 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaffolding Dexterous Manipulation with Vision-Language Models
Jun 24, 2025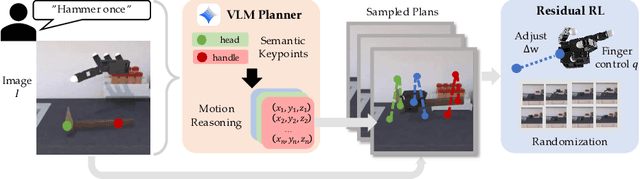
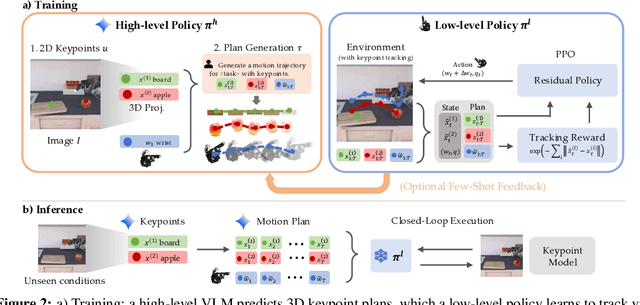
Dexterous robotic hands are essential for performing complex manipulation tasks, yet remain difficult to train due to the challenges of demonstration collection and high-dimensional control. While reinforcement learning (RL) can alleviate the data bottleneck by generating experience in simulation, it typically relies on carefully designed, task-specific reward functions, which hinder scalability and generalization. Thus, contemporary works in dexterous manipulation have often bootstrapped from reference trajectories. These trajectories specify target hand poses that guide the exploration of RL policies and object poses that enable dense, task-agnostic rewards. However, sourcing suitable trajectories - particularly for dexterous hands - remains a significant challenge. Yet, the precise details in explicit reference trajectories are often unnecessary, as RL ultimately refines the motion. Our key insight is that modern vision-language models (VLMs) already encode the commonsense spatial and semantic knowledge needed to specify tasks and guide exploration effectively. Given a task description (e.g., "open the cabinet") and a visual scene, our method uses an off-the-shelf VLM to first identify task-relevant keypoints (e.g., handles, buttons) and then synthesize 3D trajectories for hand motion and object motion. Subsequently, we train a low-level residual RL policy in simulation to track these coarse trajectories or "scaffolds" with high fidelity. Across a number of simulated tasks involving articulated objects and semantic understanding, we demonstrate that our method is able to learn robust dexterous manipulation policies. Moreover, we showcase that our method transfers to real-world robotic hands without any human demonstrations or handcrafted rewards.
AMBER: Adaptive Mesh Generation by Iterative Mesh Resolution Prediction
May 29, 2025The cost and accuracy of simulating complex physical systems using the Finite Element Method (FEM) scales with the resolution of the underlying mesh. Adaptive meshes improve computational efficiency by refining resolution in critical regions, but typically require task-specific heuristics or cumbersome manual design by a human expert. We propose Adaptive Meshing By Expert Reconstruction (AMBER), a supervised learning approach to mesh adaptation. Starting from a coarse mesh, AMBER iteratively predicts the sizing field, i.e., a function mapping from the geometry to the local element size of the target mesh, and uses this prediction to produce a new intermediate mesh using an out-of-the-box mesh generator. This process is enabled through a hierarchical graph neural network, and relies on data augmentation by automatically projecting expert labels onto AMBER-generated data during training. We evaluate AMBER on 2D and 3D datasets, including classical physics problems, mechanical components, and real-world industrial designs with human expert meshes. AMBER generalizes to unseen geometries and consistently outperforms multiple recent baselines, including ones using Graph and Convolutional Neural Networks, and Reinforcement Learning-based approaches.
Towards Fusing Point Cloud and Visual Representations for Imitation Learning
Feb 19, 2025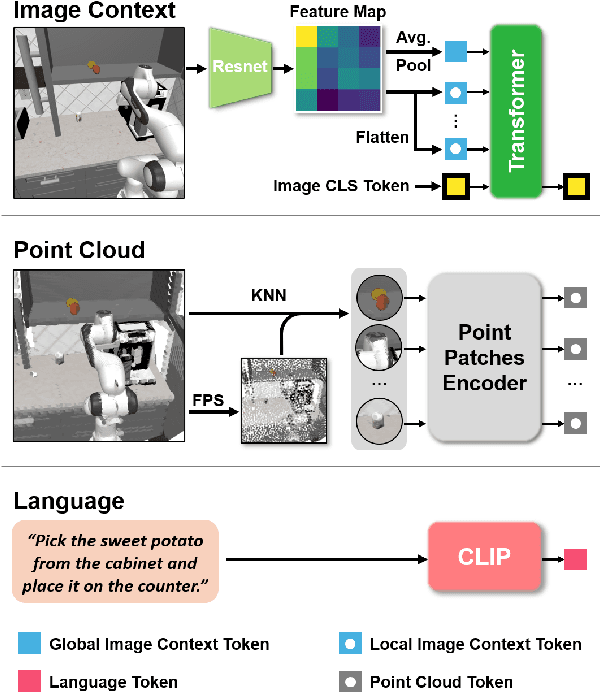
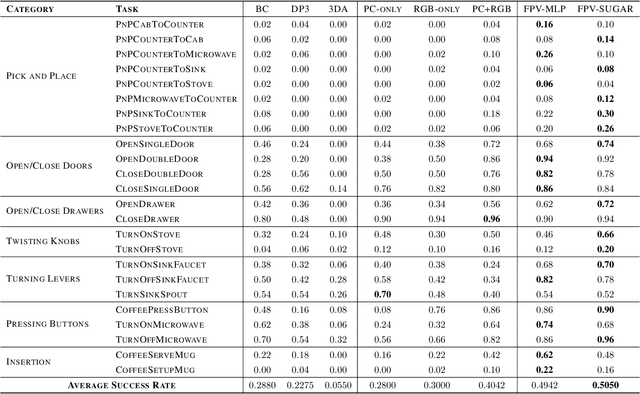
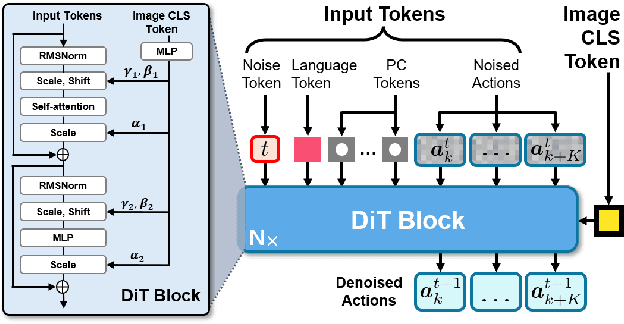
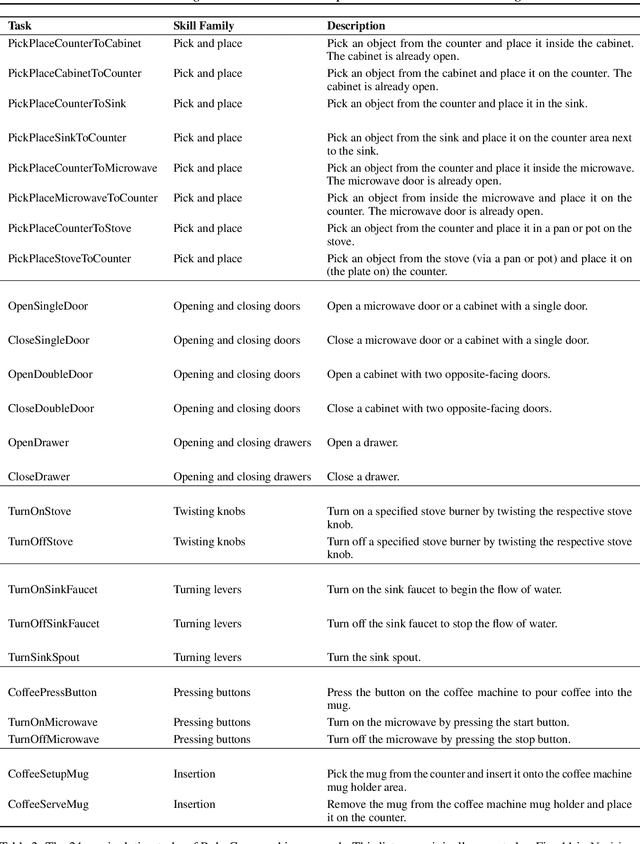
Learning for manipulation requires using policies that have access to rich sensory information such as point clouds or RGB images. Point clouds efficiently capture geometric structures, making them essential for manipulation tasks in imitation learning. In contrast, RGB images provide rich texture and semantic information that can be crucial for certain tasks. Existing approaches for fusing both modalities assign 2D image features to point clouds. However, such approaches often lose global contextual information from the original images. In this work, we propose FPV-Net, a novel imitation learning method that effectively combines the strengths of both point cloud and RGB modalities. Our method conditions the point-cloud encoder on global and local image tokens using adaptive layer norm conditioning, leveraging the beneficial properties of both modalities. Through extensive experiments on the challenging RoboCasa benchmark, we demonstrate the limitations of relying on either modality alone and show that our method achieves state-of-the-art performance across all tasks.
Iterative Sizing Field Prediction for Adaptive Mesh Generation From Expert Demonstrations
Jun 20, 2024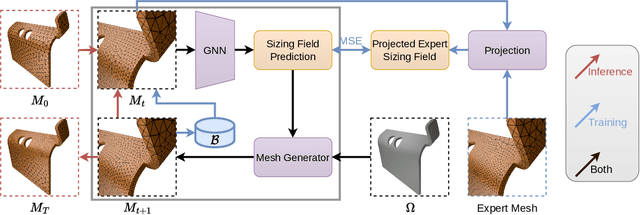
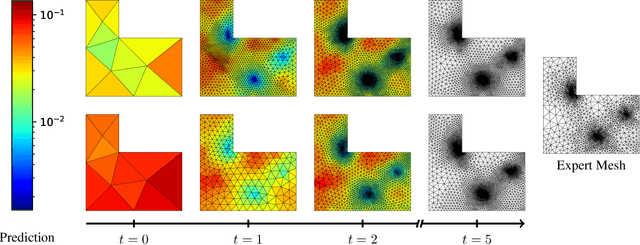
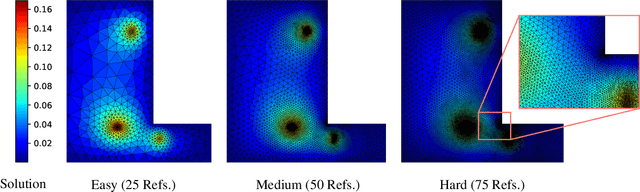
Many engineering systems require accurate simulations of complex physical systems. Yet, analytical solutions are only available for simple problems, necessitating numerical approximations such as the Finite Element Method (FEM). The cost and accuracy of the FEM scale with the resolution of the underlying computational mesh. To balance computational speed and accuracy meshes with adaptive resolution are used, allocating more resources to critical parts of the geometry. Currently, practitioners often resort to hand-crafted meshes, which require extensive expert knowledge and are thus costly to obtain. Our approach, Adaptive Meshing By Expert Reconstruction (AMBER), views mesh generation as an imitation learning problem. AMBER combines a graph neural network with an online data acquisition scheme to predict the projected sizing field of an expert mesh on a given intermediate mesh, creating a more accurate subsequent mesh. This iterative process ensures efficient and accurate imitation of expert mesh resolutions on arbitrary new geometries during inference. We experimentally validate AMBER on heuristic 2D meshes and 3D meshes provided by a human expert, closely matching the provided demonstrations and outperforming a single-step CNN baseline.
Acquiring Diverse Skills using Curriculum Reinforcement Learning with Mixture of Experts
Mar 11, 2024



Reinforcement learning (RL) is a powerful approach for acquiring a good-performing policy. However, learning diverse skills is challenging in RL due to the commonly used Gaussian policy parameterization. We propose \textbf{Di}verse \textbf{Skil}l \textbf{L}earning (Di-SkilL), an RL method for learning diverse skills using Mixture of Experts, where each expert formalizes a skill as a contextual motion primitive. Di-SkilL optimizes each expert and its associate context distribution to a maximum entropy objective that incentivizes learning diverse skills in similar contexts. The per-expert context distribution enables automatic curricula learning, allowing each expert to focus on its best-performing sub-region of the context space. To overcome hard discontinuities and multi-modalities without any prior knowledge of the environment's unknown context probability space, we leverage energy-based models to represent the per-expert context distributions and demonstrate how we can efficiently train them using the standard policy gradient objective. We show on challenging robot simulation tasks that Di-SkilL can learn diverse and performant skills.
Domain-Specific Fine-Tuning of Large Language Models for Interactive Robot Programming
Dec 21, 2023
Industrial robots are applied in a widening range of industries, but robot programming mostly remains a task limited to programming experts. We propose a natural language-based assistant for programming of advanced, industrial robotic applications and investigate strategies for domain-specific fine-tuning of foundation models with limited data and compute.