 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Augmentation: An Unsupervised Learning Approach for Keyword Spotting in Speech Technology
Aug 31, 2024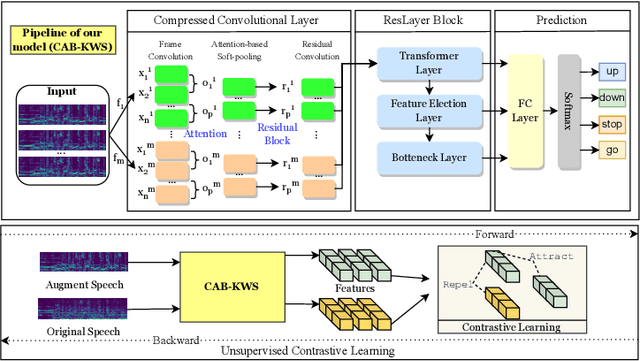


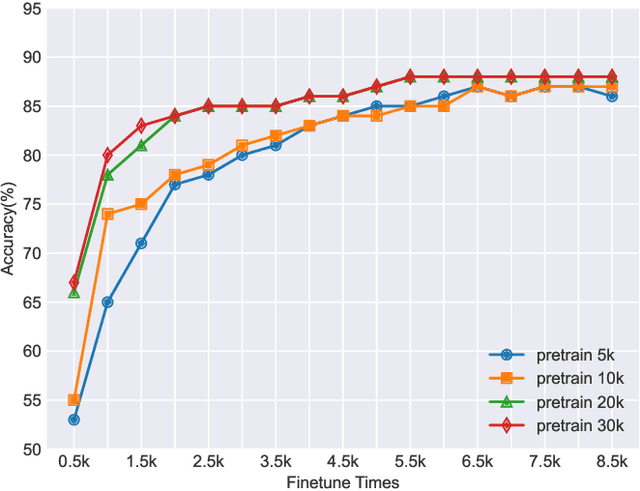
This paper addresses the persistent challenge in Keyword Spotting (KWS), a fundamental component in speech technology, regarding the acquisition of substantial labeled data for training. Given the difficulty in obtaining large quantities of positive samples and the laborious process of collecting new target samples when the keyword changes, we introduce a novel approach combining unsupervised contrastive learning and a unique augmentation-based technique. Our method allows the neural network to train on unlabeled data sets, potentially improving performance in downstream tasks with limited labeled data sets. We also propose that similar high-level feature representations should be employed for speech utterances with the same keyword despite variations in speed or volume. To achieve this, we present a speech augmentation-based unsupervised learning method that utilizes the similarity between the bottleneck layer feature and the audio reconstructing information for auxiliary training. Furthermore, we propose a compressed convolutional architecture to address potential redundancy and non-informative information in KWS tasks, enabling the model to simultaneously learn local features and focus on long-term information. This method achieves strong performance on the Google Speech Commands V2 Dataset. Inspired by recent advancements in sign spotting and spoken term detection, our method underlines the potential of our contrastive learning approach in KWS and the advantages of Query-by-Example Spoken Term Detection strategies. The presented CAB-KWS provide new perspectives in the field of KWS, demonstrating effective ways to reduce data collection efforts and increase the system's robustness.