 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Peer Review at Scale: The AAAI-26 AI Review Pilot
Apr 15, 2026Scientific peer review faces mounting strain as submission volumes surge, making it increasingly difficult to sustain review quality, consistency, and timeliness. Recent advances in AI have led the community to consider its use in peer review, yet a key unresolved question is whether AI can generate technically sound reviews at real-world conference scale. Here we report the first large-scale field deployment of AI-assisted peer review: every main-track submission at AAAI-26 received one clearly identified AI review from a state-of-the-art system. The system combined frontier models, tool use, and safeguards in a multi-stage process to generate reviews for all 22,977 full-review papers in less than a day. A large-scale survey of AAAI-26 authors and program committee members showed that participants not only found AI reviews useful, but actually preferred them to human reviews on key dimensions such as technical accuracy and research suggestions. We also introduce a novel benchmark and find that our system substantially outperforms a simple LLM-generated review baseline at detecting a variety of scientific weaknesses. Together, these results show that state-of-the-art AI methods can already make meaningful contributions to scientific peer review at conference scale, opening a path toward the next generation of synergistic human-AI teaming for evaluating research.
GUIDE: Reinforcement Learning for Behavioral Action Support in Type 1 Diabetes
Apr 01, 2026Type 1 Diabetes (T1D) management requires continuous adjustment of insulin and lifestyle behaviors to maintain blood glucose within a safe target range. Although automated insulin delivery (AID) systems have improved glycemic outcomes, many patients still fail to achieve recommended clinical targets, warranting new approaches to improve glucose control in patients with T1D. While reinforcement learning (RL) has been utilized as a promising approach, current RL-based methods focus primarily on insulin-only treatment and do not provide behavioral recommendations for glucose control. To address this gap, we propose GUIDE, an RL-based decision-support framework designed to complement AID technologies by providing behavioral recommendations to prevent abnormal glucose events. GUIDE generates structured actions defined by intervention type, magnitude, and timing, including bolus insulin administration and carbohydrate intake events. GUIDE integrates a patient-specific glucose level predictor trained on real-world continuous glucose monitoring data and supports both offline and online RL algorithms within a unified environment. We evaluate both off-policy and on-policy methods across 25 individuals with T1D using standardized glycemic metrics. Among the evaluated approaches, the CQL-BC algorithm demonstrates the highest average time-in-range, reaching 85.49% while maintaining low hypoglycemia exposures. Behavioral similarity analysis further indicates that the learned CQL-BC policy preserves key structural characteristics of patient action patterns, achieving a mean cosine similarity of 0.87 $\pm$ 0.09 across subjects. These findings suggest that conservative offline RL with a structured behavioral action space can provide clinically meaningful and behaviorally plausible decision support for personalized diabetes management.
ExpertGen: Scalable Sim-to-Real Expert Policy Learning from Imperfect Behavior Priors
Mar 16, 2026Learning generalizable and robust behavior cloning policies requires large volumes of high-quality robotics data. While human demonstrations (e.g., through teleoperation) serve as the standard source for expert behaviors, acquiring such data at scale in the real world is prohibitively expensive. This paper introduces ExpertGen, a framework that automates expert policy learning in simulation to enable scalable sim-to-real transfer. ExpertGen first initializes a behavior prior using a diffusion policy trained on imperfect demonstrations, which may be synthesized by large language models or provided by humans. Reinforcement learning is then used to steer this prior toward high task success by optimizing the diffusion model's initial noise while keep original policy frozen. By keeping the pretrained diffusion policy frozen, ExpertGen regularizes exploration to remain within safe, human-like behavior manifolds, while also enabling effective learning with only sparse rewards. Empirical evaluations on challenging manipulation benchmarks demonstrate that ExpertGen reliably produces high-quality expert policies with no reward engineering. On industrial assembly tasks, ExpertGen achieves a 90.5% overall success rate, while on long-horizon manipulation tasks it attains 85% overall success, outperforming all baseline methods. The resulting policies exhibit dexterous control and remain robust across diverse initial configurations and failure states. To validate sim-to-real transfer, the learned state-based expert policies are further distilled into visuomotor policies via DAgger and successfully deployed on real robotic hardware.
Simple Recipe Works: Vision-Language-Action Models are Natural Continual Learners with Reinforcement Learning
Mar 12, 2026Continual Reinforcement Learning (CRL) for Vision-Language-Action (VLA) models is a promising direction toward self-improving embodied agents that can adapt in openended, evolving environments. However, conventional wisdom from continual learning suggests that naive Sequential Fine-Tuning (Seq. FT) leads to catastrophic forgetting, necessitating complex CRL strategies. In this work, we take a step back and conduct a systematic study of CRL for large pretrained VLAs across three models and five challenging lifelong RL benchmarks. We find that, contrary to established belief, simple Seq. FT with low-rank adaptation (LoRA) is remarkably strong: it achieves high plasticity, exhibits little to no forgetting, and retains strong zero-shot generalization, frequently outperforming more sophisticated CRL methods. Through detailed analysis, we show that this robustness arises from a synergy between the large pretrained model, parameter-efficient adaptation, and on-policy RL. Together, these components reshape the stability-plasticity trade-off, making continual adaptation both stable and scalable. Our results position Sequential Fine-Tuning as a powerful method for continual RL with VLAs and provide new insights into lifelong learning in the large model era. Code is available at github.com/UT-Austin-RobIn/continual-vla-rl.
Large-Language-Model-Guided State Estimation for Partially Observable Task and Motion Planning
Mar 04, 2026Robot planning in partially observable environments, where not all objects are known or visible, is a challenging problem, as it requires reasoning under uncertainty through partially observable Markov decision processes. During the execution of a computed plan, a robot may unexpectedly observe task-irrelevant objects, which are typically ignored by naive planners. In this work, we propose incorporating two types of common-sense knowledge: (1) certain objects are more likely to be found in specific locations; and (2) similar objects are likely to be co-located, while dissimilar objects are less likely to be found together. Manually engineering such knowledge is complex, so we explore leveraging the powerful common-sense reasoning capabilities of large language models (LLMs). Our planning and execution framework, CoCo-TAMP, introduces a hierarchical state estimation that uses LLM-guided information to shape the belief over task-relevant objects, enabling efficient solutions to long-horizon task and motion planning problems. In experiments, CoCo-TAMP achieves an average reduction of 62.7 in planning and execution time in simulation, and 72.6 in real-world demonstrations, compared to a baseline that does not incorporate either type of common-sense knowledge.
Factored Latent Action World Models
Feb 18, 2026Learning latent actions from action-free video has emerged as a powerful paradigm for scaling up controllable world model learning. Latent actions provide a natural interface for users to iteratively generate and manipulate videos. However, most existing approaches rely on monolithic inverse and forward dynamics models that learn a single latent action to control the entire scene, and therefore struggle in complex environments where multiple entities act simultaneously. This paper introduces Factored Latent Action Model (FLAM), a factored dynamics framework that decomposes the scene into independent factors, each inferring its own latent action and predicting its own next-step factor value. This factorized structure enables more accurate modeling of complex multi-entity dynamics and improves video generation quality in action-free video settings compared to monolithic models. Based on experiments on both simulation and real-world multi-entity datasets, we find that FLAM outperforms prior work in prediction accuracy and representation quality, and facilitates downstream policy learning, demonstrating the benefits of factorized latent action models.
The Trajectory Alignment Coefficient in Two Acts: From Reward Tuning to Reward Learning
Jan 23, 2026The success of reinforcement learning (RL) is fundamentally tied to having a reward function that accurately reflects the task objective. Yet, designing reward functions is notoriously time-consuming and prone to misspecification. To address this issue, our first goal is to understand how to support RL practitioners in specifying appropriate weights for a reward function. We leverage the Trajectory Alignment Coefficient (TAC), a metric that evaluates how closely a reward function's induced preferences match those of a domain expert. To evaluate whether TAC provides effective support in practice, we conducted a human-subject study in which RL practitioners tuned reward weights for Lunar Lander. We found that providing TAC during reward tuning led participants to produce more performant reward functions and report lower cognitive workload relative to standard tuning without TAC. However, the study also underscored that manual reward design, even with TAC, remains labor-intensive. This limitation motivated our second goal: to learn a reward model that maximizes TAC directly. Specifically, we propose Soft-TAC, a differentiable approximation of TAC that can be used as a loss function to train reward models from human preference data. Validated in the racing simulator Gran Turismo 7, reward models trained using Soft-TAC successfully captured preference-specific objectives, resulting in policies with qualitatively more distinct behaviors than models trained with standard Cross-Entropy loss. This work demonstrates that TAC can serve as both a practical tool for guiding reward tuning and a reward learning objective in complex domains.
Harmful Traits of AI Companions
Nov 18, 2025
Amid the growing prevalence of human -- AI interaction, large language models and other AI-based entities increasingly provide forms of companionship to human users. Such AI companionship -- i.e., bonded relationships between humans and AI systems that resemble the relationships people have with family members, friends, and romantic partners -- might substantially benefit humans. Yet such relationships can also do profound harm. We propose a framework for analyzing potential negative impacts of AI companionship by identifying specific harmful traits of AI companions and speculatively mapping causal pathways back from these traits to possible causes and forward to potential harmful effects. We provide detailed, structured analysis of four potentially harmful traits -- the absence of natural endpoints for relationships, vulnerability to product sunsetting, high attachment anxiety, and propensity to engender protectiveness -- and briefly discuss fourteen others. For each trait, we propose hypotheses connecting causes -- such as misaligned optimization objectives and the digital nature of AI companions -- to fundamental harms -- including reduced autonomy, diminished quality of human relationships, and deception. Each hypothesized causal connection identifies a target for potential empirical evaluation. Our analysis examines harms at three levels: to human partners directly, to their relationships with other humans, and to society broadly. We examine how existing law struggles to address these emerging harms, discuss potential benefits of AI companions, and conclude with design recommendations for mitigating risks. This analysis offers immediate suggestions for reducing risks while laying a foundation for deeper investigation of this critical but understudied topic.
Terrain Costmap Generation via Scaled Preference Conditioning
Nov 14, 2025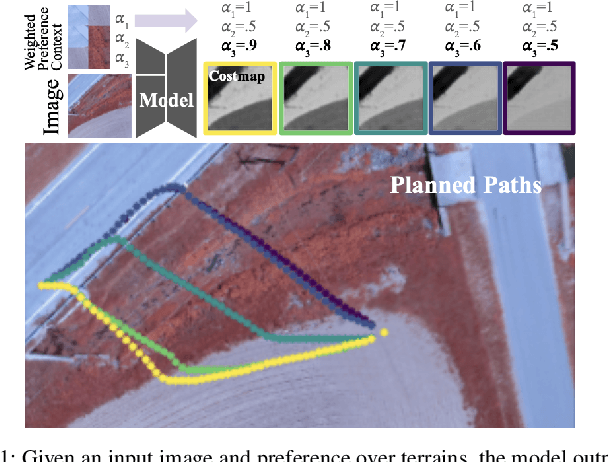
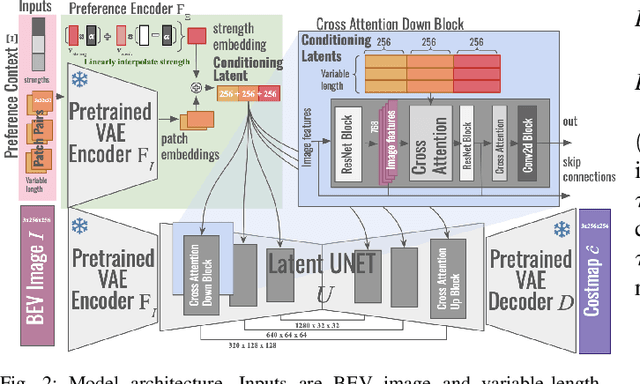
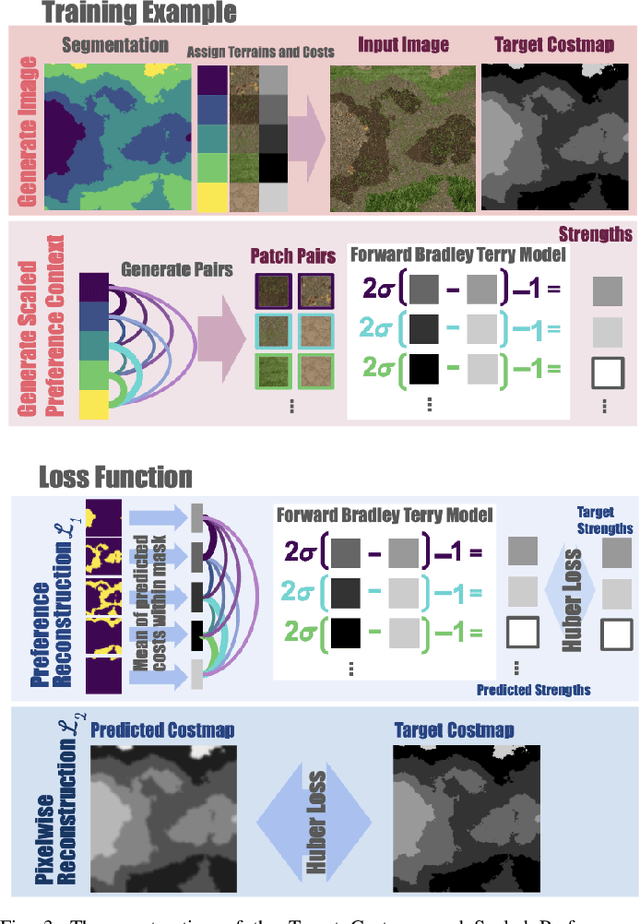

Successful autonomous robot navigation in off-road domains requires the ability to generate high-quality terrain costmaps that are able to both generalize well over a wide variety of terrains and rapidly adapt relative costs at test time to meet mission-specific needs. Existing approaches for costmap generation allow for either rapid test-time adaptation of relative costs (e.g., semantic segmentation methods) or generalization to new terrain types (e.g., representation learning methods), but not both. In this work, we present scaled preference conditioned all-terrain costmap generation (SPACER), a novel approach for generating terrain costmaps that leverages synthetic data during training in order to generalize well to new terrains, and allows for rapid test-time adaptation of relative costs by conditioning on a user-specified scaled preference context. Using large-scale aerial maps, we provide empirical evidence that SPACER outperforms other approaches at generating costmaps for terrain navigation, with the lowest measured regret across varied preferences in five of seven environments for global path planning.
Out-of-Distribution Generalization with a SPARC: Racing 100 Unseen Vehicles with a Single Policy
Nov 12, 2025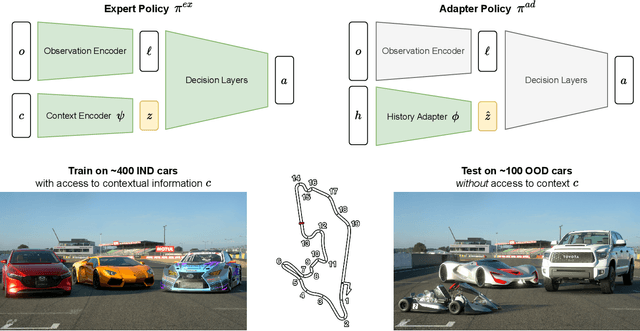
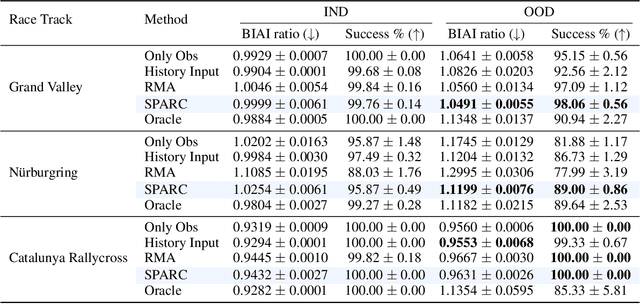
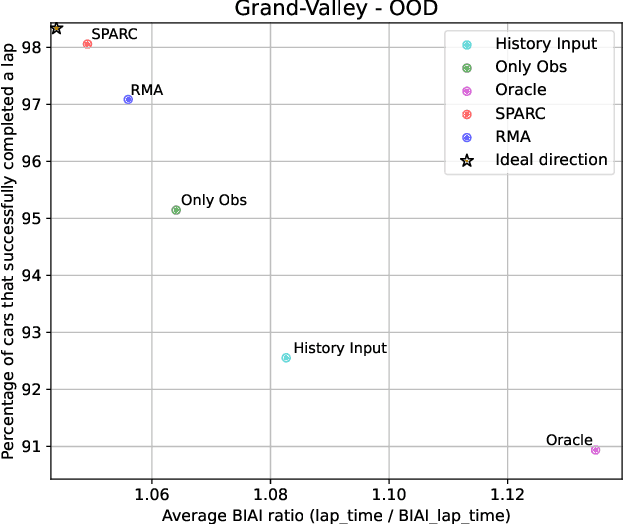
Generalization to unseen environments is a significant challenge in the field of robotics and control. In this work, we focus on contextual reinforcement learning, where agents act within environments with varying contexts, such as self-driving cars or quadrupedal robots that need to operate in different terrains or weather conditions than they were trained for. We tackle the critical task of generalizing to out-of-distribution (OOD) settings, without access to explicit context information at test time. Recent work has addressed this problem by training a context encoder and a history adaptation module in separate stages. While promising, this two-phase approach is cumbersome to implement and train. We simplify the methodology and introduce SPARC: single-phase adaptation for robust control. We test SPARC on varying contexts within the high-fidelity racing simulator Gran Turismo 7 and wind-perturbed MuJoCo environments, and find that it achieves reliable and robust OOD generalization.