learn to cover various RF without cumbersome hyper-parameters tuning. The kernels in each sparse layer are sparse and can be explored under the constraint regions by dynamic sparse training, which makes it possible to reduce the resource cost. The experimental results show that the proposed DSN model can achieve state-of-art performance on both univariate and multivariate TSC datasets with less than 50\% computational cost compared with recent baseline methods, opening the path towards more accurate resource-aware methods for time series analyses. Our code is publicly available at: https://github.com/QiaoXiao7282/DSN.
FreeTickets: Accurate, Robust and Efficient Deep Ensemble by Training with Dynamic Sparsity
Jun 28, 2021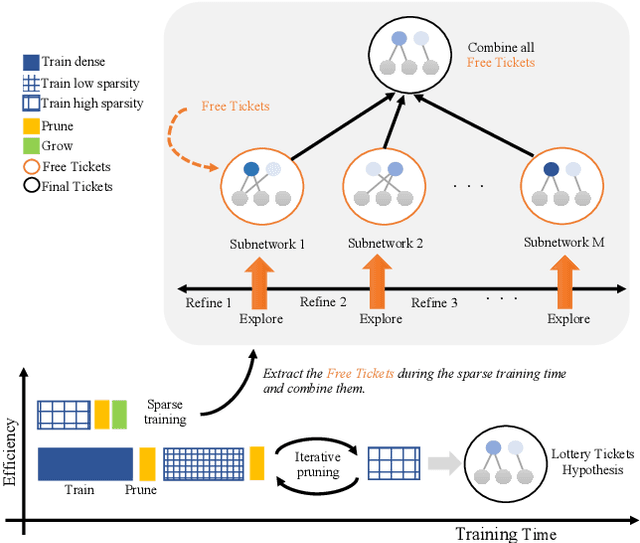
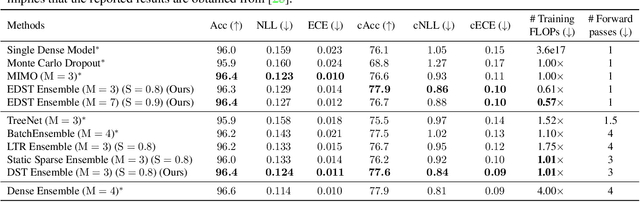
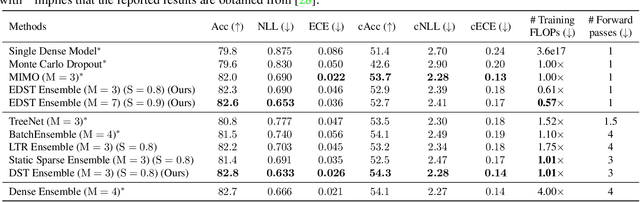
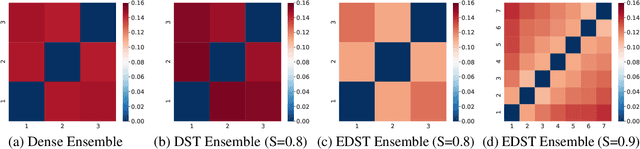
Recent works on sparse neural networks have demonstrated that it is possible to train a sparse network in isolation to match the performance of the corresponding dense networks with a fraction of parameters. However, the identification of these performant sparse neural networks (winning tickets) either involves a costly iterative train-prune-retrain process (e.g., Lottery Ticket Hypothesis) or an over-extended sparse training time (e.g., Training with Dynamic Sparsity), both of which would raise financial and environmental concerns. In this work, we attempt to address this cost-reducing problem by introducing the FreeTickets concept, as the first solution which can boost the performance of sparse convolutional neural networks over their dense network equivalents by a large margin, while using for complete training only a fraction of the computational resources required by the latter. Concretely, we instantiate the FreeTickets concept, by proposing two novel efficient ensemble methods with dynamic sparsity, which yield in one shot many diverse and accurate tickets "for free" during the sparse training process. The combination of these free tickets into an ensemble demonstrates a significant improvement in accuracy, uncertainty estimation, robustness, and efficiency over the corresponding dense (ensemble) networks. Our results provide new insights into the strength of sparse neural networks and suggest that the benefits of sparsity go way beyond the usual training/inference expected efficiency. We will release all codes in https://github.com/Shiweiliuiiiiiii/FreeTickets.
Dynamic Sparse Training for Deep Reinforcement Learning
Jun 08, 2021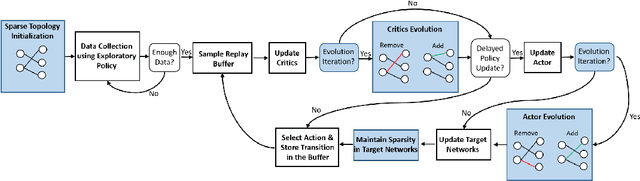
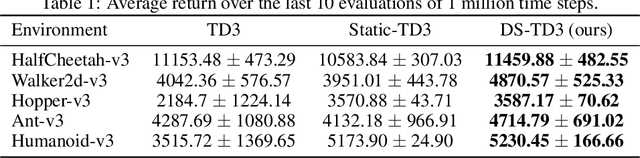


Deep reinforcement learning has achieved significant success in many decision-making tasks in various fields. However, it requires a large training time of dense neural networks to obtain a good performance. This hinders its applicability on low-resource devices where memory and computation are strictly constrained. In a step towards enabling deep reinforcement learning agents to be applied to low-resource devices, in this work, we propose for the first time to dynamically train deep reinforcement learning agents with sparse neural networks from scratch. We adopt the evolution principles of dynamic sparse training in the reinforcement learning paradigm and introduce a training algorithm that optimizes the sparse topology and the weight values jointly to dynamically fit the incoming data. Our approach is easy to be integrated into existing deep reinforcement learning algorithms and has many favorable advantages. First, it allows for significant compression of the network size which reduces the memory and computation costs substantially. This would accelerate not only the agent inference but also its training process. Second, it speeds up the agent learning process and allows for reducing the number of required training steps. Third, it can achieve higher performance than training the dense counterpart network. We evaluate our approach on OpenAI gym continuous control tasks. The experimental results show the effectiveness of our approach in achieving higher performance than one of the state-of-art baselines with a 50\% reduction in the network size and floating-point operations (FLOPs). Moreover, our proposed approach can reach the same performance achieved by the dense network with a 40-50\% reduction in the number of training steps.
Sparse Training Theory for Scalable and Efficient Agents
Mar 02, 2021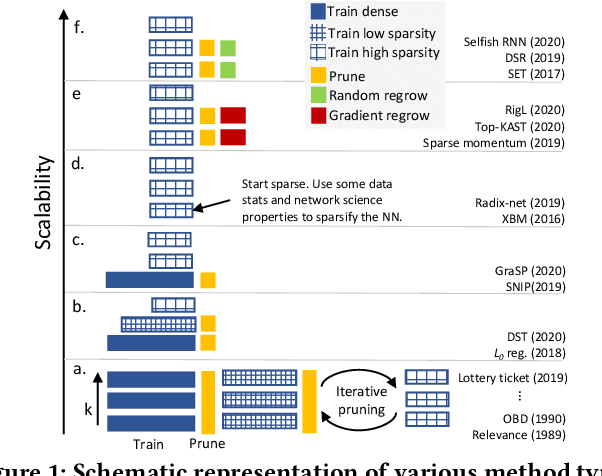
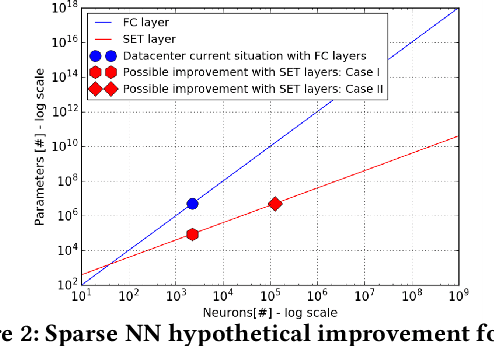
A fundamental task for artificial intelligence is learning. Deep Neural Networks have proven to cope perfectly with all learning paradigms, i.e. supervised, unsupervised, and reinforcement learning. Nevertheless, traditional deep learning approaches make use of cloud computing facilities and do not scale well to autonomous agents with low computational resources. Even in the cloud, they suffer from computational and memory limitations, and they cannot be used to model adequately large physical worlds for agents which assume networks with billions of neurons. These issues are addressed in the last few years by the emerging topic of sparse training, which trains sparse networks from scratch. This paper discusses sparse training state-of-the-art, its challenges and limitations while introducing a couple of new theoretical research directions which has the potential of alleviating sparse training limitations to push deep learning scalability well beyond its current boundaries. Nevertheless, the theoretical advancements impact in complex multi-agents settings is discussed from a real-world perspective, using the smart grid case study.