 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Imitation Learning Algorithms for Bimanual Manipulation
Aug 13, 2024



Amidst the wide popularity of imitation learning algorithms in robotics, their properties regarding hyperparameter sensitivity, ease of training, data efficiency, and performance have not been well-studied in high-precision industry-inspired environments. In this work, we demonstrate the limitations and benefits of prominent imitation learning approaches and analyze their capabilities regarding these properties. We evaluate each algorithm on a complex bimanual manipulation task involving an over-constrained dynamics system in a setting involving multiple contacts between the manipulated object and the environment. While we find that imitation learning is well suited to solve such complex tasks, not all algorithms are equal in terms of handling environmental and hyperparameter perturbations, training requirements, performance, and ease of use. We investigate the empirical influence of these key characteristics by employing a carefully designed experimental procedure and learning environment. Paper website: https://bimanual-imitation.github.io/
GenCHiP: Generating Robot Policy Code for High-Precision and Contact-Rich Manipulation Tasks
Apr 09, 2024



Large Language Models (LLMs) have been successful at generating robot policy code, but so far these results have been limited to high-level tasks that do not require precise movement. It is an open question how well such approaches work for tasks that require reasoning over contact forces and working within tight success tolerances. We find that, with the right action space, LLMs are capable of successfully generating policies for a variety of contact-rich and high-precision manipulation tasks, even under noisy conditions, such as perceptual errors or grasping inaccuracies. Specifically, we reparameterize the action space to include compliance with constraints on the interaction forces and stiffnesses involved in reaching a target pose. We validate this approach on subtasks derived from the Functional Manipulation Benchmark (FMB) and NIST Task Board Benchmarks. Exposing this action space alongside methods for estimating object poses improves policy generation with an LLM by greater than 3x and 4x when compared to non-compliant action spaces
RT-Sketch: Goal-Conditioned Imitation Learning from Hand-Drawn Sketches
Mar 05, 2024



Natural language and images are commonly used as goal representations in goal-conditioned imitation learning (IL). However, natural language can be ambiguous and images can be over-specified. In this work, we propose hand-drawn sketches as a modality for goal specification in visual imitation learning. Sketches are easy for users to provide on the fly like language, but similar to images they can also help a downstream policy to be spatially-aware and even go beyond images to disambiguate task-relevant from task-irrelevant objects. We present RT-Sketch, a goal-conditioned policy for manipulation that takes a hand-drawn sketch of the desired scene as input, and outputs actions. We train RT-Sketch on a dataset of paired trajectories and corresponding synthetically generated goal sketches. We evaluate this approach on six manipulation skills involving tabletop object rearrangements on an articulated countertop. Experimentally we find that RT-Sketch is able to perform on a similar level to image or language-conditioned agents in straightforward settings, while achieving greater robustness when language goals are ambiguous or visual distractors are present. Additionally, we show that RT-Sketch has the capacity to interpret and act upon sketches with varied levels of specificity, ranging from minimal line drawings to detailed, colored drawings. For supplementary material and videos, please refer to our website: http://rt-sketch.github.io.
Efficient Online Learning of Contact Force Models for Connector Insertion
Dec 14, 2023Contact-rich manipulation tasks with stiff frictional elements like connector insertion are difficult to model with rigid-body simulators. In this work, we propose a new approach for modeling these environments by learning a quasi-static contact force model instead of a full simulator. Using a feature vector that contains information about the configuration and control, we find a linear mapping adequately captures the relationship between this feature vector and the sensed contact forces. A novel Linear Model Learning (LML) algorithm is used to solve for the globally optimal mapping in real time without any matrix inversions, resulting in an algorithm that runs in nearly constant time on a GPU as the model size increases. We validate the proposed approach for connector insertion both in simulation and hardware experiments, where the learned model is combined with an optimization-based controller to achieve smooth insertions in the presence of misalignments and uncertainty. Our website featuring videos, code, and more materials is available at https://model-based-plugging.github.io/.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Distributional Depth-Based Estimation of Object Articulation Models
Aug 12, 2021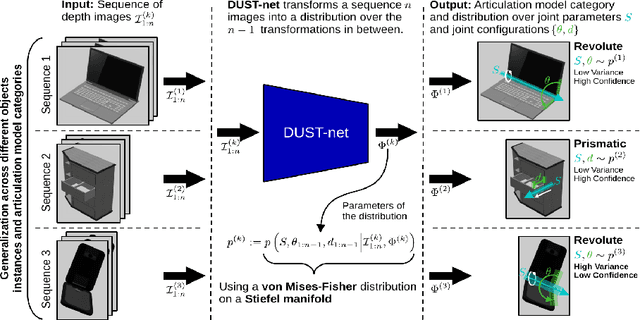

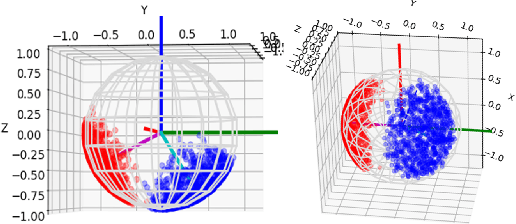
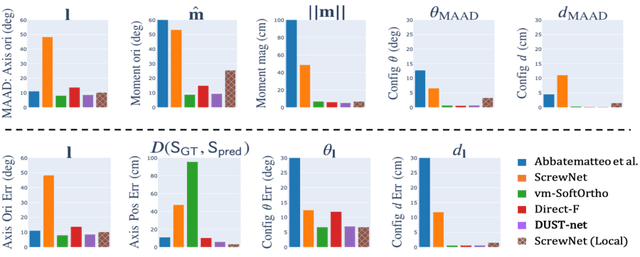
We propose a method that efficiently learns distributions over articulation model parameters directly from depth images without the need to know articulation model categories a priori. By contrast, existing methods that learn articulation models from raw observations typically only predict point estimates of the model parameters, which are insufficient to guarantee the safe manipulation of articulated objects. Our core contributions include a novel representation for distributions over rigid body transformations and articulation model parameters based on screw theory, von Mises-Fisher distributions, and Stiefel manifolds. Combining these concepts allows for an efficient, mathematically sound representation that implicitly satisfies the constraints that rigid body transformations and articulations must adhere to. Leveraging this representation, we introduce a novel deep learning based approach, DUST-net, that performs category-independent articulation model estimation while also providing model uncertainties. We evaluate our approach on several benchmarking datasets and real-world objects and compare its performance with two current state-of-the-art methods. Our results demonstrate that DUST-net can successfully learn distributions over articulation models for novel objects across articulation model categories, which generate point estimates with better accuracy than state-of-the-art methods and effectively capture the uncertainty over predicted model parameters due to noisy inputs.
ScrewNet: Category-Independent Articulation Model Estimation From Depth Images Using Screw Theory
Aug 24, 2020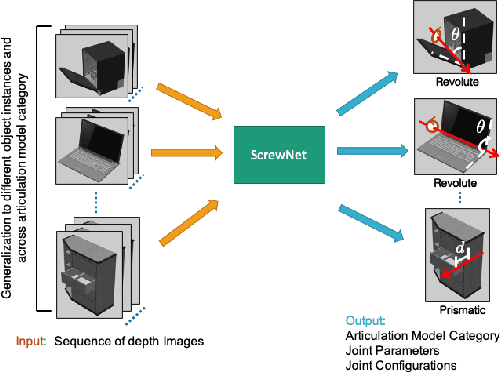
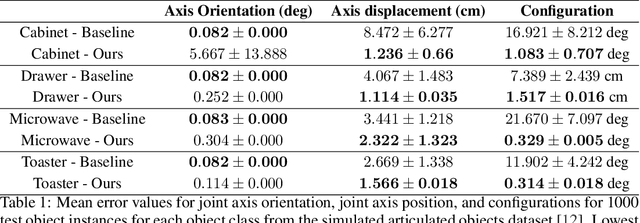
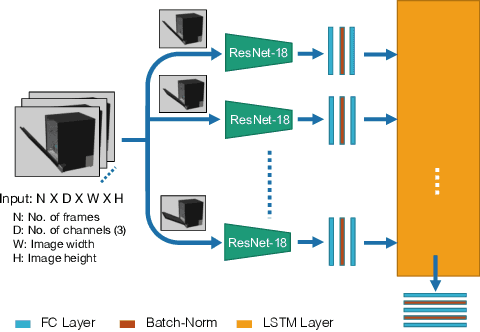
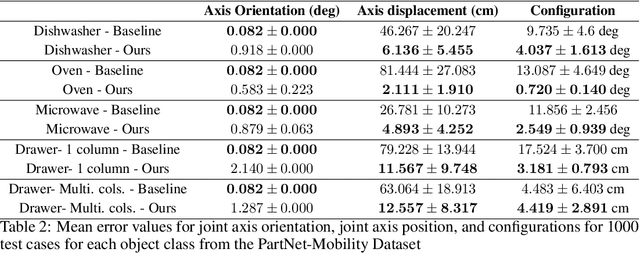
Robots in human environments will need to interact with a wide variety of articulated objects such as cabinets, drawers, and dishwashers while assisting humans in performing day-to-day tasks. Existing methods either require objects to be textured or need to know the articulation model category a priori for estimating the model parameters for an articulated object. We propose ScrewNet, a novel approach that estimates an object's articulation model directly from depth images without requiring a priori knowledge of the articulation model category. ScrewNet uses screw theory to unify the representation of different articulation types and perform category-independent articulation model estimation. We evaluate our approach on two benchmarking datasets and compare its performance with a current state-of-the-art method. Results demonstrate that ScrewNet can successfully estimate the articulation models and their parameters for novel objects across articulation model categories with better on average accuracy than the prior state-of-the-art method.
Learning Hybrid Object Kinematics for Efficient Hierarchical Planning Under Uncertainty
Jul 21, 2019

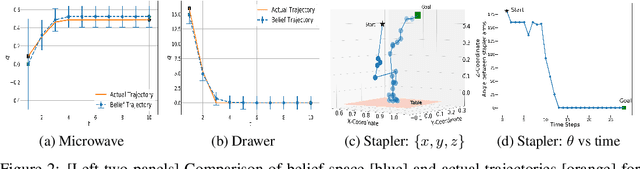
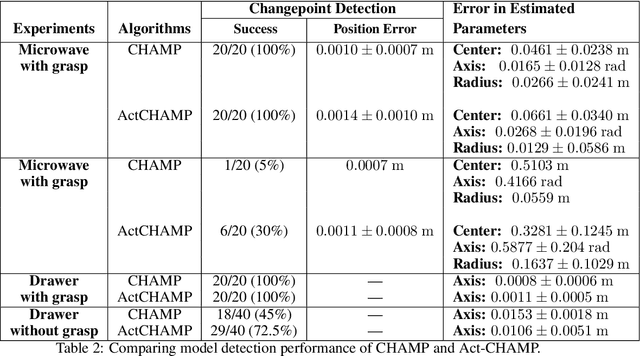
Sudden changes in the dynamics of robotic tasks, such as contact with an object or the latching of a door, are often viewed as inconvenient discontinuities that make manipulation difficult. However, when these transitions are well-understood, they can be leveraged to reduce uncertainty or aid manipulation---for example, wiggling a screw to determine if it is fully inserted or not. Current model-free reinforcement learning approaches require large amounts of data to learn to leverage such dynamics, scale poorly as problem complexity grows, and do not transfer well to significantly different problems. By contrast, hierarchical planning-based methods scale well via plan decomposition and work well on a wide variety of problems, but often rely on precise hand-specified models and task decompositions. To combine the advantages of these opposing paradigms, we propose a new method, Act-CHAMP, which (1) learns hybrid kinematics models of objects from unsegmented data, (2) leverages actions, in addition to states, to outperform a state-of-the-art observation-only inference method, and (3) does so in a manner that is compatible with efficient, hierarchical POMDP planning. Beyond simply coping with challenging dynamics, we show that our end-to-end system leverages the learned kinematics to reduce uncertainty, plan efficiently, and use objects in novel ways not encountered during training.
Efficient Hierarchical Robot Motion Planning Under Uncertainty and Hybrid Dynamics
Oct 08, 2018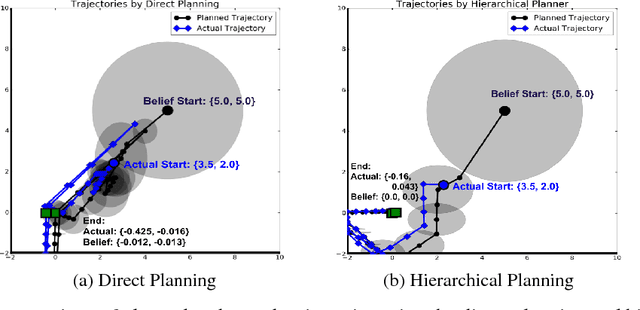

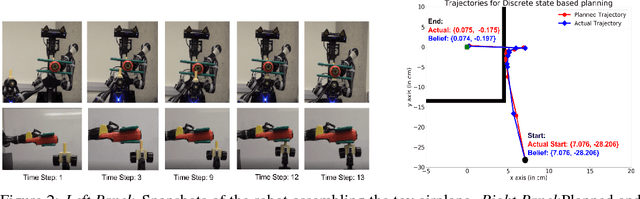
Noisy observations coupled with nonlinear dynamics pose one of the biggest challenges in robot motion planning. By decomposing nonlinear dynamics into a discrete set of local dynamics models, hybrid dynamics provide a natural way to model nonlinear dynamics, especially in systems with sudden discontinuities in dynamics due to factors such as contacts. We propose a hierarchical POMDP planner that develops cost-optimized motion plans for hybrid dynamics models. The hierarchical planner first develops a high-level motion plan to sequence the local dynamics models to be visited and then converts it into a detailed continuous state plan. This hierarchical planning approach results in a decomposition of the POMDP planning problem into smaller sub-parts that can be solved with significantly lower computational costs. The ability to sequence the visitation of local dynamics models also provides a powerful way to leverage the hybrid dynamics to reduce state uncertainty. We evaluate the proposed planner on a navigation task in the simulated domain and on an assembly task with a robotic manipulator, showing that our approach can solve tasks having high observation noise and nonlinear dynamics effectively with significantly lower computational costs compared to direct planning approaches.