 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimodo: Scaling Controllable Human Motion Generation
Mar 16, 2026High-quality human motion data is becoming increasingly important for applications in robotics, simulation, and entertainment. Recent generative models offer a potential data source, enabling human motion synthesis through intuitive inputs like text prompts or kinematic constraints on poses. However, the small scale of public mocap datasets has limited the motion quality, control accuracy, and generalization of these models. In this work, we introduce Kimodo, an expressive and controllable kinematic motion diffusion model trained on 700 hours of optical motion capture data. Our model generates high-quality motions while being easily controlled through text and a comprehensive suite of kinematic constraints including full-body keyframes, sparse joint positions/rotations, 2D waypoints, and dense 2D paths. This is enabled through a carefully designed motion representation and two-stage denoiser architecture that decomposes root and body prediction to minimize motion artifacts while allowing for flexible constraint conditioning. Experiments on the large-scale mocap dataset justify key design decisions and analyze how the scaling of dataset size and model size affect performance.
MaskedManipulator: Versatile Whole-Body Control for Loco-Manipulation
May 25, 2025Humans interact with their world while leveraging precise full-body control to achieve versatile goals. This versatility allows them to solve long-horizon, underspecified problems, such as placing a cup in a sink, by seamlessly sequencing actions like approaching the cup, grasping, transporting it, and finally placing it in the sink. Such goal-driven control can enable new procedural tools for animation systems, enabling users to define partial objectives while the system naturally ``fills in'' the intermediate motions. However, while current methods for whole-body dexterous manipulation in physics-based animation achieve success in specific interaction tasks, they typically employ control paradigms (e.g., detailed kinematic motion tracking, continuous object trajectory following, or direct VR teleoperation) that offer limited versatility for high-level goal specification across the entire coupled human-object system. To bridge this gap, we present MaskedManipulator, a unified and generative policy developed through a two-stage learning approach. First, our system trains a tracking controller to physically reconstruct complex human-object interactions from large-scale human mocap datasets. This tracking controller is then distilled into MaskedManipulator, which provides users with intuitive control over both the character's body and the manipulated object. As a result, MaskedManipulator enables users to specify complex loco-manipulation tasks through intuitive high-level objectives (e.g., target object poses, key character stances), and MaskedManipulator then synthesizes the necessary full-body actions for a physically simulated humanoid to achieve these goals, paving the way for more interactive and life-like virtual characters.
Constrained Diffusion with Trust Sampling
Nov 17, 2024



Diffusion models have demonstrated significant promise in various generative tasks; however, they often struggle to satisfy challenging constraints. Our approach addresses this limitation by rethinking training-free loss-guided diffusion from an optimization perspective. We formulate a series of constrained optimizations throughout the inference process of a diffusion model. In each optimization, we allow the sample to take multiple steps along the gradient of the proxy constraint function until we can no longer trust the proxy, according to the variance at each diffusion level. Additionally, we estimate the state manifold of diffusion model to allow for early termination when the sample starts to wander away from the state manifold at each diffusion step. Trust sampling effectively balances between following the unconditional diffusion model and adhering to the loss guidance, enabling more flexible and accurate constrained generation. We demonstrate the efficacy of our method through extensive experiments on complex tasks, and in drastically different domains of images and 3D motion generation, showing significant improvements over existing methods in terms of generation quality. Our implementation is available at https://github.com/will-s-h/trust-sampling.
Contrastive Augmentation: An Unsupervised Learning Approach for Keyword Spotting in Speech Technology
Aug 31, 2024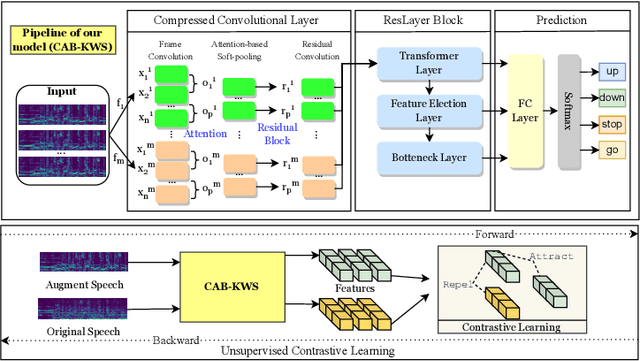


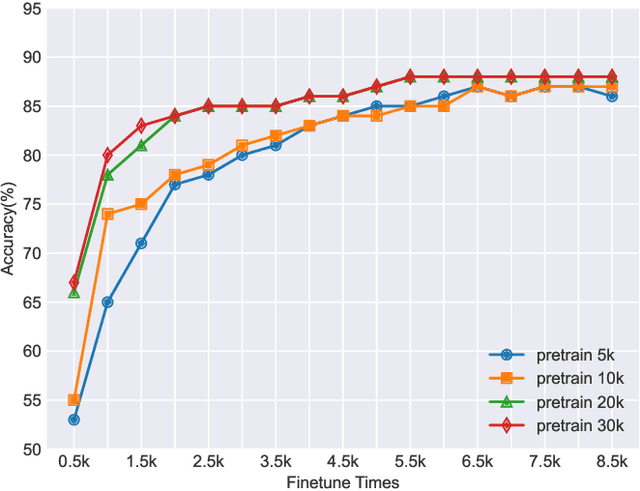
This paper addresses the persistent challenge in Keyword Spotting (KWS), a fundamental component in speech technology, regarding the acquisition of substantial labeled data for training. Given the difficulty in obtaining large quantities of positive samples and the laborious process of collecting new target samples when the keyword changes, we introduce a novel approach combining unsupervised contrastive learning and a unique augmentation-based technique. Our method allows the neural network to train on unlabeled data sets, potentially improving performance in downstream tasks with limited labeled data sets. We also propose that similar high-level feature representations should be employed for speech utterances with the same keyword despite variations in speed or volume. To achieve this, we present a speech augmentation-based unsupervised learning method that utilizes the similarity between the bottleneck layer feature and the audio reconstructing information for auxiliary training. Furthermore, we propose a compressed convolutional architecture to address potential redundancy and non-informative information in KWS tasks, enabling the model to simultaneously learn local features and focus on long-term information. This method achieves strong performance on the Google Speech Commands V2 Dataset. Inspired by recent advancements in sign spotting and spoken term detection, our method underlines the potential of our contrastive learning approach in KWS and the advantages of Query-by-Example Spoken Term Detection strategies. The presented CAB-KWS provide new perspectives in the field of KWS, demonstrating effective ways to reduce data collection efforts and increase the system's robustness.
Nymeria: A Massive Collection of Multimodal Egocentric Daily Motion in the Wild
Jun 14, 2024We introduce Nymeria - a large-scale, diverse, richly annotated human motion dataset collected in the wild with multiple multimodal egocentric devices. The dataset comes with a) full-body 3D motion ground truth; b) egocentric multimodal recordings from Project Aria devices with RGB, grayscale, eye-tracking cameras, IMUs, magnetometer, barometer, and microphones; and c) an additional "observer" device providing a third-person viewpoint. We compute world-aligned 6DoF transformations for all sensors, across devices and capture sessions. The dataset also provides 3D scene point clouds and calibrated gaze estimation. We derive a protocol to annotate hierarchical language descriptions of in-context human motion, from fine-grain pose narrations, to atomic actions and activity summarization. To the best of our knowledge, the Nymeria dataset is the world largest in-the-wild collection of human motion with natural and diverse activities; first of its kind to provide synchronized and localized multi-device multimodal egocentric data; and the world largest dataset with motion-language descriptions. It contains 1200 recordings of 300 hours of daily activities from 264 participants across 50 locations, travelling a total of 399Km. The motion-language descriptions provide 310.5K sentences in 8.64M words from a vocabulary size of 6545. To demonstrate the potential of the dataset we define key research tasks for egocentric body tracking, motion synthesis, and action recognition and evaluate several state-of-the-art baseline algorithms. Data and code will be open-sourced.
Automated Scoring of Clinical Patient Notes using Advanced NLP and Pseudo Labeling
Jan 18, 2024Clinical patient notes are critical for documenting patient interactions, diagnoses, and treatment plans in medical practice. Ensuring accurate evaluation of these notes is essential for medical education and certification. However, manual evaluation is complex and time-consuming, often resulting in variability and resource-intensive assessments. To tackle these challenges, this research introduces an approach leveraging state-of-the-art Natural Language Processing (NLP) techniques, specifically Masked Language Modeling (MLM) pretraining, and pseudo labeling. Our methodology enhances efficiency and effectiveness, significantly reducing training time without compromising performance. Experimental results showcase improved model performance, indicating a potential transformation in clinical note assessment.
An Integrative Paradigm for Enhanced Stroke Prediction: Synergizing XGBoost and xDeepFM Algorithms
Oct 25, 2023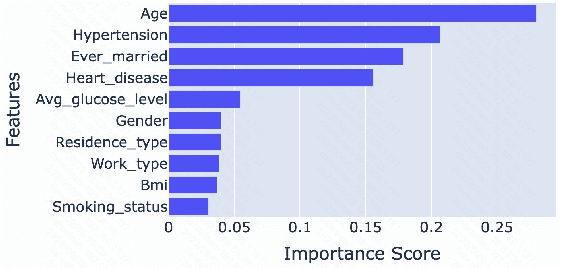
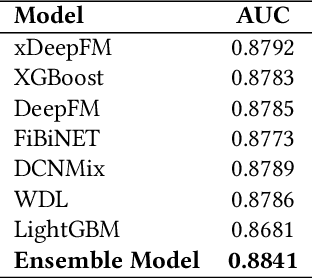
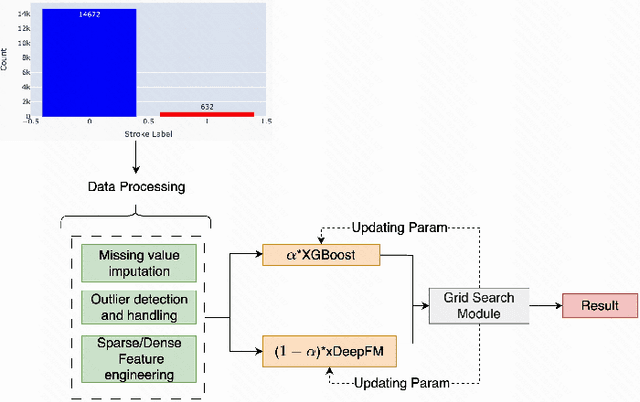
Stroke prediction plays a crucial role in preventing and managing this debilitating condition. In this study, we address the challenge of stroke prediction using a comprehensive dataset, and propose an ensemble model that combines the power of XGBoost and xDeepFM algorithms. Our work aims to improve upon existing stroke prediction models by achieving higher accuracy and robustness. Through rigorous experimentation, we validate the effectiveness of our ensemble model using the AUC metric. Through comparing our findings with those of other models in the field, we gain valuable insights into the merits and drawbacks of various approaches. This, in turn, contributes significantly to the progress of machine learning and deep learning techniques specifically in the domain of stroke prediction.
DROP: Dynamics Responses from Human Motion Prior and Projective Dynamics
Sep 24, 2023Synthesizing realistic human movements, dynamically responsive to the environment, is a long-standing objective in character animation, with applications in computer vision, sports, and healthcare, for motion prediction and data augmentation. Recent kinematics-based generative motion models offer impressive scalability in modeling extensive motion data, albeit without an interface to reason about and interact with physics. While simulator-in-the-loop learning approaches enable highly physically realistic behaviors, the challenges in training often affect scalability and adoption. We introduce DROP, a novel framework for modeling Dynamics Responses of humans using generative mOtion prior and Projective dynamics. DROP can be viewed as a highly stable, minimalist physics-based human simulator that interfaces with a kinematics-based generative motion prior. Utilizing projective dynamics, DROP allows flexible and simple integration of the learned motion prior as one of the projective energies, seamlessly incorporating control provided by the motion prior with Newtonian dynamics. Serving as a model-agnostic plug-in, DROP enables us to fully leverage recent advances in generative motion models for physics-based motion synthesis. We conduct extensive evaluations of our model across different motion tasks and various physical perturbations, demonstrating the scalability and diversity of responses.
Grasping Core Rules of Time Series through Pure Models
Aug 15, 2022Time series underwent the transition from statistics to deep learning, as did many other machine learning fields. Although it appears that the accuracy has been increasing as the model is updated in a number of publicly available datasets, it typically only increases the scale by several times in exchange for a slight difference in accuracy. Through this experiment, we point out a different line of thinking, time series, especially long-term forecasting, may differ from other fields. It is not necessary to use extensive and complex models to grasp all aspects of time series, but to use pure models to grasp the core rules of time series changes. With this simple but effective idea, we created PureTS, a network with three pure linear layers that achieved state-of-the-art in 80% of the long sequence prediction tasks while being nearly the lightest model and having the fastest running speed. On this basis, we discuss the potential of pure linear layers in both phenomena and essence. The ability to understand the core law contributes to the high precision of long-distance prediction, and reasonable fluctuation prevents it from distorting the curve in multi-step prediction like mainstream deep learning models, which is summarized as a pure linear neural network that avoids over-fluctuating. Finally, we suggest the fundamental design standards for lightweight long-step time series tasks: input and output should try to have the same dimension, and the structure avoids fragmentation and complex operations.
Transformer Inertial Poser: Attention-based Real-time Human Motion Reconstruction from Sparse IMUs
Mar 29, 2022
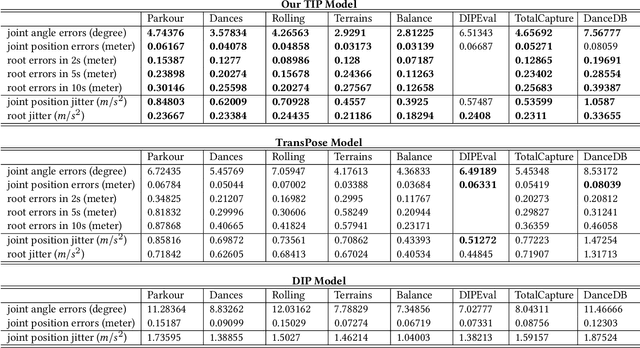
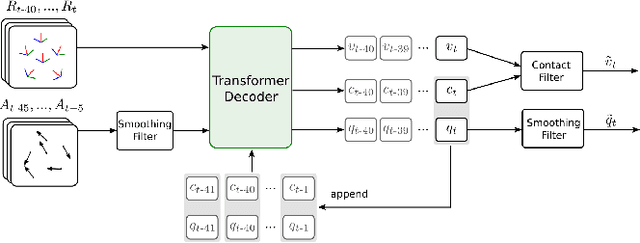
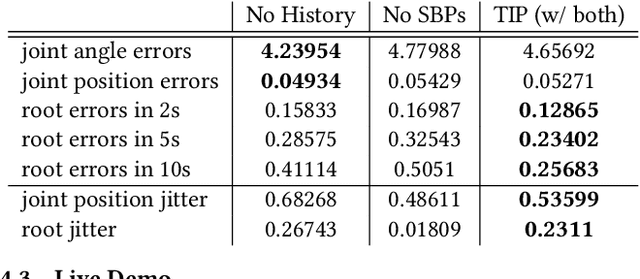
Real-time human motion reconstruction from a sparse set of wearable IMUs provides an non-intrusive and economic approach to motion capture. Without the ability to acquire absolute position information using IMUs, many prior works took data-driven approaches that utilize large human motion datasets to tackle the under-determined nature of the problem. Still, challenges such as temporal consistency, global translation estimation, and diverse coverage of motion or terrain types remain. Inspired by recent success of Transformer models in sequence modeling, we propose an attention-based deep learning method to reconstruct full-body motion from six IMU sensors in real-time. Together with a physics-based learning objective to predict "stationary body points", our method achieves new state-of-the-art results both quantitatively and qualitatively, while being simple to implement and smaller in size. We evaluate our method extensively on synthesized and real IMU data, and with real-time live demos.