 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"I May Not Have Articulated Myself Clearly": Diagnosing Dynamic Instability in LLM Reasoning at Inference Time
Feb 02, 2026Reasoning failures in large language models (LLMs) are typically measured only at the end of a generation, yet many failures manifest as a process-level breakdown: the model "loses the thread" mid-reasoning. We study whether such breakdowns are detectable from inference-time observables available in standard APIs (token log probabilities), without any training or fine-tuning. We define a simple instability signal that combines consecutive-step distributional shift (JSD) and uncertainty (entropy), summarize each trace by its peak instability strength, and show that this signal reliably predicts failure. Across GSM8K and HotpotQA, instability strength predicts wrong answers with above-chance AUC and yields monotonic bucket-level accuracy decline at scale across model sizes. Crucially, we show that instability is not uniformly harmful: early instability can reflect subsequent stabilization and a correct final answer (\emph{corrective instability}), whereas late instability is more often followed by failure (\emph{destructive instability}), even at comparable peak magnitudes, indicating that recoverability depends not only on how strongly the distribution changes but also on when such changes occur relative to the remaining decoding horizon. The method is model-agnostic, training-free, and reproducible, and is presented as a diagnostic lens rather than a corrective or control mechanism.
Addressing Correlated Latent Exogenous Variables in Debiased Recommender Systems
Jun 09, 2025Recommendation systems (RS) aim to provide personalized content, but they face a challenge in unbiased learning due to selection bias, where users only interact with items they prefer. This bias leads to a distorted representation of user preferences, which hinders the accuracy and fairness of recommendations. To address the issue, various methods such as error imputation based, inverse propensity scoring, and doubly robust techniques have been developed. Despite the progress, from the structural causal model perspective, previous debiasing methods in RS assume the independence of the exogenous variables. In this paper, we release this assumption and propose a learning algorithm based on likelihood maximization to learn a prediction model. We first discuss the correlation and difference between unmeasured confounding and our scenario, then we propose a unified method that effectively handles latent exogenous variables. Specifically, our method models the data generation process with latent exogenous variables under mild normality assumptions. We then develop a Monte Carlo algorithm to numerically estimate the likelihood function. Extensive experiments on synthetic datasets and three real-world datasets demonstrate the effectiveness of our proposed method. The code is at https://github.com/WallaceSUI/kdd25-background-variable.
Contrastive Augmentation: An Unsupervised Learning Approach for Keyword Spotting in Speech Technology
Aug 31, 2024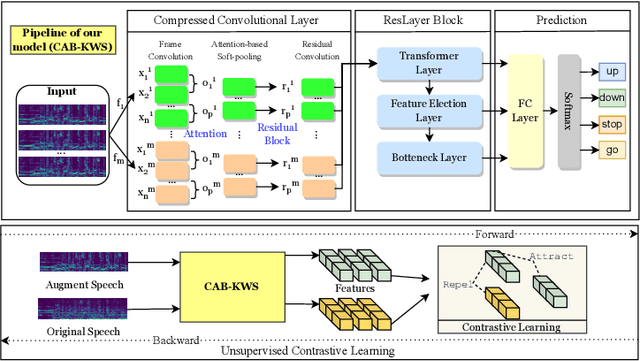


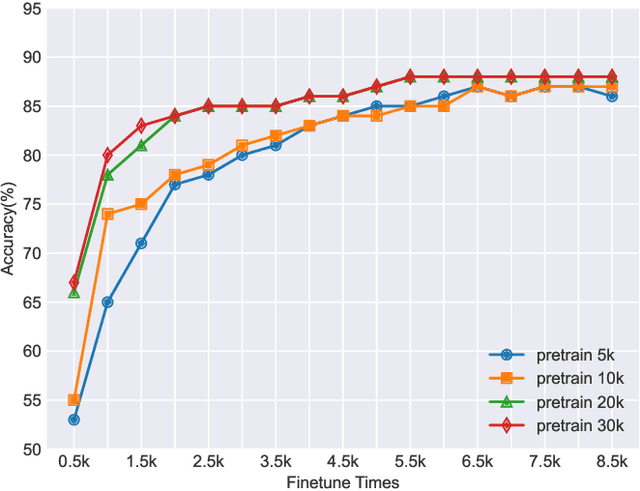
This paper addresses the persistent challenge in Keyword Spotting (KWS), a fundamental component in speech technology, regarding the acquisition of substantial labeled data for training. Given the difficulty in obtaining large quantities of positive samples and the laborious process of collecting new target samples when the keyword changes, we introduce a novel approach combining unsupervised contrastive learning and a unique augmentation-based technique. Our method allows the neural network to train on unlabeled data sets, potentially improving performance in downstream tasks with limited labeled data sets. We also propose that similar high-level feature representations should be employed for speech utterances with the same keyword despite variations in speed or volume. To achieve this, we present a speech augmentation-based unsupervised learning method that utilizes the similarity between the bottleneck layer feature and the audio reconstructing information for auxiliary training. Furthermore, we propose a compressed convolutional architecture to address potential redundancy and non-informative information in KWS tasks, enabling the model to simultaneously learn local features and focus on long-term information. This method achieves strong performance on the Google Speech Commands V2 Dataset. Inspired by recent advancements in sign spotting and spoken term detection, our method underlines the potential of our contrastive learning approach in KWS and the advantages of Query-by-Example Spoken Term Detection strategies. The presented CAB-KWS provide new perspectives in the field of KWS, demonstrating effective ways to reduce data collection efforts and increase the system's robustness.
Long-form evaluation of model editing
Feb 14, 2024
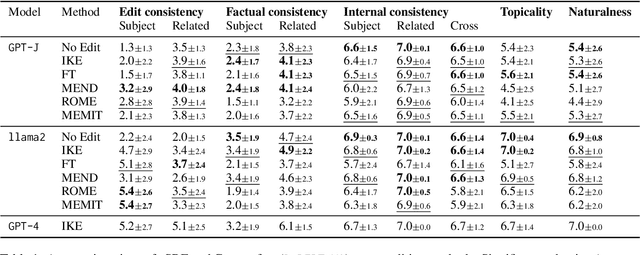

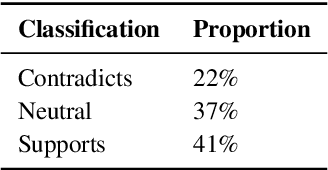
Evaluations of model editing currently only use the `next few token' completions after a prompt. As a result, the impact of these methods on longer natural language generation is largely unknown. We introduce long-form evaluation of model editing (\textbf{\textit{LEME}}) a novel evaluation protocol that measures the efficacy and impact of model editing in long-form generative settings. Our protocol consists of a machine-rated survey and a classifier which correlates well with human ratings. Importantly, we find that our protocol has very little relationship with previous short-form metrics (despite being designed to extend efficacy, generalization, locality, and portability into a long-form setting), indicating that our method introduces a novel set of dimensions for understanding model editing methods. Using this protocol, we benchmark a number of model editing techniques and present several findings including that, while some methods (ROME and MEMIT) perform well in making consistent edits within a limited scope, they suffer much more from factual drift than other methods. Finally, we present a qualitative analysis that illustrates common failure modes in long-form generative settings including internal consistency, lexical cohesion, and locality issues.
HMM-Free Encoder Pre-Training for Streaming RNN Transducer
Apr 02, 2021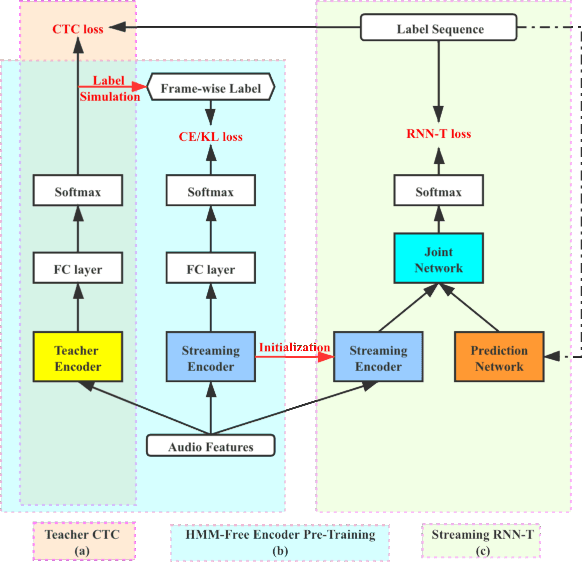
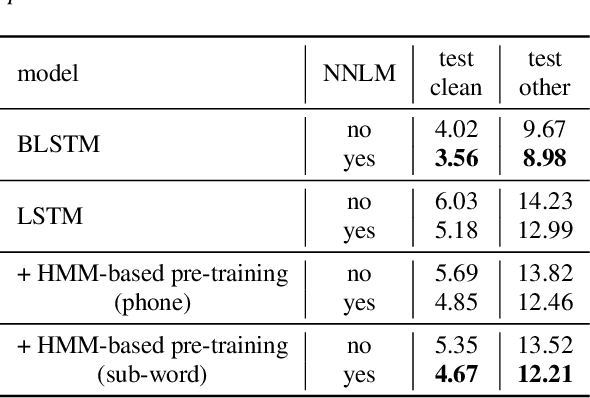
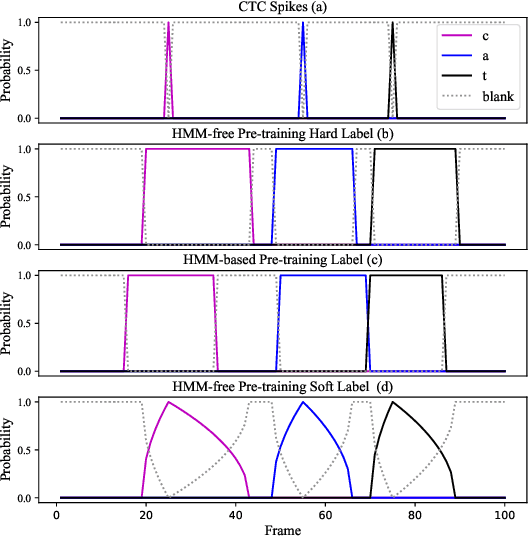
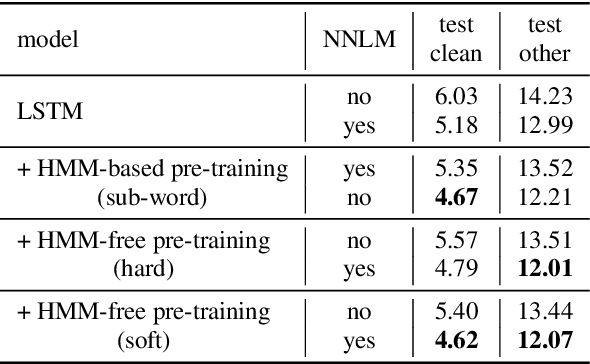
This work describes an encoder pre-training procedure using frame-wise label to improve the training of streaming recurrent neural network transducer (RNN-T) model. Streaming RNN-T trained from scratch usually performs worse and has high latency. Although it is common to address these issues through pre-training components of RNN-T with other criteria or frame-wise alignment guidance, the alignment is not easily available in end-to-end manner. In this work, frame-wise alignment, used to pre-train streaming RNN-T's encoder, is generated without using a HMM-based system. Therefore an all-neural framework equipping HMM-free encoder pre-training is constructed. This is achieved by expanding the spikes of CTC model to their left/right blank frames, and two expanding strategies are proposed. To our best knowledge, this is the first work to simulate HMM-based frame-wise label using CTC model. Experiments conducted on LibriSpeech and MLS English tasks show the proposed pre-training procedure, compared with random initialization, reduces the WER by relatively 5%~11% and the emission latency by 60 ms. Besides, the method is lexicon-free, so it is friendly to new languages without manually designed lexicon.
End-to-end Language Identification using NetFV and NetVLAD
Sep 09, 2018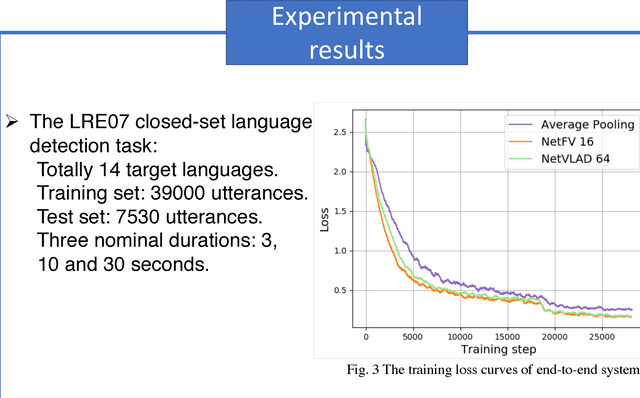
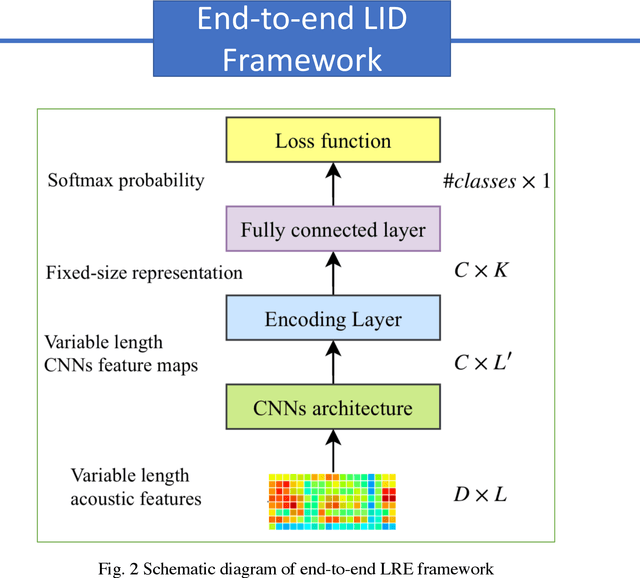
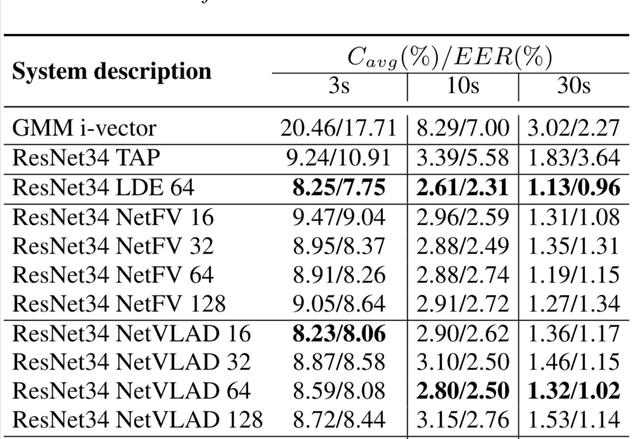
In this paper, we apply the NetFV and NetVLAD layers for the end-to-end language identification task. NetFV and NetVLAD layers are the differentiable implementations of the standard Fisher Vector and Vector of Locally Aggregated Descriptors (VLAD) methods, respectively. Both of them can encode a sequence of feature vectors into a fixed dimensional vector which is very important to process those variable-length utterances. We first present the relevances and differences between the classical i-vector and the aforementioned encoding schemes. Then, we construct a flexible end-to-end framework including a convolutional neural network (CNN) architecture and an encoding layer (NetFV or NetVLAD) for the language identification task. Experimental results on the NIST LRE 2007 close-set task show that the proposed system achieves significant EER reductions against the conventional i-vector baseline and the CNN temporal average pooling system, respectively.
Exploring the Encoding Layer and Loss Function in End-to-End Speaker and Language Recognition System
Apr 14, 2018


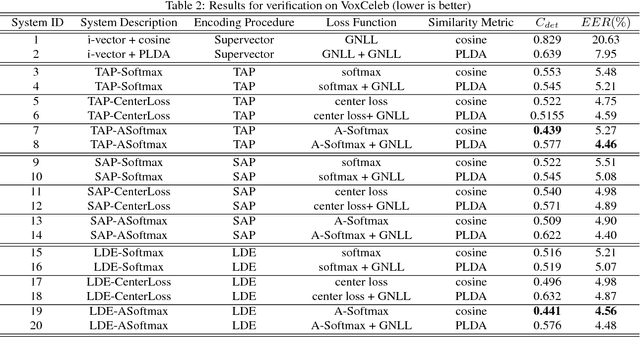
In this paper, we explore the encoding/pooling layer and loss function in the end-to-end speaker and language recognition system. First, a unified and interpretable end-to-end system for both speaker and language recognition is developed. It accepts variable-length input and produces an utterance level result. In the end-to-end system, the encoding layer plays a role in aggregating the variable-length input sequence into an utterance level representation. Besides the basic temporal average pooling, we introduce a self-attentive pooling layer and a learnable dictionary encoding layer to get the utterance level representation. In terms of loss function for open-set speaker verification, to get more discriminative speaker embedding, center loss and angular softmax loss is introduced in the end-to-end system. Experimental results on Voxceleb and NIST LRE 07 datasets show that the performance of end-to-end learning system could be significantly improved by the proposed encoding layer and loss function.