 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNaviTrace: Evaluating Embodied Navigation of Vision-Language Models
Oct 30, 2025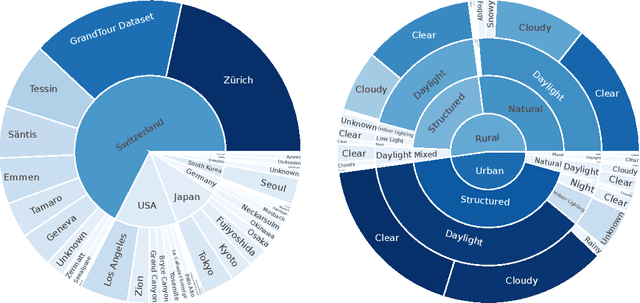
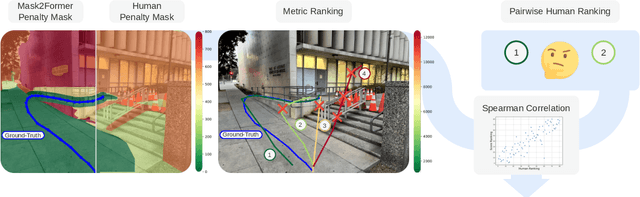
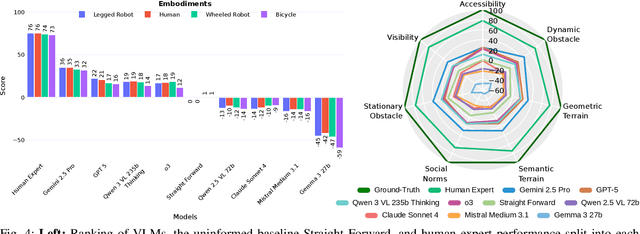
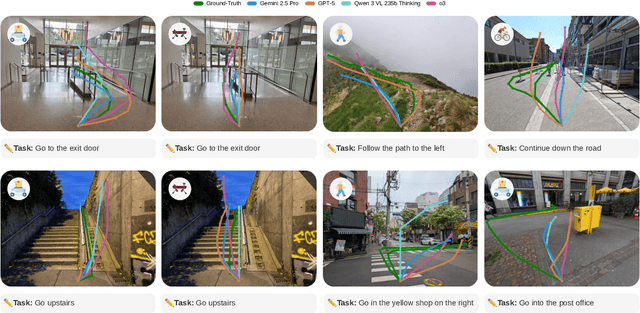
Vision-language models demonstrate unprecedented performance and generalization across a wide range of tasks and scenarios. Integrating these foundation models into robotic navigation systems opens pathways toward building general-purpose robots. Yet, evaluating these models' navigation capabilities remains constrained by costly real-world trials, overly simplified simulations, and limited benchmarks. We introduce NaviTrace, a high-quality Visual Question Answering benchmark where a model receives an instruction and embodiment type (human, legged robot, wheeled robot, bicycle) and must output a 2D navigation trace in image space. Across 1000 scenarios and more than 3000 expert traces, we systematically evaluate eight state-of-the-art VLMs using a newly introduced semantic-aware trace score. This metric combines Dynamic Time Warping distance, goal endpoint error, and embodiment-conditioned penalties derived from per-pixel semantics and correlates with human preferences. Our evaluation reveals consistent gap to human performance caused by poor spatial grounding and goal localization. NaviTrace establishes a scalable and reproducible benchmark for real-world robotic navigation. The benchmark and leaderboard can be found at https://leggedrobotics.github.io/navitrace_webpage/.
PointMapPolicy: Structured Point Cloud Processing for Multi-Modal Imitation Learning
Oct 23, 2025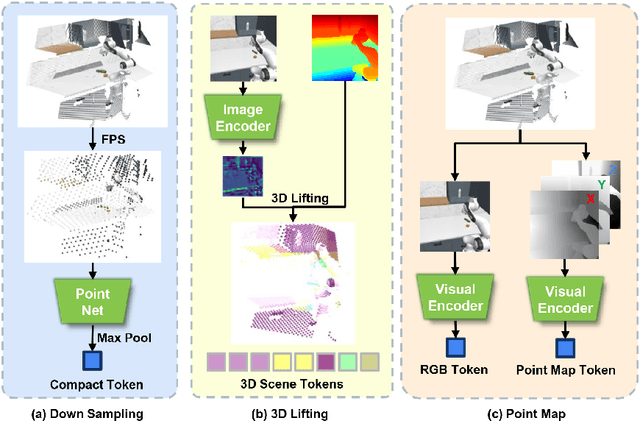
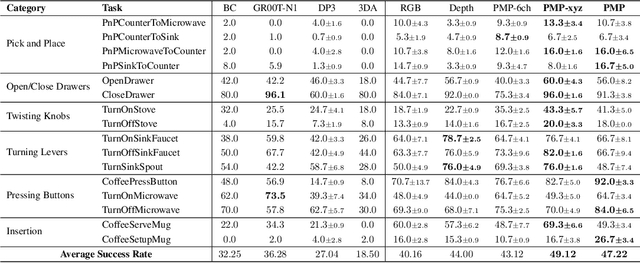
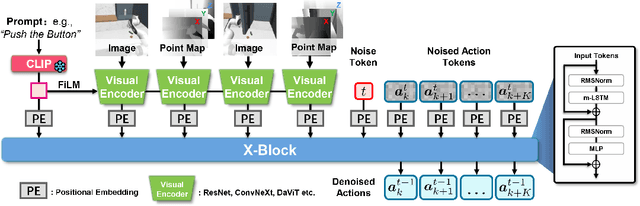
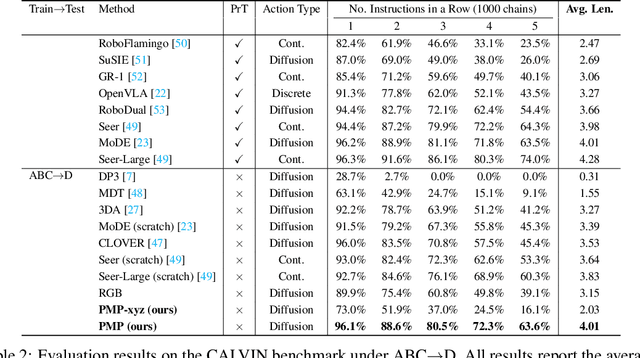
Robotic manipulation systems benefit from complementary sensing modalities, where each provides unique environmental information. Point clouds capture detailed geometric structure, while RGB images provide rich semantic context. Current point cloud methods struggle to capture fine-grained detail, especially for complex tasks, which RGB methods lack geometric awareness, which hinders their precision and generalization. We introduce PointMapPolicy, a novel approach that conditions diffusion policies on structured grids of points without downsampling. The resulting data type makes it easier to extract shape and spatial relationships from observations, and can be transformed between reference frames. Yet due to their structure in a regular grid, we enable the use of established computer vision techniques directly to 3D data. Using xLSTM as a backbone, our model efficiently fuses the point maps with RGB data for enhanced multi-modal perception. Through extensive experiments on the RoboCasa and CALVIN benchmarks and real robot evaluations, we demonstrate that our method achieves state-of-the-art performance across diverse manipulation tasks. The overview and demos are available on our project page: https://point-map.github.io/Point-Map/
FLOWER: Democratizing Generalist Robot Policies with Efficient Vision-Language-Action Flow Policies
Sep 05, 2025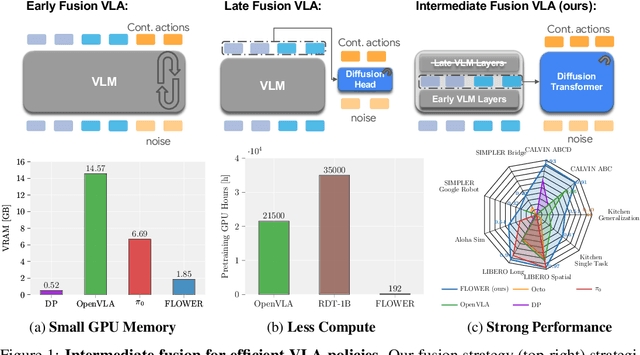

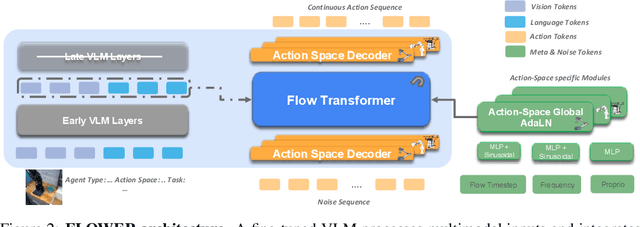
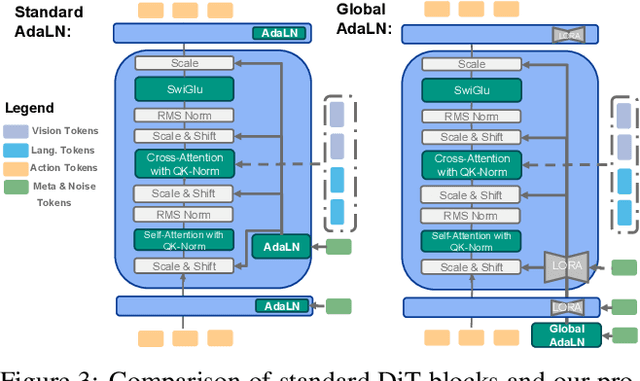
Developing efficient Vision-Language-Action (VLA) policies is crucial for practical robotics deployment, yet current approaches face prohibitive computational costs and resource requirements. Existing diffusion-based VLA policies require multi-billion-parameter models and massive datasets to achieve strong performance. We tackle this efficiency challenge with two contributions: intermediate-modality fusion, which reallocates capacity to the diffusion head by pruning up to $50\%$ of LLM layers, and action-specific Global-AdaLN conditioning, which cuts parameters by $20\%$ through modular adaptation. We integrate these advances into a novel 950 M-parameter VLA called FLOWER. Pretrained in just 200 H100 GPU hours, FLOWER delivers competitive performance with bigger VLAs across $190$ tasks spanning ten simulation and real-world benchmarks and demonstrates robustness across diverse robotic embodiments. In addition, FLOWER achieves a new SoTA of 4.53 on the CALVIN ABC benchmark. Demos, code and pretrained weights are available at https://intuitive-robots.github.io/flower_vla/.
BEAST: Efficient Tokenization of B-Splines Encoded Action Sequences for Imitation Learning
Jun 06, 2025We present the B-spline Encoded Action Sequence Tokenizer (BEAST), a novel action tokenizer that encodes action sequences into compact discrete or continuous tokens using B-splines. In contrast to existing action tokenizers based on vector quantization or byte pair encoding, BEAST requires no separate tokenizer training and consistently produces tokens of uniform length, enabling fast action sequence generation via parallel decoding. Leveraging our B-spline formulation, BEAST inherently ensures generating smooth trajectories without discontinuities between adjacent segments. We extensively evaluate BEAST by integrating it with three distinct model architectures: a Variational Autoencoder (VAE) with continuous tokens, a decoder-only Transformer with discrete tokens, and Florence-2, a pretrained Vision-Language Model with an encoder-decoder architecture, demonstrating BEAST's compatibility and scalability with large pretrained models. We evaluate BEAST across three established benchmarks consisting of 166 simulated tasks and on three distinct robot settings with a total of 8 real-world tasks. Experimental results demonstrate that BEAST (i) significantly reduces both training and inference computational costs, and (ii) consistently generates smooth, high-frequency control signals suitable for continuous control tasks while (iii) reliably achieves competitive task success rates compared to state-of-the-art methods.
Interpretable Affordance Detection on 3D Point Clouds with Probabilistic Prototypes
Apr 25, 2025



Robotic agents need to understand how to interact with objects in their environment, both autonomously and during human-robot interactions. Affordance detection on 3D point clouds, which identifies object regions that allow specific interactions, has traditionally relied on deep learning models like PointNet++, DGCNN, or PointTransformerV3. However, these models operate as black boxes, offering no insight into their decision-making processes. Prototypical Learning methods, such as ProtoPNet, provide an interpretable alternative to black-box models by employing a "this looks like that" case-based reasoning approach. However, they have been primarily applied to image-based tasks. In this work, we apply prototypical learning to models for affordance detection on 3D point clouds. Experiments on the 3D-AffordanceNet benchmark dataset show that prototypical models achieve competitive performance with state-of-the-art black-box models and offer inherent interpretability. This makes prototypical models a promising candidate for human-robot interaction scenarios that require increased trust and safety.
Beyond Visuals: Investigating Force Feedback in Extended Reality for Robot Data Collection
Mar 26, 2025This work explores how force feedback affects various aspects of robot data collection within the Extended Reality (XR) setting. Force feedback has been proved to enhance the user experience in Extended Reality (XR) by providing contact-rich information. However, its impact on robot data collection has not received much attention in the robotics community. This paper addresses this shortcoming by conducting an extensive user study on the effects of force feedback during data collection in XR. We extended two XR-based robot control interfaces, Kinesthetic Teaching and Motion Controllers, with haptic feedback features. The user study is conducted using manipulation tasks ranging from simple pick-place to complex peg assemble, requiring precise operations. The evaluations show that force feedback enhances task performance and user experience, particularly in tasks requiring high-precision manipulation. These improvements vary depending on the robot control interface and task complexity. This paper provides new insights into how different factors influence the impact of force feedback.
Towards Fusing Point Cloud and Visual Representations for Imitation Learning
Feb 19, 2025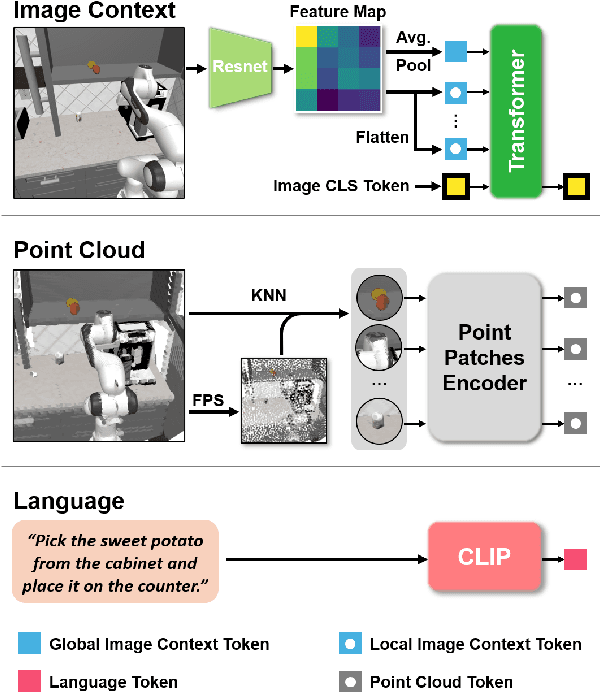
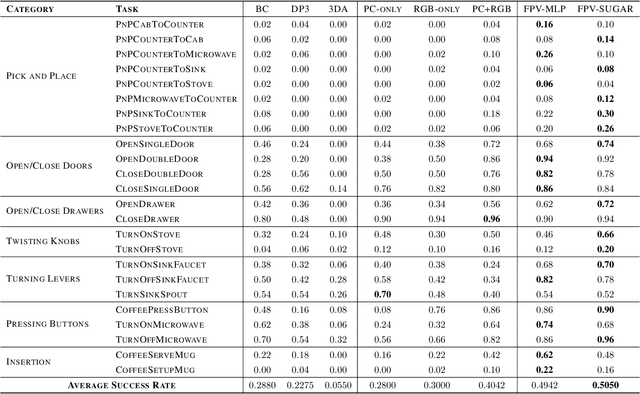
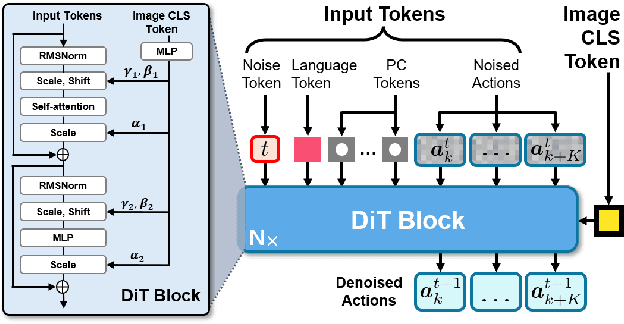
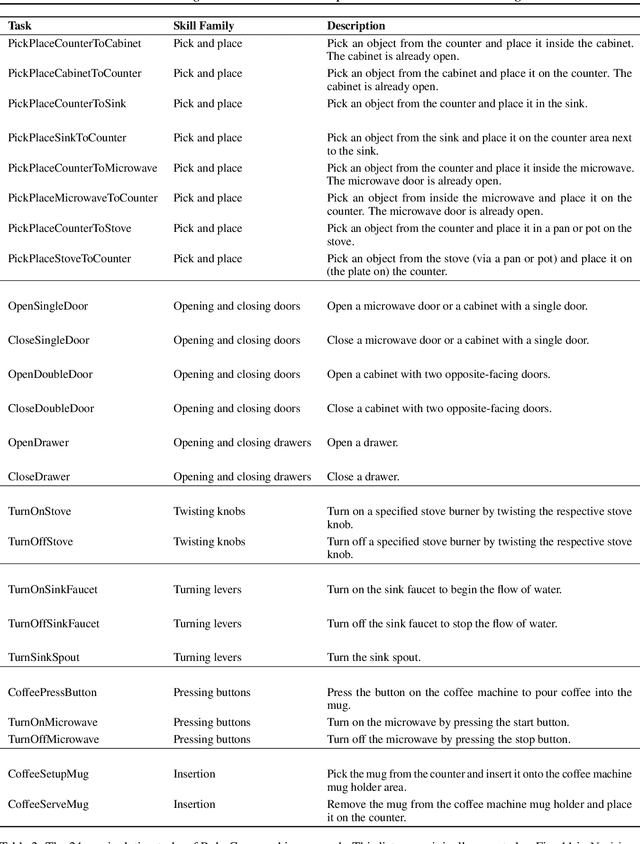
Learning for manipulation requires using policies that have access to rich sensory information such as point clouds or RGB images. Point clouds efficiently capture geometric structures, making them essential for manipulation tasks in imitation learning. In contrast, RGB images provide rich texture and semantic information that can be crucial for certain tasks. Existing approaches for fusing both modalities assign 2D image features to point clouds. However, such approaches often lose global contextual information from the original images. In this work, we propose FPV-Net, a novel imitation learning method that effectively combines the strengths of both point cloud and RGB modalities. Our method conditions the point-cloud encoder on global and local image tokens using adaptive layer norm conditioning, leveraging the beneficial properties of both modalities. Through extensive experiments on the challenging RoboCasa benchmark, we demonstrate the limitations of relying on either modality alone and show that our method achieves state-of-the-art performance across all tasks.
X-IL: Exploring the Design Space of Imitation Learning Policies
Feb 19, 2025Designing modern imitation learning (IL) policies requires making numerous decisions, including the selection of feature encoding, architecture, policy representation, and more. As the field rapidly advances, the range of available options continues to grow, creating a vast and largely unexplored design space for IL policies. In this work, we present X-IL, an accessible open-source framework designed to systematically explore this design space. The framework's modular design enables seamless swapping of policy components, such as backbones (e.g., Transformer, Mamba, xLSTM) and policy optimization techniques (e.g., Score-matching, Flow-matching). This flexibility facilitates comprehensive experimentation and has led to the discovery of novel policy configurations that outperform existing methods on recent robot learning benchmarks. Our experiments demonstrate not only significant performance gains but also provide valuable insights into the strengths and weaknesses of various design choices. This study serves as both a practical reference for practitioners and a foundation for guiding future research in imitation learning.
IRIS: An Immersive Robot Interaction System
Feb 05, 2025



This paper introduces IRIS, an immersive Robot Interaction System leveraging Extended Reality (XR), designed for robot data collection and interaction across multiple simulators, benchmarks, and real-world scenarios. While existing XR-based data collection systems provide efficient and intuitive solutions for large-scale data collection, they are often challenging to reproduce and reuse. This limitation arises because current systems are highly tailored to simulator-specific use cases and environments. IRIS is a novel, easily extendable framework that already supports multiple simulators, benchmarks, and even headsets. Furthermore, IRIS is able to include additional information from real-world sensors, such as point clouds captured through depth cameras. A unified scene specification is generated directly from simulators or real-world sensors and transmitted to XR headsets, creating identical scenes in XR. This specification allows IRIS to support any of the objects, assets, and robots provided by the simulators. In addition, IRIS introduces shared spatial anchors and a robust communication protocol that links simulations between multiple XR headsets. This feature enables multiple XR headsets to share a synchronized scene, facilitating collaborative and multi-user data collection. IRIS can be deployed on any device that supports the Unity Framework, encompassing the vast majority of commercially available headsets. In this work, IRIS was deployed and tested on the Meta Quest 3 and the HoloLens 2. IRIS showcased its versatility across a wide range of real-world and simulated scenarios, using current popular robot simulators such as MuJoCo, IsaacSim, CoppeliaSim, and Genesis. In addition, a user study evaluates IRIS on a data collection task for the LIBERO benchmark. The study shows that IRIS significantly outperforms the baseline in both objective and subjective metrics.
Efficient Diffusion Transformer Policies with Mixture of Expert Denoisers for Multitask Learning
Dec 17, 2024Diffusion Policies have become widely used in Imitation Learning, offering several appealing properties, such as generating multimodal and discontinuous behavior. As models are becoming larger to capture more complex capabilities, their computational demands increase, as shown by recent scaling laws. Therefore, continuing with the current architectures will present a computational roadblock. To address this gap, we propose Mixture-of-Denoising Experts (MoDE) as a novel policy for Imitation Learning. MoDE surpasses current state-of-the-art Transformer-based Diffusion Policies while enabling parameter-efficient scaling through sparse experts and noise-conditioned routing, reducing both active parameters by 40% and inference costs by 90% via expert caching. Our architecture combines this efficient scaling with noise-conditioned self-attention mechanism, enabling more effective denoising across different noise levels. MoDE achieves state-of-the-art performance on 134 tasks in four established imitation learning benchmarks (CALVIN and LIBERO). Notably, by pretraining MoDE on diverse robotics data, we achieve 4.01 on CALVIN ABC and 0.95 on LIBERO-90. It surpasses both CNN-based and Transformer Diffusion Policies by an average of 57% across 4 benchmarks, while using 90% fewer FLOPs and fewer active parameters compared to default Diffusion Transformer architectures. Furthermore, we conduct comprehensive ablations on MoDE's components, providing insights for designing efficient and scalable Transformer architectures for Diffusion Policies. Code and demonstrations are available at https://mbreuss.github.io/MoDE_Diffusion_Policy/.