 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Benchmark for Generalizing Across Diverse Team Strategies in Competitive Pokémon
Jun 12, 2025Developing AI agents that can robustly adapt to dramatically different strategic landscapes without retraining is a central challenge for multi-agent learning. Pok\'emon Video Game Championships (VGC) is a domain with an extraordinarily large space of possible team configurations of approximately $10^{139}$ - far larger than those of Dota or Starcraft. The highly discrete, combinatorial nature of team building in Pok\'emon VGC causes optimal strategies to shift dramatically depending on both the team being piloted and the opponent's team, making generalization uniquely challenging. To advance research on this problem, we introduce VGC-Bench: a benchmark that provides critical infrastructure, standardizes evaluation protocols, and supplies human-play datasets and a range of baselines - from large-language-model agents and behavior cloning to reinforcement learning and empirical game-theoretic methods such as self-play, fictitious play, and double oracle. In the restricted setting where an agent is trained and evaluated on a single-team configuration, our methods are able to win against a professional VGC competitor. We extensively evaluated all baseline methods over progressively larger team sets and find that even the best-performing algorithm in the single-team setting struggles at scaling up as team size grows. Thus, policy generalization across diverse team strategies remains an open challenge for the community. Our code is open sourced at https://github.com/cameronangliss/VGC-Bench.
SLAC: Simulation-Pretrained Latent Action Space for Whole-Body Real-World RL
Jun 07, 2025Building capable household and industrial robots requires mastering the control of versatile, high-degree-of-freedom (DoF) systems such as mobile manipulators. While reinforcement learning (RL) holds promise for autonomously acquiring robot control policies, scaling it to high-DoF embodiments remains challenging. Direct RL in the real world demands both safe exploration and high sample efficiency, which are difficult to achieve in practice. Sim-to-real RL, on the other hand, is often brittle due to the reality gap. This paper introduces SLAC, a method that renders real-world RL feasible for complex embodiments by leveraging a low-fidelity simulator to pretrain a task-agnostic latent action space. SLAC trains this latent action space via a customized unsupervised skill discovery method designed to promote temporal abstraction, disentanglement, and safety, thereby facilitating efficient downstream learning. Once a latent action space is learned, SLAC uses it as the action interface for a novel off-policy RL algorithm to autonomously learn downstream tasks through real-world interactions. We evaluate SLAC against existing methods on a suite of bimanual mobile manipulation tasks, where it achieves state-of-the-art performance. Notably, SLAC learns contact-rich whole-body tasks in under an hour of real-world interactions, without relying on any demonstrations or hand-crafted behavior priors. More information, code, and videos at robo-rl.github.io
SkiLD: Unsupervised Skill Discovery Guided by Factor Interactions
Oct 24, 2024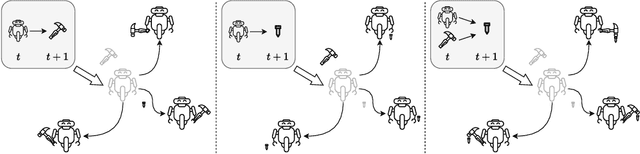
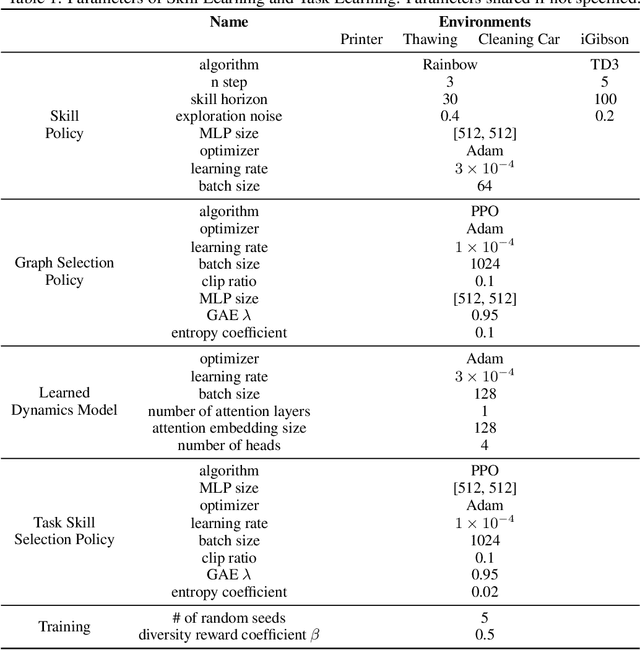
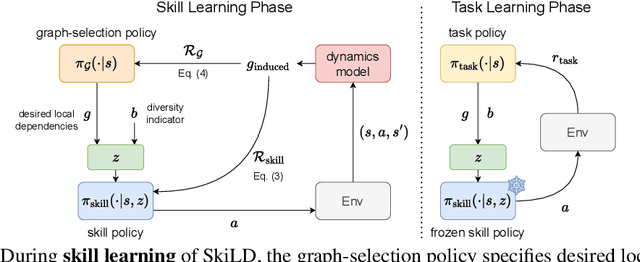
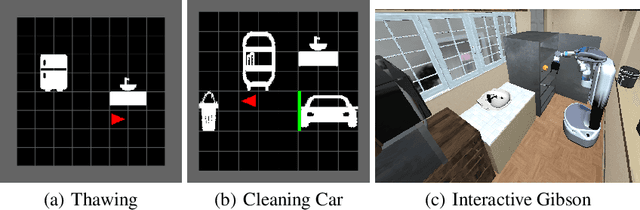
Unsupervised skill discovery carries the promise that an intelligent agent can learn reusable skills through autonomous, reward-free environment interaction. Existing unsupervised skill discovery methods learn skills by encouraging distinguishable behaviors that cover diverse states. However, in complex environments with many state factors (e.g., household environments with many objects), learning skills that cover all possible states is impossible, and naively encouraging state diversity often leads to simple skills that are not ideal for solving downstream tasks. This work introduces Skill Discovery from Local Dependencies (Skild), which leverages state factorization as a natural inductive bias to guide the skill learning process. The key intuition guiding Skild is that skills that induce <b>diverse interactions</b> between state factors are often more valuable for solving downstream tasks. To this end, Skild develops a novel skill learning objective that explicitly encourages the mastering of skills that effectively induce different interactions within an environment. We evaluate Skild in several domains with challenging, long-horizon sparse reward tasks including a realistic simulated household robot domain, where Skild successfully learns skills with clear semantic meaning and shows superior performance compared to existing unsupervised reinforcement learning methods that only maximize state coverage.
Learning to Look: Seeking Information for Decision Making via Policy Factorization
Oct 24, 2024



Many robot manipulation tasks require active or interactive exploration behavior in order to be performed successfully. Such tasks are ubiquitous in embodied domains, where agents must actively search for the information necessary for each stage of a task, e.g., moving the head of the robot to find information relevant to manipulation, or in multi-robot domains, where one scout robot may search for the information that another robot needs to make informed decisions. We identify these tasks with a new type of problem, factorized Contextual Markov Decision Processes, and propose DISaM, a dual-policy solution composed of an information-seeking policy that explores the environment to find the relevant contextual information and an information-receiving policy that exploits the context to achieve the manipulation goal. This factorization allows us to train both policies separately, using the information-receiving one to provide reward to train the information-seeking policy. At test time, the dual agent balances exploration and exploitation based on the uncertainty the manipulation policy has on what the next best action is. We demonstrate the capabilities of our dual policy solution in five manipulation tasks that require information-seeking behaviors, both in simulation and in the real-world, where DISaM significantly outperforms existing methods. More information at https://robin-lab.cs.utexas.edu/learning2look/.
Disentangled Unsupervised Skill Discovery for Efficient Hierarchical Reinforcement Learning
Oct 15, 2024



A hallmark of intelligent agents is the ability to learn reusable skills purely from unsupervised interaction with the environment. However, existing unsupervised skill discovery methods often learn entangled skills where one skill variable simultaneously influences many entities in the environment, making downstream skill chaining extremely challenging. We propose Disentangled Unsupervised Skill Discovery (DUSDi), a method for learning disentangled skills that can be efficiently reused to solve downstream tasks. DUSDi decomposes skills into disentangled components, where each skill component only affects one factor of the state space. Importantly, these skill components can be concurrently composed to generate low-level actions, and efficiently chained to tackle downstream tasks through hierarchical Reinforcement Learning. DUSDi defines a novel mutual-information-based objective to enforce disentanglement between the influences of different skill components, and utilizes value factorization to optimize this objective efficiently. Evaluated in a set of challenging environments, DUSDi successfully learns disentangled skills, and significantly outperforms previous skill discovery methods when it comes to applying the learned skills to solve downstream tasks. Code and skills visualization at jiahenghu.github.io/DUSDi-site/.
FLaRe: Achieving Masterful and Adaptive Robot Policies with Large-Scale Reinforcement Learning Fine-Tuning
Sep 25, 2024



In recent years, the Robotics field has initiated several efforts toward building generalist robot policies through large-scale multi-task Behavior Cloning. However, direct deployments of these policies have led to unsatisfactory performance, where the policy struggles with unseen states and tasks. How can we break through the performance plateau of these models and elevate their capabilities to new heights? In this paper, we propose FLaRe, a large-scale Reinforcement Learning fine-tuning framework that integrates robust pre-trained representations, large-scale training, and gradient stabilization techniques. Our method aligns pre-trained policies towards task completion, achieving state-of-the-art (SoTA) performance both on previously demonstrated and on entirely novel tasks and embodiments. Specifically, on a set of long-horizon mobile manipulation tasks, FLaRe achieves an average success rate of 79.5% in unseen environments, with absolute improvements of +23.6% in simulation and +30.7% on real robots over prior SoTA methods. By utilizing only sparse rewards, our approach can enable generalizing to new capabilities beyond the pretraining data with minimal human effort. Moreover, we demonstrate rapid adaptation to new embodiments and behaviors with less than a day of fine-tuning. Videos can be found on the project website at https://robot-flare.github.io/
Deep Reinforcement Learning for Robotics: A Survey of Real-World Successes
Aug 07, 2024Reinforcement learning (RL), particularly its combination with deep neural networks referred to as deep RL (DRL), has shown tremendous promise across a wide range of applications, suggesting its potential for enabling the development of sophisticated robotic behaviors. Robotics problems, however, pose fundamental difficulties for the application of RL, stemming from the complexity and cost of interacting with the physical world. This article provides a modern survey of DRL for robotics, with a particular focus on evaluating the real-world successes achieved with DRL in realizing several key robotic competencies. Our analysis aims to identify the key factors underlying those exciting successes, reveal underexplored areas, and provide an overall characterization of the status of DRL in robotics. We highlight several important avenues for future work, emphasizing the need for stable and sample-efficient real-world RL paradigms, holistic approaches for discovering and integrating various competencies to tackle complex long-horizon, open-world tasks, and principled development and evaluation procedures. This survey is designed to offer insights for both RL practitioners and roboticists toward harnessing RL's power to create generally capable real-world robotic systems.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
TeleMoMa: A Modular and Versatile Teleoperation System for Mobile Manipulation
Mar 12, 2024



A critical bottleneck limiting imitation learning in robotics is the lack of data. This problem is more severe in mobile manipulation, where collecting demonstrations is harder than in stationary manipulation due to the lack of available and easy-to-use teleoperation interfaces. In this work, we demonstrate TeleMoMa, a general and modular interface for whole-body teleoperation of mobile manipulators. TeleMoMa unifies multiple human interfaces including RGB and depth cameras, virtual reality controllers, keyboard, joysticks, etc., and any combination thereof. In its more accessible version, TeleMoMa works using simply vision (e.g., an RGB-D camera), lowering the entry bar for humans to provide mobile manipulation demonstrations. We demonstrate the versatility of TeleMoMa by teleoperating several existing mobile manipulators - PAL Tiago++, Toyota HSR, and Fetch - in simulation and the real world. We demonstrate the quality of the demonstrations collected with TeleMoMa by training imitation learning policies for mobile manipulation tasks involving synchronized whole-body motion. Finally, we also show that TeleMoMa's teleoperation channel enables teleoperation on site, looking at the robot, or remote, sending commands and observations through a computer network, and perform user studies to evaluate how easy it is for novice users to learn to collect demonstrations with different combinations of human interfaces enabled by our system. We hope TeleMoMa becomes a helpful tool for the community enabling researchers to collect whole-body mobile manipulation demonstrations. For more information and video results, https://robin-lab.cs.utexas.edu/telemoma-web.
ELDEN: Exploration via Local Dependencies
Oct 12, 2023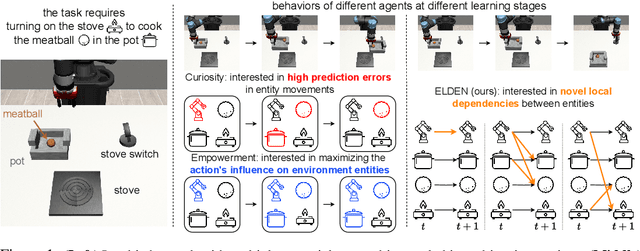
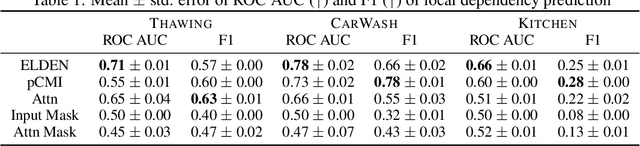
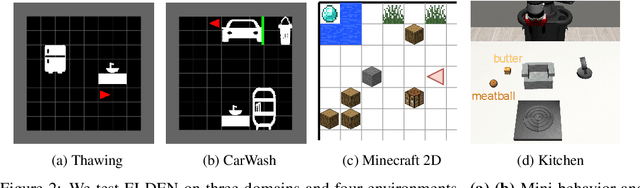

Tasks with large state space and sparse rewards present a longstanding challenge to reinforcement learning. In these tasks, an agent needs to explore the state space efficiently until it finds a reward. To deal with this problem, the community has proposed to augment the reward function with intrinsic reward, a bonus signal that encourages the agent to visit interesting states. In this work, we propose a new way of defining interesting states for environments with factored state spaces and complex chained dependencies, where an agent's actions may change the value of one entity that, in order, may affect the value of another entity. Our insight is that, in these environments, interesting states for exploration are states where the agent is uncertain whether (as opposed to how) entities such as the agent or objects have some influence on each other. We present ELDEN, Exploration via Local DepENdencies, a novel intrinsic reward that encourages the discovery of new interactions between entities. ELDEN utilizes a novel scheme -- the partial derivative of the learned dynamics to model the local dependencies between entities accurately and computationally efficiently. The uncertainty of the predicted dependencies is then used as an intrinsic reward to encourage exploration toward new interactions. We evaluate the performance of ELDEN on four different domains with complex dependencies, ranging from 2D grid worlds to 3D robotic tasks. In all domains, ELDEN correctly identifies local dependencies and learns successful policies, significantly outperforming previous state-of-the-art exploration methods.