 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaffolding Dexterous Manipulation with Vision-Language Models
Jun 24, 2025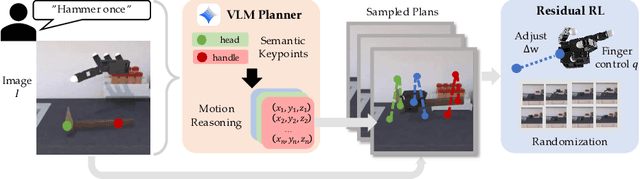
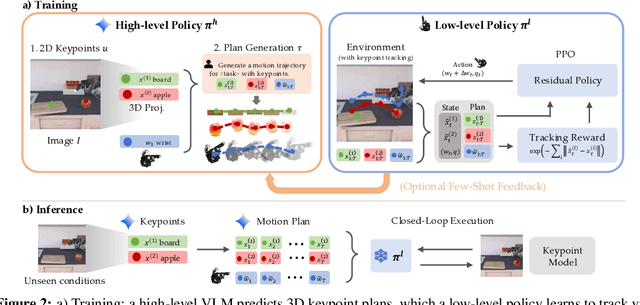
Dexterous robotic hands are essential for performing complex manipulation tasks, yet remain difficult to train due to the challenges of demonstration collection and high-dimensional control. While reinforcement learning (RL) can alleviate the data bottleneck by generating experience in simulation, it typically relies on carefully designed, task-specific reward functions, which hinder scalability and generalization. Thus, contemporary works in dexterous manipulation have often bootstrapped from reference trajectories. These trajectories specify target hand poses that guide the exploration of RL policies and object poses that enable dense, task-agnostic rewards. However, sourcing suitable trajectories - particularly for dexterous hands - remains a significant challenge. Yet, the precise details in explicit reference trajectories are often unnecessary, as RL ultimately refines the motion. Our key insight is that modern vision-language models (VLMs) already encode the commonsense spatial and semantic knowledge needed to specify tasks and guide exploration effectively. Given a task description (e.g., "open the cabinet") and a visual scene, our method uses an off-the-shelf VLM to first identify task-relevant keypoints (e.g., handles, buttons) and then synthesize 3D trajectories for hand motion and object motion. Subsequently, we train a low-level residual RL policy in simulation to track these coarse trajectories or "scaffolds" with high fidelity. Across a number of simulated tasks involving articulated objects and semantic understanding, we demonstrate that our method is able to learn robust dexterous manipulation policies. Moreover, we showcase that our method transfers to real-world robotic hands without any human demonstrations or handcrafted rewards.
Crossing the Human-Robot Embodiment Gap with Sim-to-Real RL using One Human Demonstration
Apr 17, 2025



Teaching robots dexterous manipulation skills often requires collecting hundreds of demonstrations using wearables or teleoperation, a process that is challenging to scale. Videos of human-object interactions are easier to collect and scale, but leveraging them directly for robot learning is difficult due to the lack of explicit action labels from videos and morphological differences between robot and human hands. We propose Human2Sim2Robot, a novel real-to-sim-to-real framework for training dexterous manipulation policies using only one RGB-D video of a human demonstrating a task. Our method utilizes reinforcement learning (RL) in simulation to cross the human-robot embodiment gap without relying on wearables, teleoperation, or large-scale data collection typically necessary for imitation learning methods. From the demonstration, we extract two task-specific components: (1) the object pose trajectory to define an object-centric, embodiment-agnostic reward function, and (2) the pre-manipulation hand pose to initialize and guide exploration during RL training. We found that these two components are highly effective for learning the desired task, eliminating the need for task-specific reward shaping and tuning. We demonstrate that Human2Sim2Robot outperforms object-aware open-loop trajectory replay by 55% and imitation learning with data augmentation by 68% across grasping, non-prehensile manipulation, and multi-step tasks. Project Site: https://human2sim2robot.github.io
Get a Grip: Multi-Finger Grasp Evaluation at Scale Enables Robust Sim-to-Real Transfer
Oct 31, 2024This work explores conditions under which multi-finger grasping algorithms can attain robust sim-to-real transfer. While numerous large datasets facilitate learning generative models for multi-finger grasping at scale, reliable real-world dexterous grasping remains challenging, with most methods degrading when deployed on hardware. An alternate strategy is to use discriminative grasp evaluation models for grasp selection and refinement, conditioned on real-world sensor measurements. This paradigm has produced state-of-the-art results for vision-based parallel-jaw grasping, but remains unproven in the multi-finger setting. In this work, we find that existing datasets and methods have been insufficient for training discriminitive models for multi-finger grasping. To train grasp evaluators at scale, datasets must provide on the order of millions of grasps, including both positive and negative examples, with corresponding visual data resembling measurements at inference time. To that end, we release a new, open-source dataset of 3.5M grasps on 4.3K objects annotated with RGB images, point clouds, and trained NeRFs. Leveraging this dataset, we train vision-based grasp evaluators that outperform both analytic and generative modeling-based baselines on extensive simulated and real-world trials across a diverse range of objects. We show via numerous ablations that the key factor for performance is indeed the evaluator, and that its quality degrades as the dataset shrinks, demonstrating the importance of our new dataset. Project website at: https://sites.google.com/view/get-a-grip-dataset.
Neural Attention Field: Emerging Point Relevance in 3D Scenes for One-Shot Dexterous Grasping
Oct 30, 2024



One-shot transfer of dexterous grasps to novel scenes with object and context variations has been a challenging problem. While distilled feature fields from large vision models have enabled semantic correspondences across 3D scenes, their features are point-based and restricted to object surfaces, limiting their capability of modeling complex semantic feature distributions for hand-object interactions. In this work, we propose the \textit{neural attention field} for representing semantic-aware dense feature fields in the 3D space by modeling inter-point relevance instead of individual point features. Core to it is a transformer decoder that computes the cross-attention between any 3D query point with all the scene points, and provides the query point feature with an attention-based aggregation. We further propose a self-supervised framework for training the transformer decoder from only a few 3D pointclouds without hand demonstrations. Post-training, the attention field can be applied to novel scenes for semantics-aware dexterous grasping from one-shot demonstration. Experiments show that our method provides better optimization landscapes by encouraging the end-effector to focus on task-relevant scene regions, resulting in significant improvements in success rates on real robots compared with the feature-field-based methods.
DextrAH-G: Pixels-to-Action Dexterous Arm-Hand Grasping with Geometric Fabrics
Jul 02, 2024

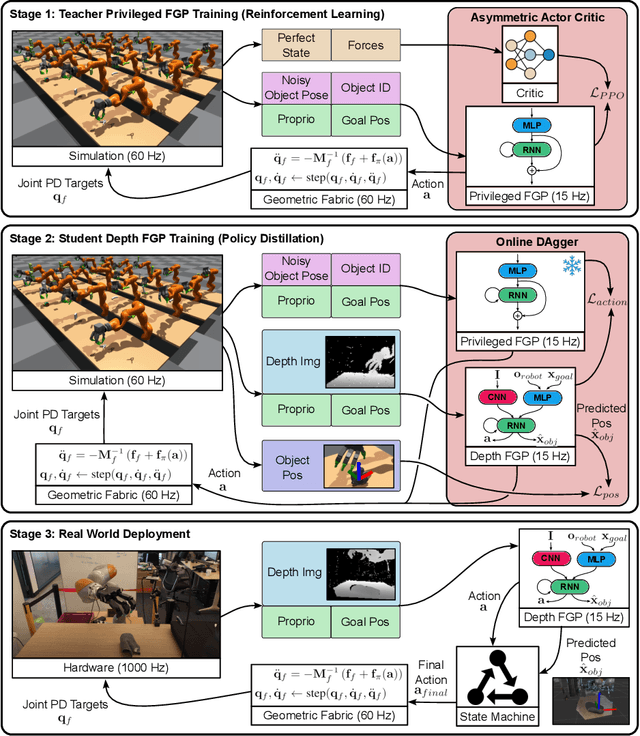
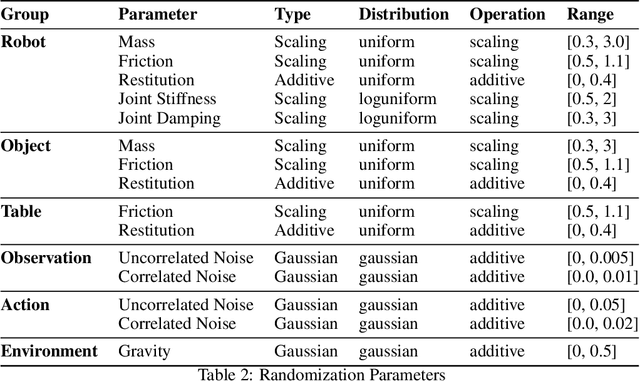
A pivotal challenge in robotics is achieving fast, safe, and robust dexterous grasping across a diverse range of objects, an important goal within industrial applications. However, existing methods often have very limited speed, dexterity, and generality, along with limited or no hardware safety guarantees. In this work, we introduce DextrAH-G, a depth-based dexterous grasping policy trained entirely in simulation that combines reinforcement learning, geometric fabrics, and teacher-student distillation. We address key challenges in joint arm-hand policy learning, such as high-dimensional observation and action spaces, the sim2real gap, collision avoidance, and hardware constraints. DextrAH-G enables a 23 motor arm-hand robot to safely and continuously grasp and transport a large variety of objects at high speed using multi-modal inputs including depth images, allowing generalization across object geometry. Videos at https://sites.google.com/view/dextrah-g.