 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScrewNet: Category-Independent Articulation Model Estimation From Depth Images Using Screw Theory
Paper and Code
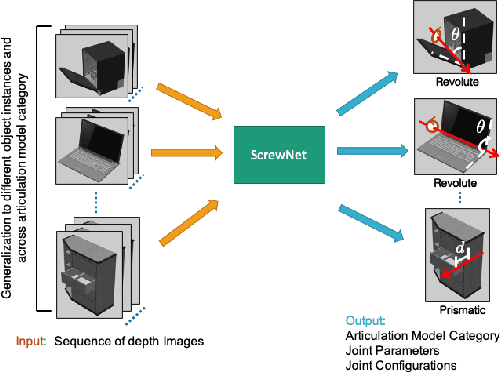
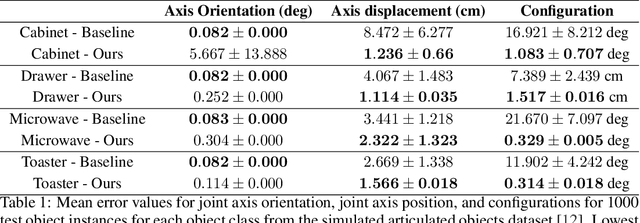
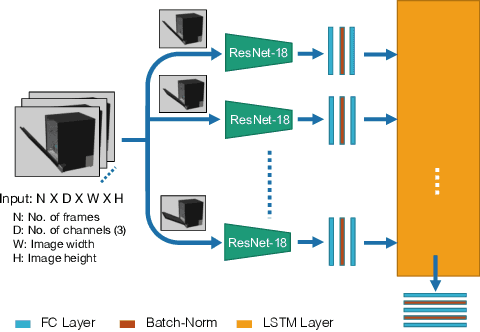
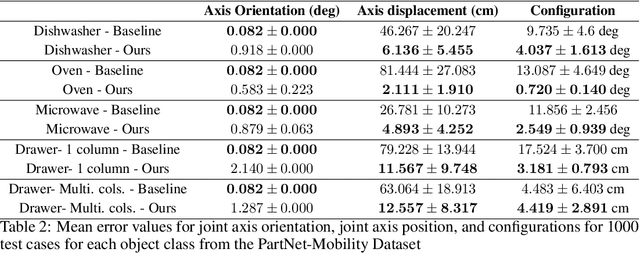
Robots in human environments will need to interact with a wide variety of articulated objects such as cabinets, drawers, and dishwashers while assisting humans in performing day-to-day tasks. Existing methods either require objects to be textured or need to know the articulation model category a priori for estimating the model parameters for an articulated object. We propose ScrewNet, a novel approach that estimates an object's articulation model directly from depth images without requiring a priori knowledge of the articulation model category. ScrewNet uses screw theory to unify the representation of different articulation types and perform category-independent articulation model estimation. We evaluate our approach on two benchmarking datasets and compare its performance with a current state-of-the-art method. Results demonstrate that ScrewNet can successfully estimate the articulation models and their parameters for novel objects across articulation model categories with better on average accuracy than the prior state-of-the-art method.