 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataMIL: Selecting Data for Robot Imitation Learning with Datamodels
May 14, 2025
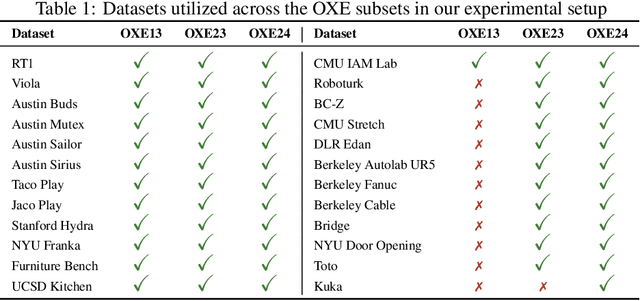


Recently, the robotics community has amassed ever larger and more diverse datasets to train generalist robot policies. However, while these policies achieve strong mean performance across a variety of tasks, they often underperform on individual, specialized tasks and require further tuning on newly acquired task-specific data. Combining task-specific data with carefully curated subsets of large prior datasets via co-training can produce better specialized policies, but selecting data naively may actually harm downstream performance. To address this, we introduce DataMIL, a policy-driven data selection framework built on the datamodels paradigm that reasons about data selection in an end-to-end manner, using the policy itself to identify which data points will most improve performance. Unlike standard practices that filter data using human notions of quality (e.g., based on semantic or visual similarity), DataMIL directly optimizes data selection for task success, allowing us to select data that enhance the policy while dropping data that degrade it. To avoid performing expensive rollouts in the environment during selection, we use a novel surrogate loss function on task-specific data, allowing us to use DataMIL in the real world without degrading performance. We validate our approach on a suite of more than 60 simulation and real-world manipulation tasks - most notably showing successful data selection from the Open X-Embodiment datasets-demonstrating consistent gains in success rates and superior performance over multiple baselines. Our results underscore the importance of end-to-end, performance-aware data selection for unlocking the potential of large prior datasets in robotics. More information at https://robin-lab.cs.utexas.edu/datamodels4imitation/
Learning to Look: Seeking Information for Decision Making via Policy Factorization
Oct 24, 2024



Many robot manipulation tasks require active or interactive exploration behavior in order to be performed successfully. Such tasks are ubiquitous in embodied domains, where agents must actively search for the information necessary for each stage of a task, e.g., moving the head of the robot to find information relevant to manipulation, or in multi-robot domains, where one scout robot may search for the information that another robot needs to make informed decisions. We identify these tasks with a new type of problem, factorized Contextual Markov Decision Processes, and propose DISaM, a dual-policy solution composed of an information-seeking policy that explores the environment to find the relevant contextual information and an information-receiving policy that exploits the context to achieve the manipulation goal. This factorization allows us to train both policies separately, using the information-receiving one to provide reward to train the information-seeking policy. At test time, the dual agent balances exploration and exploitation based on the uncertainty the manipulation policy has on what the next best action is. We demonstrate the capabilities of our dual policy solution in five manipulation tasks that require information-seeking behaviors, both in simulation and in the real-world, where DISaM significantly outperforms existing methods. More information at https://robin-lab.cs.utexas.edu/learning2look/.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
TeleMoMa: A Modular and Versatile Teleoperation System for Mobile Manipulation
Mar 12, 2024



A critical bottleneck limiting imitation learning in robotics is the lack of data. This problem is more severe in mobile manipulation, where collecting demonstrations is harder than in stationary manipulation due to the lack of available and easy-to-use teleoperation interfaces. In this work, we demonstrate TeleMoMa, a general and modular interface for whole-body teleoperation of mobile manipulators. TeleMoMa unifies multiple human interfaces including RGB and depth cameras, virtual reality controllers, keyboard, joysticks, etc., and any combination thereof. In its more accessible version, TeleMoMa works using simply vision (e.g., an RGB-D camera), lowering the entry bar for humans to provide mobile manipulation demonstrations. We demonstrate the versatility of TeleMoMa by teleoperating several existing mobile manipulators - PAL Tiago++, Toyota HSR, and Fetch - in simulation and the real world. We demonstrate the quality of the demonstrations collected with TeleMoMa by training imitation learning policies for mobile manipulation tasks involving synchronized whole-body motion. Finally, we also show that TeleMoMa's teleoperation channel enables teleoperation on site, looking at the robot, or remote, sending commands and observations through a computer network, and perform user studies to evaluate how easy it is for novice users to learn to collect demonstrations with different combinations of human interfaces enabled by our system. We hope TeleMoMa becomes a helpful tool for the community enabling researchers to collect whole-body mobile manipulation demonstrations. For more information and video results, https://robin-lab.cs.utexas.edu/telemoma-web.
Model-Based Runtime Monitoring with Interactive Imitation Learning
Oct 26, 2023



Robot learning methods have recently made great strides, but generalization and robustness challenges still hinder their widespread deployment. Failing to detect and address potential failures renders state-of-the-art learning systems not combat-ready for high-stakes tasks. Recent advances in interactive imitation learning have presented a promising framework for human-robot teaming, enabling the robots to operate safely and continually improve their performances over long-term deployments. Nonetheless, existing methods typically require constant human supervision and preemptive feedback, limiting their practicality in realistic domains. This work aims to endow a robot with the ability to monitor and detect errors during task execution. We introduce a model-based runtime monitoring algorithm that learns from deployment data to detect system anomalies and anticipate failures. Unlike prior work that cannot foresee future failures or requires failure experiences for training, our method learns a latent-space dynamics model and a failure classifier, enabling our method to simulate future action outcomes and detect out-of-distribution and high-risk states preemptively. We train our method within an interactive imitation learning framework, where it continually updates the model from the experiences of the human-robot team collected using trustworthy deployments. Consequently, our method reduces the human workload needed over time while ensuring reliable task execution. Our method outperforms the baselines across system-level and unit-test metrics, with 23% and 40% higher success rates in simulation and on physical hardware, respectively. More information at https://ut-austin-rpl.github.io/sirius-runtime-monitor/
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
PATO: Policy Assisted TeleOperation for Scalable Robot Data Collection
Dec 09, 2022Large-scale data is an essential component of machine learning as demonstrated in recent advances in natural language processing and computer vision research. However, collecting large-scale robotic data is much more expensive and slower as each operator can control only a single robot at a time. To make this costly data collection process efficient and scalable, we propose Policy Assisted TeleOperation (PATO), a system which automates part of the demonstration collection process using a learned assistive policy. PATO autonomously executes repetitive behaviors in data collection and asks for human input only when it is uncertain about which subtask or behavior to execute. We conduct teleoperation user studies both with a real robot and a simulated robot fleet and demonstrate that our assisted teleoperation system reduces human operators' mental load while improving data collection efficiency. Further, it enables a single operator to control multiple robots in parallel, which is a first step towards scalable robotic data collection. For code and video results, see https://clvrai.com/pato