 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocomotion Beyond Feet
Jan 07, 2026Most locomotion methods for humanoid robots focus on leg-based gaits, yet natural bipeds frequently rely on hands, knees, and elbows to establish additional contacts for stability and support in complex environments. This paper introduces Locomotion Beyond Feet, a comprehensive system for whole-body humanoid locomotion across extremely challenging terrains, including low-clearance spaces under chairs, knee-high walls, knee-high platforms, and steep ascending and descending stairs. Our approach addresses two key challenges: contact-rich motion planning and generalization across diverse terrains. To this end, we combine physics-grounded keyframe animation with reinforcement learning. Keyframes encode human knowledge of motor skills, are embodiment-specific, and can be readily validated in simulation or on hardware, while reinforcement learning transforms these references into robust, physically accurate motions. We further employ a hierarchical framework consisting of terrain-specific motion-tracking policies, failure recovery mechanisms, and a vision-based skill planner. Real-world experiments demonstrate that Locomotion Beyond Feet achieves robust whole-body locomotion and generalizes across obstacle sizes, obstacle instances, and terrain sequences.
CHIP: Adaptive Compliance for Humanoid Control through Hindsight Perturbation
Dec 16, 2025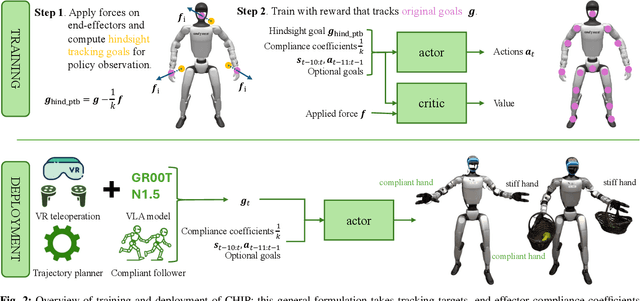
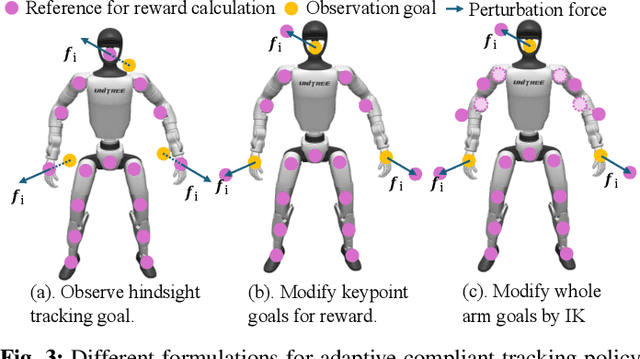
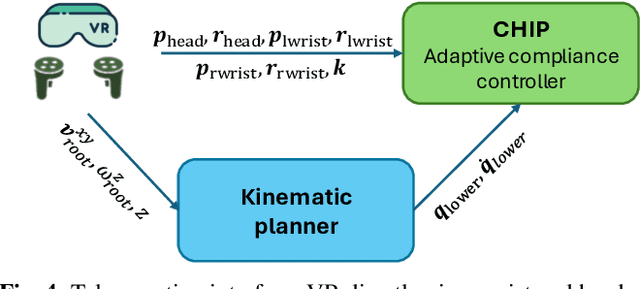

Recent progress in humanoid robots has unlocked agile locomotion skills, including backflipping, running, and crawling. Yet it remains challenging for a humanoid robot to perform forceful manipulation tasks such as moving objects, wiping, and pushing a cart. We propose adaptive Compliance Humanoid control through hIsight Perturbation (CHIP), a plug-and-play module that enables controllable end-effector stiffness while preserving agile tracking of dynamic reference motions. CHIP is easy to implement and requires neither data augmentation nor additional reward tuning. We show that a generalist motion-tracking controller trained with CHIP can perform a diverse set of forceful manipulation tasks that require different end-effector compliance, such as multi-robot collaboration, wiping, box delivery, and door opening.
GentleHumanoid: Learning Upper-body Compliance for Contact-rich Human and Object Interaction
Nov 06, 2025Humanoid robots are expected to operate in human-centered environments where safe and natural physical interaction is essential. However, most recent reinforcement learning (RL) policies emphasize rigid tracking and suppress external forces. Existing impedance-augmented approaches are typically restricted to base or end-effector control and focus on resisting extreme forces rather than enabling compliance. We introduce GentleHumanoid, a framework that integrates impedance control into a whole-body motion tracking policy to achieve upper-body compliance. At its core is a unified spring-based formulation that models both resistive contacts (restoring forces when pressing against surfaces) and guiding contacts (pushes or pulls sampled from human motion data). This formulation ensures kinematically consistent forces across the shoulder, elbow, and wrist, while exposing the policy to diverse interaction scenarios. Safety is further supported through task-adjustable force thresholds. We evaluate our approach in both simulation and on the Unitree G1 humanoid across tasks requiring different levels of compliance, including gentle hugging, sit-to-stand assistance, and safe object manipulation. Compared to baselines, our policy consistently reduces peak contact forces while maintaining task success, resulting in smoother and more natural interactions. These results highlight a step toward humanoid robots that can safely and effectively collaborate with humans and handle objects in real-world environments.
ResMimic: From General Motion Tracking to Humanoid Whole-body Loco-Manipulation via Residual Learning
Oct 06, 2025Humanoid whole-body loco-manipulation promises transformative capabilities for daily service and warehouse tasks. While recent advances in general motion tracking (GMT) have enabled humanoids to reproduce diverse human motions, these policies lack the precision and object awareness required for loco-manipulation. To this end, we introduce ResMimic, a two-stage residual learning framework for precise and expressive humanoid control from human motion data. First, a GMT policy, trained on large-scale human-only motion, serves as a task-agnostic base for generating human-like whole-body movements. An efficient but precise residual policy is then learned to refine the GMT outputs to improve locomotion and incorporate object interaction. To further facilitate efficient training, we design (i) a point-cloud-based object tracking reward for smoother optimization, (ii) a contact reward that encourages accurate humanoid body-object interactions, and (iii) a curriculum-based virtual object controller to stabilize early training. We evaluate ResMimic in both simulation and on a real Unitree G1 humanoid. Results show substantial gains in task success, training efficiency, and robustness over strong baselines. Videos are available at https://resmimic.github.io/ .
Retargeting Matters: General Motion Retargeting for Humanoid Motion Tracking
Oct 02, 2025Humanoid motion tracking policies are central to building teleoperation pipelines and hierarchical controllers, yet they face a fundamental challenge: the embodiment gap between humans and humanoid robots. Current approaches address this gap by retargeting human motion data to humanoid embodiments and then training reinforcement learning (RL) policies to imitate these reference trajectories. However, artifacts introduced during retargeting, such as foot sliding, self-penetration, and physically infeasible motion are often left in the reference trajectories for the RL policy to correct. While prior work has demonstrated motion tracking abilities, they often require extensive reward engineering and domain randomization to succeed. In this paper, we systematically evaluate how retargeting quality affects policy performance when excessive reward tuning is suppressed. To address issues that we identify with existing retargeting methods, we propose a new retargeting method, General Motion Retargeting (GMR). We evaluate GMR alongside two open-source retargeters, PHC and ProtoMotions, as well as with a high-quality closed-source dataset from Unitree. Using BeyondMimic for policy training, we isolate retargeting effects without reward tuning. Our experiments on a diverse subset of the LAFAN1 dataset reveal that while most motions can be tracked, artifacts in retargeted data significantly reduce policy robustness, particularly for dynamic or long sequences. GMR consistently outperforms existing open-source methods in both tracking performance and faithfulness to the source motion, achieving perceptual fidelity and policy success rates close to the closed-source baseline. Website: https://jaraujo98.github.io/retargeting_matters. Code: https://github.com/YanjieZe/GMR.
OmniRetarget: Interaction-Preserving Data Generation for Humanoid Whole-Body Loco-Manipulation and Scene Interaction
Sep 30, 2025A dominant paradigm for teaching humanoid robots complex skills is to retarget human motions as kinematic references to train reinforcement learning (RL) policies. However, existing retargeting pipelines often struggle with the significant embodiment gap between humans and robots, producing physically implausible artifacts like foot-skating and penetration. More importantly, common retargeting methods neglect the rich human-object and human-environment interactions essential for expressive locomotion and loco-manipulation. To address this, we introduce OmniRetarget, an interaction-preserving data generation engine based on an interaction mesh that explicitly models and preserves the crucial spatial and contact relationships between an agent, the terrain, and manipulated objects. By minimizing the Laplacian deformation between the human and robot meshes while enforcing kinematic constraints, OmniRetarget generates kinematically feasible trajectories. Moreover, preserving task-relevant interactions enables efficient data augmentation, from a single demonstration to different robot embodiments, terrains, and object configurations. We comprehensively evaluate OmniRetarget by retargeting motions from OMOMO, LAFAN1, and our in-house MoCap datasets, generating over 8-hour trajectories that achieve better kinematic constraint satisfaction and contact preservation than widely used baselines. Such high-quality data enables proprioceptive RL policies to successfully execute long-horizon (up to 30 seconds) parkour and loco-manipulation skills on a Unitree G1 humanoid, trained with only 5 reward terms and simple domain randomization shared by all tasks, without any learning curriculum.
Learning to Ball: Composing Policies for Long-Horizon Basketball Moves
Sep 26, 2025

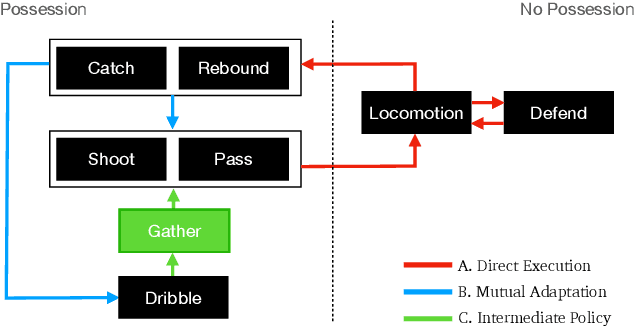

Learning a control policy for a multi-phase, long-horizon task, such as basketball maneuvers, remains challenging for reinforcement learning approaches due to the need for seamless policy composition and transitions between skills. A long-horizon task typically consists of distinct subtasks with well-defined goals, separated by transitional subtasks with unclear goals but critical to the success of the entire task. Existing methods like the mixture of experts and skill chaining struggle with tasks where individual policies do not share significant commonly explored states or lack well-defined initial and terminal states between different phases. In this paper, we introduce a novel policy integration framework to enable the composition of drastically different motor skills in multi-phase long-horizon tasks with ill-defined intermediate states. Based on that, we further introduce a high-level soft router to enable seamless and robust transitions between the subtasks. We evaluate our framework on a set of fundamental basketball skills and challenging transitions. Policies trained by our approach can effectively control the simulated character to interact with the ball and accomplish the long-horizon task specified by real-time user commands, without relying on ball trajectory references.
* ACM Transactions on Graphics (Proceedings of SIGGRAPH Asia 2025). Website: http://pei-xu.github.io/basketball. Video: https://youtu.be/2RBFIjjmR2I. Code: https://github.com/xupei0610/basketball
LookOut: Real-World Humanoid Egocentric Navigation
Aug 20, 2025The ability to predict collision-free future trajectories from egocentric observations is crucial in applications such as humanoid robotics, VR / AR, and assistive navigation. In this work, we introduce the challenging problem of predicting a sequence of future 6D head poses from an egocentric video. In particular, we predict both head translations and rotations to learn the active information-gathering behavior expressed through head-turning events. To solve this task, we propose a framework that reasons over temporally aggregated 3D latent features, which models the geometric and semantic constraints for both the static and dynamic parts of the environment. Motivated by the lack of training data in this space, we further contribute a data collection pipeline using the Project Aria glasses, and present a dataset collected through this approach. Our dataset, dubbed Aria Navigation Dataset (AND), consists of 4 hours of recording of users navigating in real-world scenarios. It includes diverse situations and navigation behaviors, providing a valuable resource for learning real-world egocentric navigation policies. Extensive experiments show that our model learns human-like navigation behaviors such as waiting / slowing down, rerouting, and looking around for traffic while generalizing to unseen environments. Check out our project webpage at https://sites.google.com/stanford.edu/lookout.
Robot Trains Robot: Automatic Real-World Policy Adaptation and Learning for Humanoids
Aug 17, 2025Simulation-based reinforcement learning (RL) has significantly advanced humanoid locomotion tasks, yet direct real-world RL from scratch or adapting from pretrained policies remains rare, limiting the full potential of humanoid robots. Real-world learning, despite being crucial for overcoming the sim-to-real gap, faces substantial challenges related to safety, reward design, and learning efficiency. To address these limitations, we propose Robot-Trains-Robot (RTR), a novel framework where a robotic arm teacher actively supports and guides a humanoid robot student. The RTR system provides protection, learning schedule, reward, perturbation, failure detection, and automatic resets. It enables efficient long-term real-world humanoid training with minimal human intervention. Furthermore, we propose a novel RL pipeline that facilitates and stabilizes sim-to-real transfer by optimizing a single dynamics-encoded latent variable in the real world. We validate our method through two challenging real-world humanoid tasks: fine-tuning a walking policy for precise speed tracking and learning a humanoid swing-up task from scratch, illustrating the promising capabilities of real-world humanoid learning realized by RTR-style systems. See https://robot-trains-robot.github.io/ for more info.
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Aug 13, 2025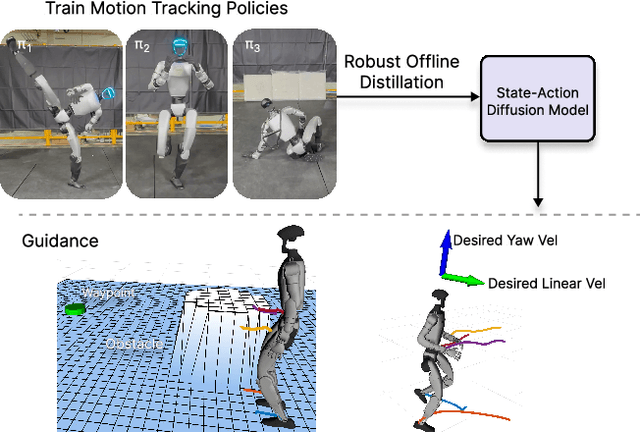



Learning skills from human motions offers a promising path toward generalizable policies for versatile humanoid whole-body control, yet two key cornerstones are missing: (1) a high-quality motion tracking framework that faithfully transforms large-scale kinematic references into robust and extremely dynamic motions on real hardware, and (2) a distillation approach that can effectively learn these motion primitives and compose them to solve downstream tasks. We address these gaps with BeyondMimic, a real-world framework to learn from human motions for versatile and naturalistic humanoid control via guided diffusion. Our framework provides a motion tracking pipeline capable of challenging skills such as jumping spins, sprinting, and cartwheels with state-of-the-art motion quality. Moving beyond simply mimicking existing motions, we further introduce a unified diffusion policy that enables zero-shot task-specific control at test time using simple cost functions. Deployed on hardware, BeyondMimic performs diverse tasks at test time, including waypoint navigation, joystick teleoperation, and obstacle avoidance, bridging sim-to-real motion tracking and flexible synthesis of human motion primitives for whole-body control. https://beyondmimic.github.io/.