 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fusing Point Cloud and Visual Representations for Imitation Learning
Paper and Code
Feb 19, 2025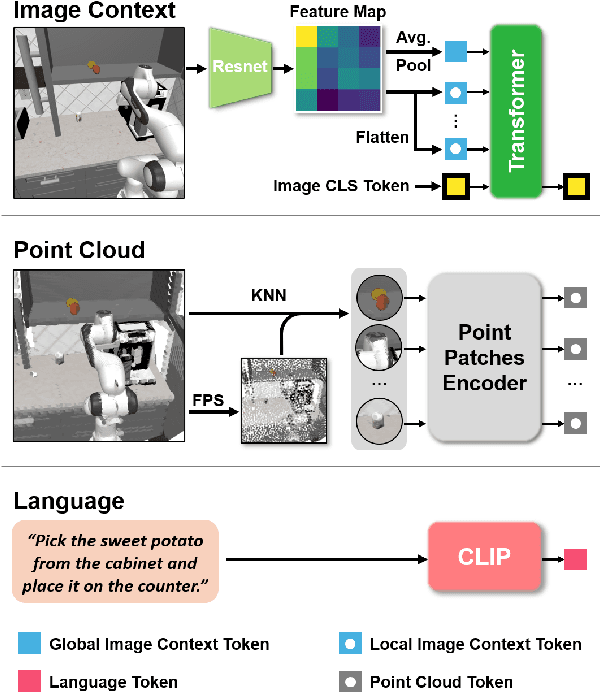
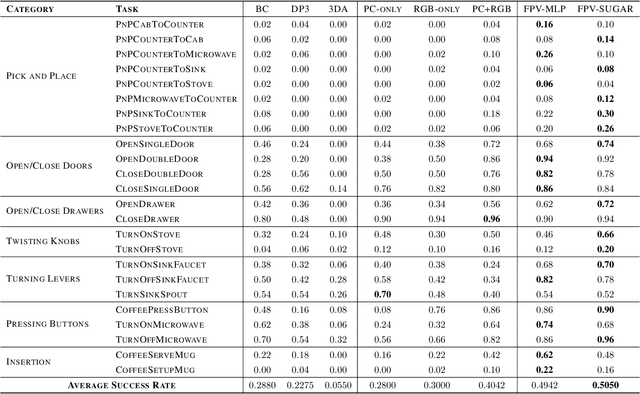
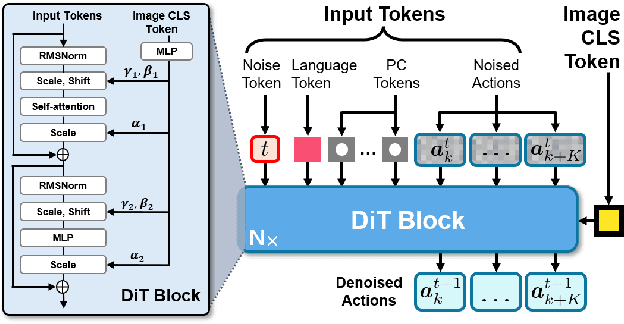
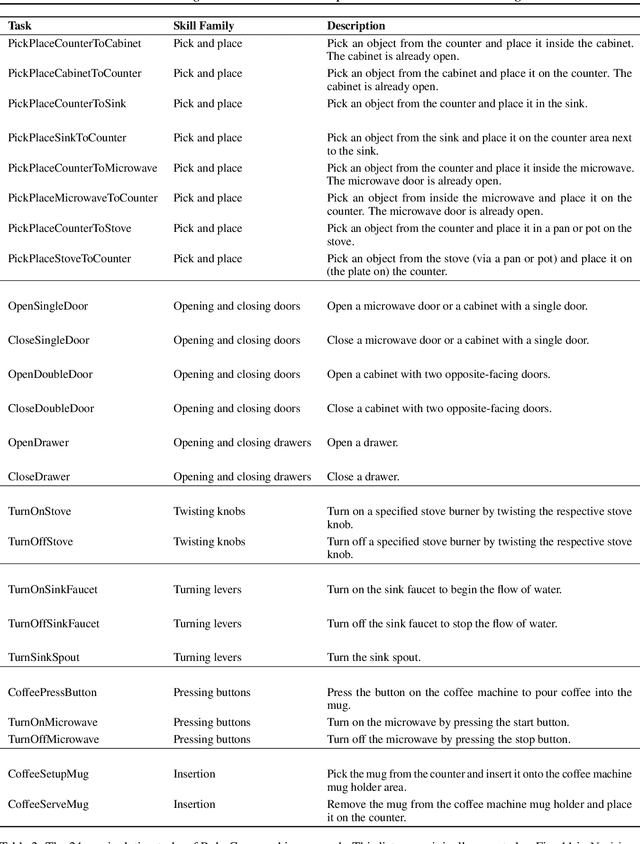
Learning for manipulation requires using policies that have access to rich sensory information such as point clouds or RGB images. Point clouds efficiently capture geometric structures, making them essential for manipulation tasks in imitation learning. In contrast, RGB images provide rich texture and semantic information that can be crucial for certain tasks. Existing approaches for fusing both modalities assign 2D image features to point clouds. However, such approaches often lose global contextual information from the original images. In this work, we propose FPV-Net, a novel imitation learning method that effectively combines the strengths of both point cloud and RGB modalities. Our method conditions the point-cloud encoder on global and local image tokens using adaptive layer norm conditioning, leveraging the beneficial properties of both modalities. Through extensive experiments on the challenging RoboCasa benchmark, we demonstrate the limitations of relying on either modality alone and show that our method achieves state-of-the-art performance across all tasks.