 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeCraft: Body-Aware and Semantics-Aware 3D Object Design
Dec 05, 2024



For designing a wide range of everyday objects, the design process should be aware of both the human body and the underlying semantics of the design specification. However, these two objectives present significant challenges to the current AI-based designing tools. In this work, we present a method to synthesize body-aware 3D objects from a base mesh given an input body geometry and either text or image as guidance. The generated objects can be simulated on virtual characters, or fabricated for real-world use. We propose to use a mesh deformation procedure that optimizes for both semantic alignment as well as contact and penetration losses. Using our method, users can generate both virtual or real-world objects from text, image, or sketch, without the need for manual artist intervention. We present both qualitative and quantitative results on various object categories, demonstrating the effectiveness of our approach.
Learning to Design and Use Tools for Robotic Manipulation
Nov 01, 2023



When limited by their own morphologies, humans and some species of animals have the remarkable ability to use objects from the environment toward accomplishing otherwise impossible tasks. Robots might similarly unlock a range of additional capabilities through tool use. Recent techniques for jointly optimizing morphology and control via deep learning are effective at designing locomotion agents. But while outputting a single morphology makes sense for locomotion, manipulation involves a variety of strategies depending on the task goals at hand. A manipulation agent must be capable of rapidly prototyping specialized tools for different goals. Therefore, we propose learning a designer policy, rather than a single design. A designer policy is conditioned on task information and outputs a tool design that helps solve the task. A design-conditioned controller policy can then perform manipulation using these tools. In this work, we take a step towards this goal by introducing a reinforcement learning framework for jointly learning these policies. Through simulated manipulation tasks, we show that this framework is more sample efficient than prior methods in multi-goal or multi-variant settings, can perform zero-shot interpolation or fine-tuning to tackle previously unseen goals, and allows tradeoffs between the complexity of design and control policies under practical constraints. Finally, we deploy our learned policies onto a real robot. Please see our supplementary video and website at https://robotic-tool-design.github.io/ for visualizations.
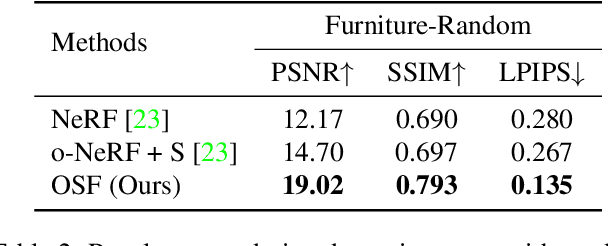
Learning Object-Centric Neural Scattering Functions for Free-viewpoint Relighting and Scene Composition
Mar 10, 2023



Photorealistic object appearance modeling from 2D images is a constant topic in vision and graphics. While neural implicit methods (such as Neural Radiance Fields) have shown high-fidelity view synthesis results, they cannot relight the captured objects. More recent neural inverse rendering approaches have enabled object relighting, but they represent surface properties as simple BRDFs, and therefore cannot handle translucent objects. We propose Object-Centric Neural Scattering Functions (OSFs) for learning to reconstruct object appearance from only images. OSFs not only support free-viewpoint object relighting, but also can model both opaque and translucent objects. While accurately modeling subsurface light transport for translucent objects can be highly complex and even intractable for neural methods, OSFs learn to approximate the radiance transfer from a distant light to an outgoing direction at any spatial location. This approximation avoids explicitly modeling complex subsurface scattering, making learning a neural implicit model tractable. Experiments on real and synthetic data show that OSFs accurately reconstruct appearances for both opaque and translucent objects, allowing faithful free-viewpoint relighting as well as scene composition.
Differentiable Physics Simulation of Dynamics-Augmented Neural Objects
Oct 20, 2022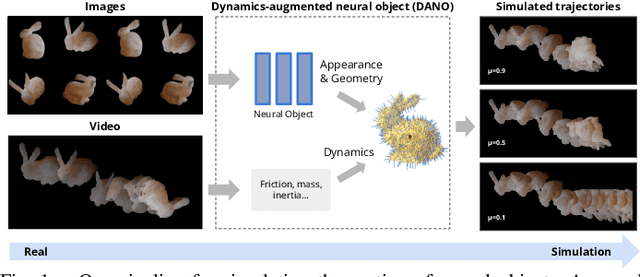

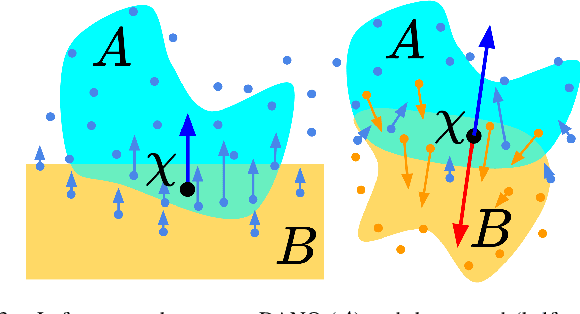
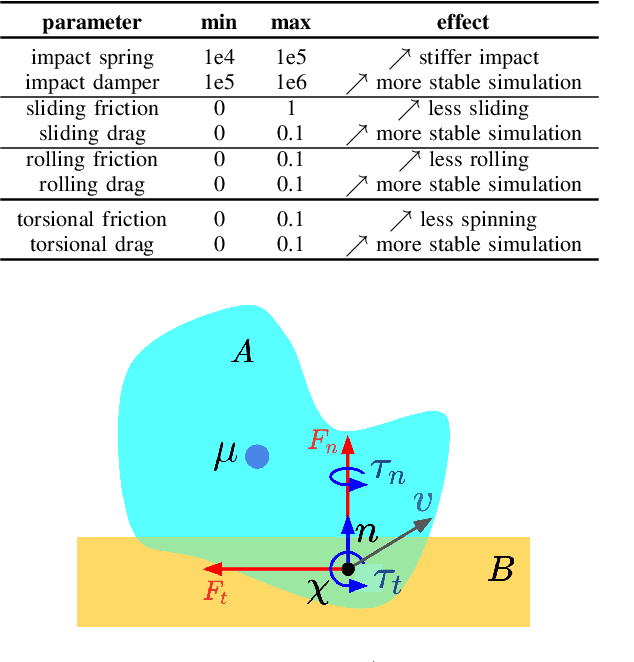
We present a differentiable pipeline for simulating the motion of objects that represent their geometry as a continuous density field parameterized as a deep network. This includes Neural Radiance Fields (NeRFs), and other related models. From the density field, we estimate the dynamical properties of the object, including its mass, center of mass, and inertia matrix. We then introduce a differentiable contact model based on the density field for computing normal and friction forces resulting from collisions. This allows a robot to autonomously build object models that are visually and dynamically accurate from still images and videos of objects in motion. The resulting Dynamics-Augmented Neural Objects (DANOs) are simulated with an existing differentiable simulation engine, Dojo, interacting with other standard simulation objects, such as spheres, planes, and robots specified as URDFs. A robot can use this simulation to optimize grasps and manipulation trajectories of neural objects, or to improve the neural object models through gradient-based real-to-simulation transfer. We demonstrate the pipeline to learn the coefficient of friction of a bar of soap from a real video of the soap sliding on a table. We also learn the coefficient of friction and mass of a Stanford bunny through interactions with a Panda robot arm from synthetic data, and we optimize trajectories in simulation for the Panda arm to push the bunny to a goal location.
Learning Diverse and Physically Feasible Dexterous Grasps with Generative Model and Bilevel Optimization
Jul 01, 2022
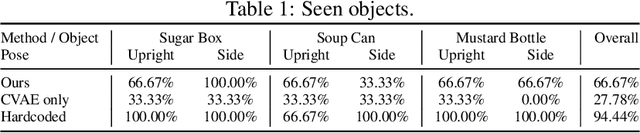
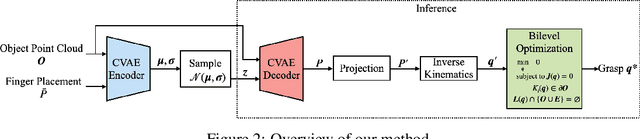
To fully utilize the versatility of a multi-finger dexterous robotic hand for object grasping, one must satisfy complex physical constraints introduced by hand-object interaction and object geometry during grasp planning. We propose an integrative approach of combining a generative model and a bilevel optimization to compute diverse grasps for novel unseen objects. First, a grasp prediction is obtained from a conditional variational autoencoder trained on merely six YCB objects. The prediction is then projected onto the manifold of kinematically and dynamically feasible grasps by jointly solving collision-aware inverse kinematics, force closure, and friction constraints as one nonconvex bilevel optimization. We demonstrate the effectiveness of our method on hardware by successfully grasping a wide range of unseen household objects, including adversarial shapes challenging to other types of robotic grippers. A video summary of our results is available at https://youtu.be/9DTrImbN99I.
DASH: Modularized Human Manipulation Simulation with Vision and Language for Embodied AI
Aug 28, 2021
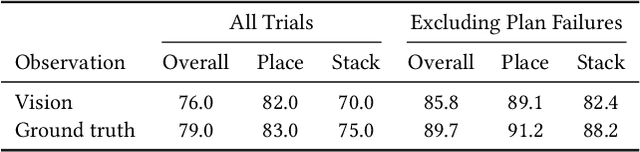

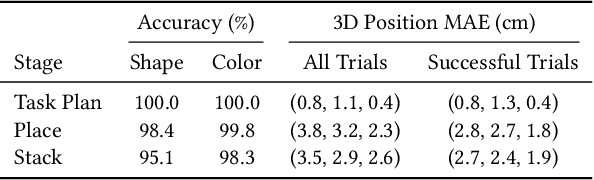
Creating virtual humans with embodied, human-like perceptual and actuation constraints has the promise to provide an integrated simulation platform for many scientific and engineering applications. We present Dynamic and Autonomous Simulated Human (DASH), an embodied virtual human that, given natural language commands, performs grasp-and-stack tasks in a physically-simulated cluttered environment solely using its own visual perception, proprioception, and touch, without requiring human motion data. By factoring the DASH system into a vision module, a language module, and manipulation modules of two skill categories, we can mix and match analytical and machine learning techniques for different modules so that DASH is able to not only perform randomly arranged tasks with a high success rate, but also do so under anthropomorphic constraints and with fluid and diverse motions. The modular design also favors analysis and extensibility to more complex manipulation skills.
* SCA'2021
Object-Centric Neural Scene Rendering
Dec 15, 2020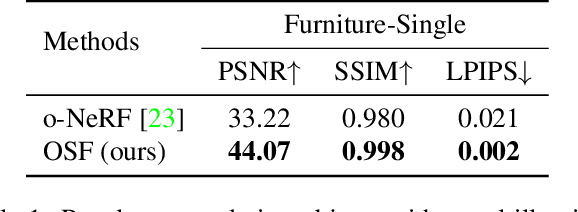

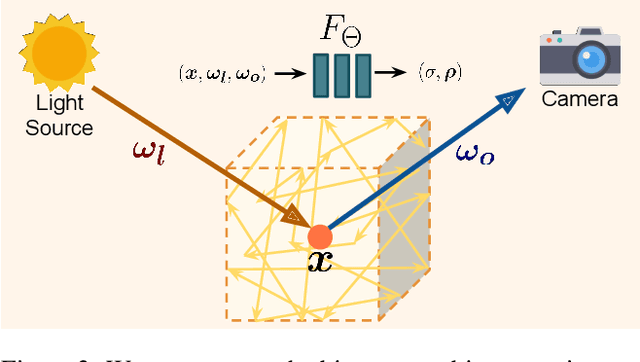
We present a method for composing photorealistic scenes from captured images of objects. Our work builds upon neural radiance fields (NeRFs), which implicitly model the volumetric density and directionally-emitted radiance of a scene. While NeRFs synthesize realistic pictures, they only model static scenes and are closely tied to specific imaging conditions. This property makes NeRFs hard to generalize to new scenarios, including new lighting or new arrangements of objects. Instead of learning a scene radiance field as a NeRF does, we propose to learn object-centric neural scattering functions (OSFs), a representation that models per-object light transport implicitly using a lighting- and view-dependent neural network. This enables rendering scenes even when objects or lights move, without retraining. Combined with a volumetric path tracing procedure, our framework is capable of rendering both intra- and inter-object light transport effects including occlusions, specularities, shadows, and indirect illumination. We evaluate our approach on scene composition and show that it generalizes to novel illumination conditions, producing photorealistic, physically accurate renderings of multi-object scenes.
End-to-End Spoken Language Translation
Apr 23, 2019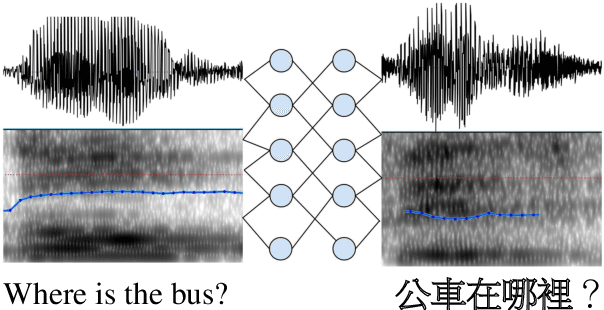
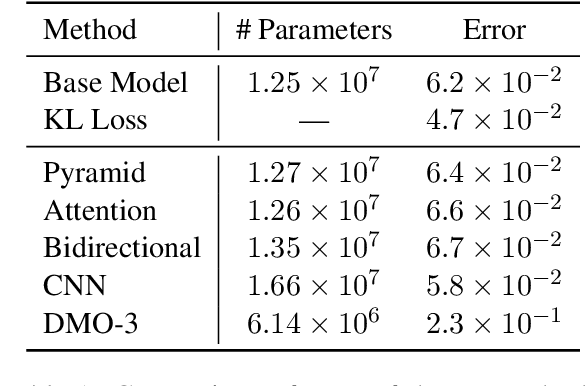
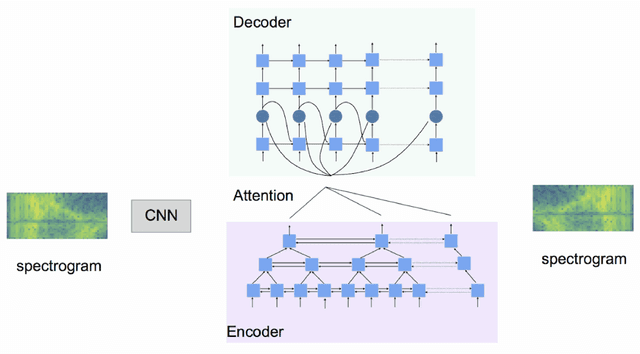
In this paper, we address the task of spoken language understanding. We present a method for translating spoken sentences from one language into spoken sentences in another language. Given spectrogram-spectrogram pairs, our model can be trained completely from scratch to translate unseen sentences. Our method consists of a pyramidal-bidirectional recurrent network combined with a convolutional network to output sentence-level spectrograms in the target language. Empirically, our model achieves competitive performance with state-of-the-art methods on multiple languages and can generalize to unseen speakers.
Audio-Linguistic Embeddings for Spoken Sentences
Feb 20, 2019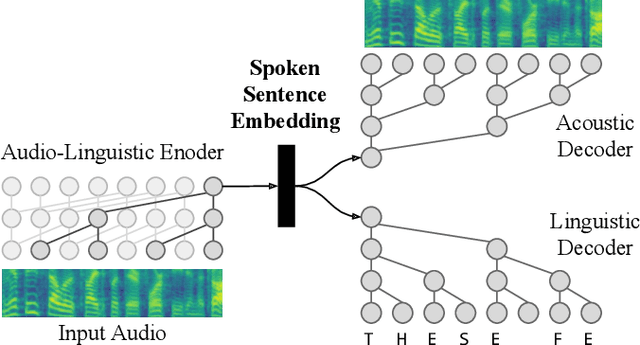
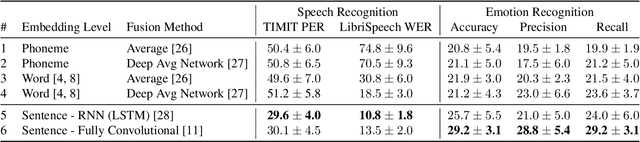
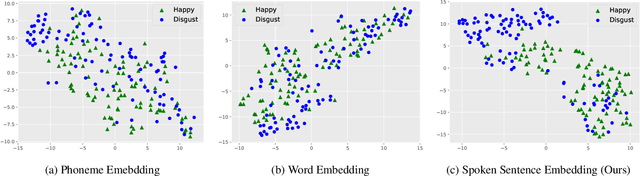
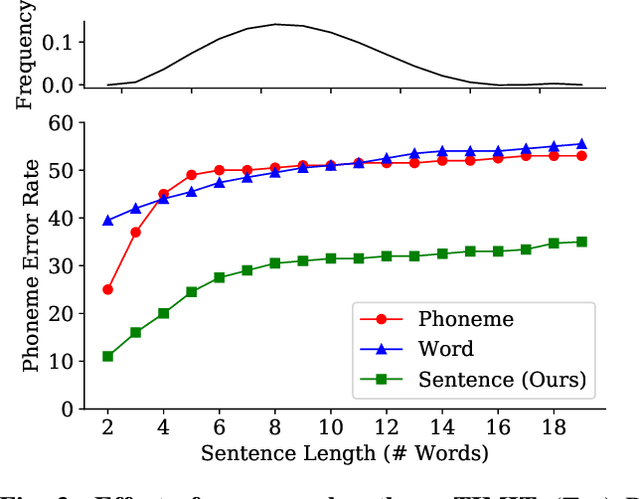
We propose spoken sentence embeddings which capture both acoustic and linguistic content. While existing works operate at the character, phoneme, or word level, our method learns long-term dependencies by modeling speech at the sentence level. Formulated as an audio-linguistic multitask learning problem, our encoder-decoder model simultaneously reconstructs acoustic and natural language features from audio. Our results show that spoken sentence embeddings outperform phoneme and word-level baselines on speech recognition and emotion recognition tasks. Ablation studies show that our embeddings can better model high-level acoustic concepts while retaining linguistic content. Overall, our work illustrates the viability of generic, multi-modal sentence embeddings for spoken language understanding.
Measuring Depression Symptom Severity from Spoken Language and 3D Facial Expressions
Nov 27, 2018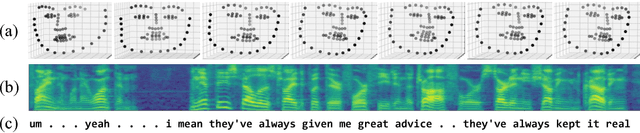
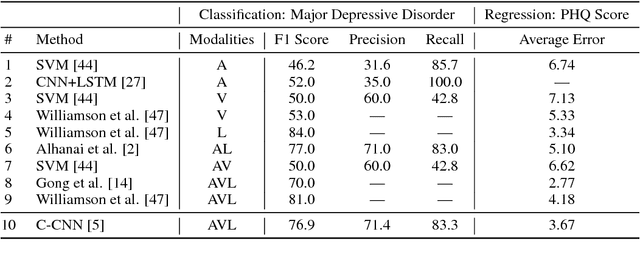
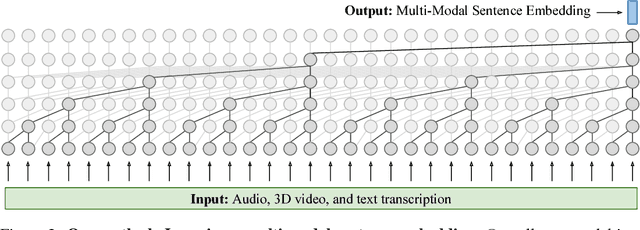
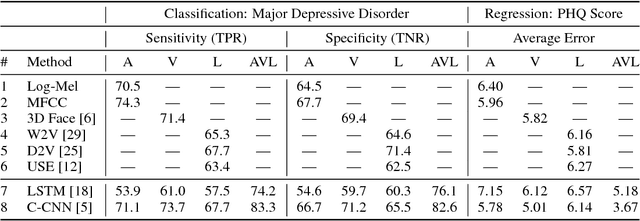
With more than 300 million people depressed worldwide, depression is a global problem. Due to access barriers such as social stigma, cost, and treatment availability, 60% of mentally-ill adults do not receive any mental health services. Effective and efficient diagnosis relies on detecting clinical symptoms of depression. Automatic detection of depressive symptoms would potentially improve diagnostic accuracy and availability, leading to faster intervention. In this work, we present a machine learning method for measuring the severity of depressive symptoms. Our multi-modal method uses 3D facial expressions and spoken language, commonly available from modern cell phones. It demonstrates an average error of 3.67 points (15.3% relative) on the clinically-validated Patient Health Questionnaire (PHQ) scale. For detecting major depressive disorder, our model demonstrates 83.3% sensitivity and 82.6% specificity. Overall, this paper shows how speech recognition, computer vision, and natural language processing can be combined to assist mental health patients and practitioners. This technology could be deployed to cell phones worldwide and facilitate low-cost universal access to mental health care.