 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Training Theory for Scalable and Efficient Agents
Mar 02, 2021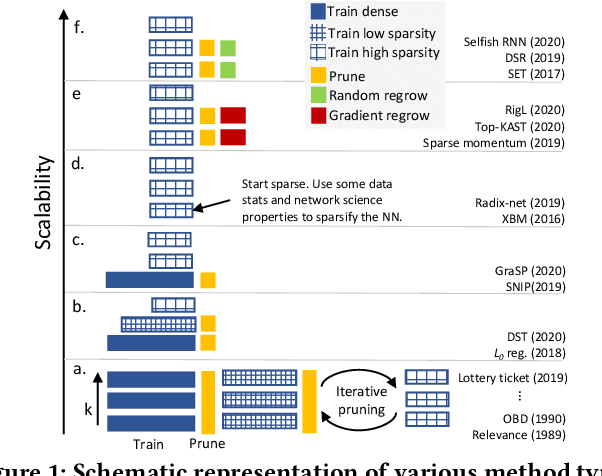
A fundamental task for artificial intelligence is learning. Deep Neural Networks have proven to cope perfectly with all learning paradigms, i.e. supervised, unsupervised, and reinforcement learning. Nevertheless, traditional deep learning approaches make use of cloud computing facilities and do not scale well to autonomous agents with low computational resources. Even in the cloud, they suffer from computational and memory limitations, and they cannot be used to model adequately large physical worlds for agents which assume networks with billions of neurons. These issues are addressed in the last few years by the emerging topic of sparse training, which trains sparse networks from scratch. This paper discusses sparse training state-of-the-art, its challenges and limitations while introducing a couple of new theoretical research directions which has the potential of alleviating sparse training limitations to push deep learning scalability well beyond its current boundaries. Nevertheless, the theoretical advancements impact in complex multi-agents settings is discussed from a real-world perspective, using the smart grid case study.
Scalable Training of Artificial Neural Networks with Adaptive Sparse Connectivity inspired by Network Science
Jun 20, 2018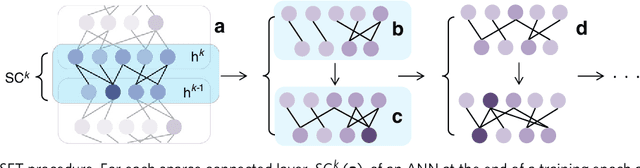
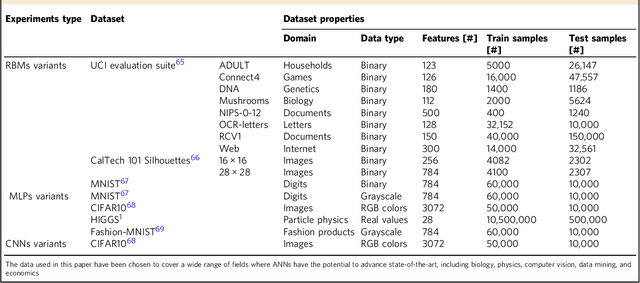
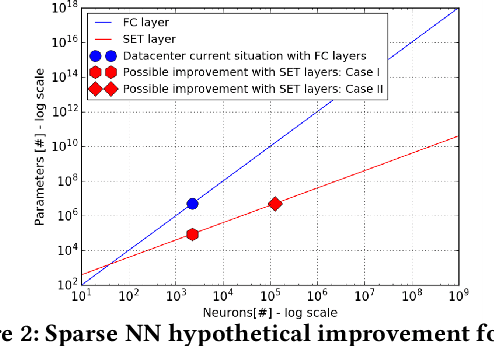
Through the success of deep learning in various domains, artificial neural networks are currently among the most used artificial intelligence methods. Taking inspiration from the network properties of biological neural networks (e.g. sparsity, scale-freeness), we argue that (contrary to general practice) artificial neural networks, too, should not have fully-connected layers. Here we propose sparse evolutionary training of artificial neural networks, an algorithm which evolves an initial sparse topology (Erd\H{o}s-R\'enyi random graph) of two consecutive layers of neurons into a scale-free topology, during learning. Our method replaces artificial neural networks fully-connected layers with sparse ones before training, reducing quadratically the number of parameters, with no decrease in accuracy. We demonstrate our claims on restricted Boltzmann machines, multi-layer perceptrons, and convolutional neural networks for unsupervised and supervised learning on 15 datasets. Our approach has the potential to enable artificial neural networks to scale up beyond what is currently possible.
* 18 pages
On-line Building Energy Optimization using Deep Reinforcement Learning
Jul 18, 2017

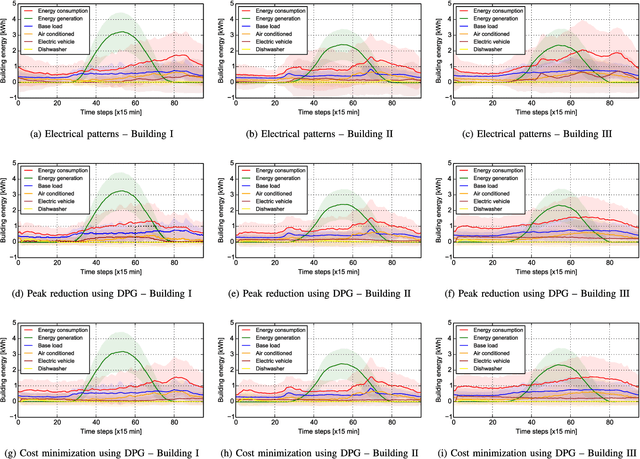
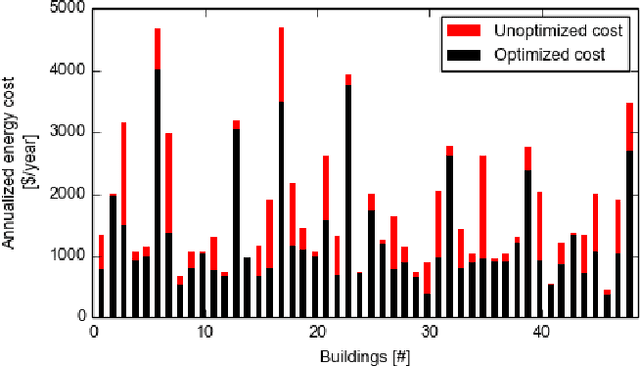
Unprecedented high volumes of data are becoming available with the growth of the advanced metering infrastructure. These are expected to benefit planning and operation of the future power system, and to help the customers transition from a passive to an active role. In this paper, we explore for the first time in the smart grid context the benefits of using Deep Reinforcement Learning, a hybrid type of methods that combines Reinforcement Learning with Deep Learning, to perform on-line optimization of schedules for building energy management systems. The learning procedure was explored using two methods, Deep Q-learning and Deep Policy Gradient, both of them being extended to perform multiple actions simultaneously. The proposed approach was validated on the large-scale Pecan Street Inc. database. This highly-dimensional database includes information about photovoltaic power generation, electric vehicles as well as buildings appliances. Moreover, these on-line energy scheduling strategies could be used to provide real-time feedback to consumers to encourage more efficient use of electricity.
A topological insight into restricted Boltzmann machines
Jul 18, 2016

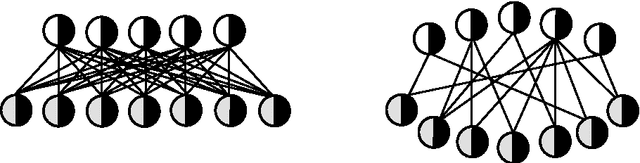

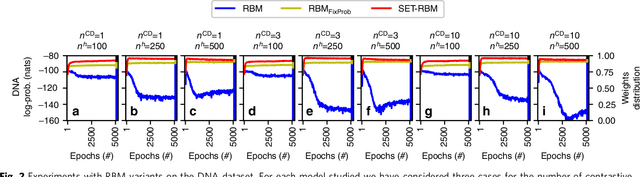
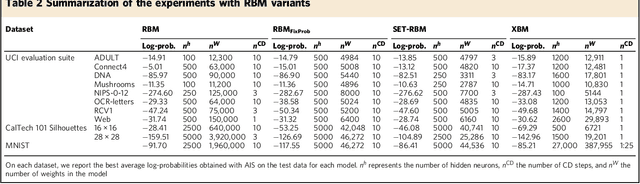
Restricted Boltzmann Machines (RBMs) and models derived from them have been successfully used as basic building blocks in deep artificial neural networks for automatic features extraction, unsupervised weights initialization, but also as density estimators. Thus, their generative and discriminative capabilities, but also their computational time are instrumental to a wide range of applications. Our main contribution is to look at RBMs from a topological perspective, bringing insights from network science. Firstly, here we show that RBMs and Gaussian RBMs (GRBMs) are bipartite graphs which naturally have a small-world topology. Secondly, we demonstrate both on synthetic and real-world datasets that by constraining RBMs and GRBMs to a scale-free topology (while still considering local neighborhoods and data distribution), we reduce the number of weights that need to be computed by a few orders of magnitude, at virtually no loss in generative performance. Thirdly, we show that, for a fixed number of weights, our proposed sparse models (which by design have a higher number of hidden neurons) achieve better generative capabilities than standard fully connected RBMs and GRBMs (which by design have a smaller number of hidden neurons), at no additional computational costs.
Energy Disaggregation for Real-Time Building Flexibility Detection
May 06, 2016

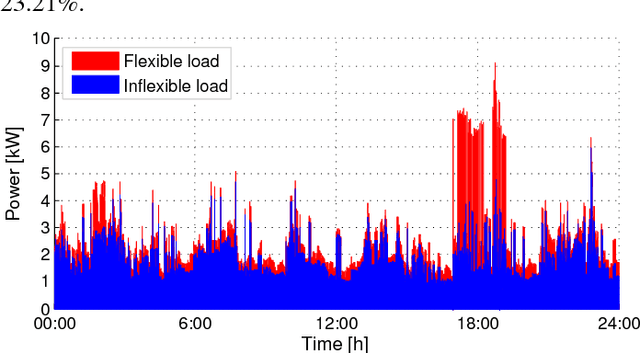
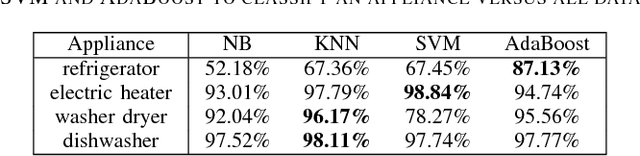
Energy is a limited resource which has to be managed wisely, taking into account both supply-demand matching and capacity constraints in the distribution grid. One aspect of the smart energy management at the building level is given by the problem of real-time detection of flexible demand available. In this paper we propose the use of energy disaggregation techniques to perform this task. Firstly, we investigate the use of existing classification methods to perform energy disaggregation. A comparison is performed between four classifiers, namely Naive Bayes, k-Nearest Neighbors, Support Vector Machine and AdaBoost. Secondly, we propose the use of Restricted Boltzmann Machine to automatically perform feature extraction. The extracted features are then used as inputs to the four classifiers and consequently shown to improve their accuracy. The efficiency of our approach is demonstrated on a real database consisting of detailed appliance-level measurements with high temporal resolution, which has been used for energy disaggregation in previous studies, namely the REDD. The results show robustness and good generalization capabilities to newly presented buildings with at least 96% accuracy.
Support Vector Machine in Prediction of Building Energy Demand Using Pseudo Dynamic Approach
Jul 17, 2015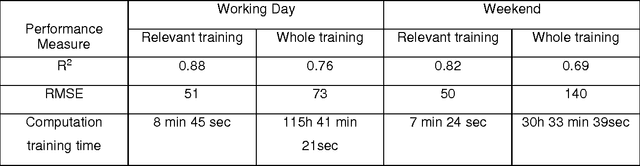


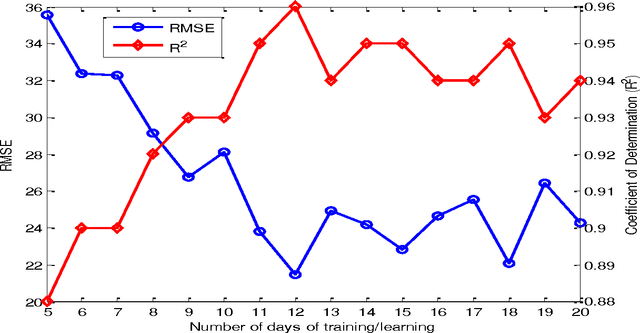
Building's energy consumption prediction is a major concern in the recent years and many efforts have been achieved in order to improve the energy management of buildings. In particular, the prediction of energy consumption in building is essential for the energy operator to build an optimal operating strategy, which could be integrated to building's energy management system (BEMS). This paper proposes a prediction model for building energy consumption using support vector machine (SVM). Data-driven model, for instance, SVM is very sensitive to the selection of training data. Thus the relevant days data selection method based on Dynamic Time Warping is used to train SVM model. In addition, to encompass thermal inertia of building, pseudo dynamic model is applied since it takes into account information of transition of energy consumption effects and occupancy profile. Relevant days data selection and whole training data model is applied to the case studies of Ecole des Mines de Nantes, France Office building. The results showed that support vector machine based on relevant data selection method is able to predict the energy consumption of building with a high accuracy in compare to whole data training. In addition, relevant data selection method is computationally cheaper (around 8 minute training time) in contrast to whole data training (around 31 hour for weekend and 116 hour for working days) and reveals realistic control implementation for online system as well.