 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC Blank Triggered Dynamic Layer-Skipping for Efficient CTC-based Speech Recognition
Jan 04, 2024Deploying end-to-end speech recognition models with limited computing resources remains challenging, despite their impressive performance. Given the gradual increase in model size and the wide range of model applications, selectively executing model components for different inputs to improve the inference efficiency is of great interest. In this paper, we propose a dynamic layer-skipping method that leverages the CTC blank output from intermediate layers to trigger the skipping of the last few encoder layers for frames with high blank probabilities. Furthermore, we factorize the CTC output distribution and perform knowledge distillation on intermediate layers to reduce computation and improve recognition accuracy. Experimental results show that by utilizing the CTC blank, the encoder layer depth can be adjusted dynamically, resulting in 29% acceleration of the CTC model inference with minor performance degradation.
HMM-Free Encoder Pre-Training for Streaming RNN Transducer
Apr 02, 2021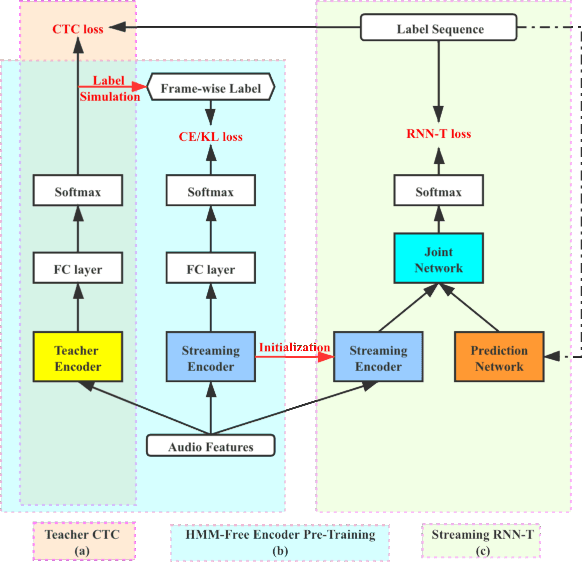
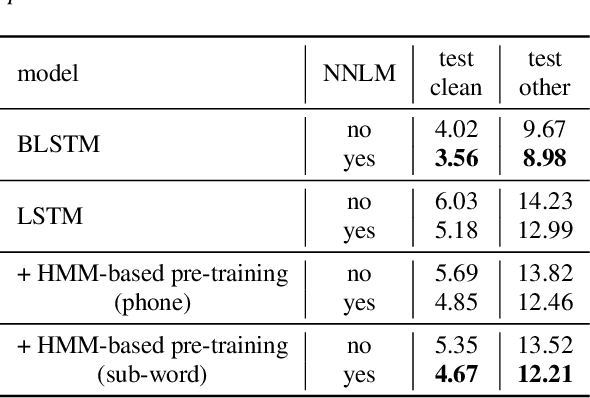
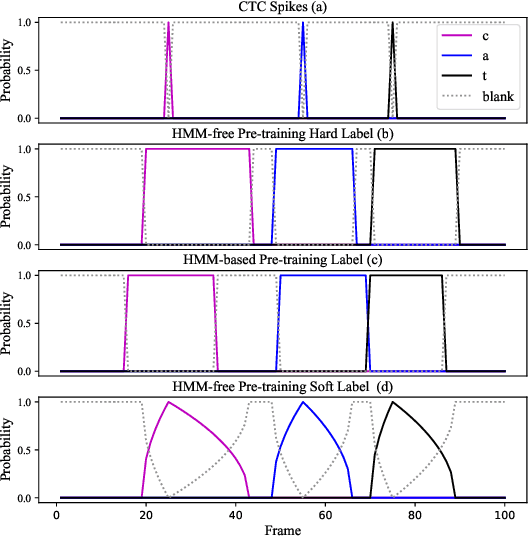
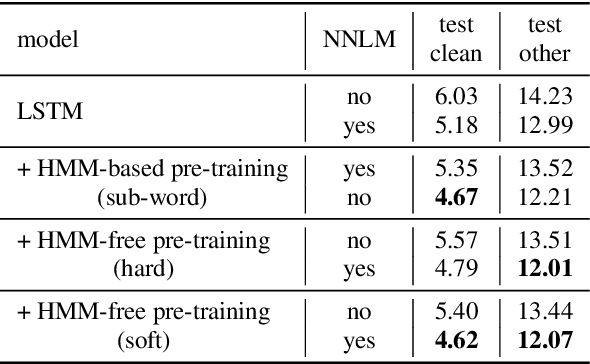
This work describes an encoder pre-training procedure using frame-wise label to improve the training of streaming recurrent neural network transducer (RNN-T) model. Streaming RNN-T trained from scratch usually performs worse and has high latency. Although it is common to address these issues through pre-training components of RNN-T with other criteria or frame-wise alignment guidance, the alignment is not easily available in end-to-end manner. In this work, frame-wise alignment, used to pre-train streaming RNN-T's encoder, is generated without using a HMM-based system. Therefore an all-neural framework equipping HMM-free encoder pre-training is constructed. This is achieved by expanding the spikes of CTC model to their left/right blank frames, and two expanding strategies are proposed. To our best knowledge, this is the first work to simulate HMM-based frame-wise label using CTC model. Experiments conducted on LibriSpeech and MLS English tasks show the proposed pre-training procedure, compared with random initialization, reduces the WER by relatively 5%~11% and the emission latency by 60 ms. Besides, the method is lexicon-free, so it is friendly to new languages without manually designed lexicon.
Attentive Fusion Enhanced Audio-Visual Encoding for Transformer Based Robust Speech Recognition
Aug 06, 2020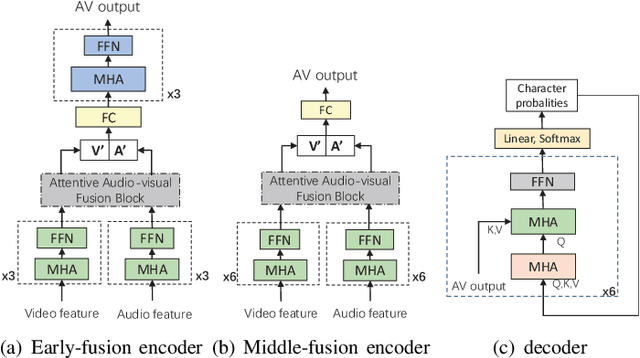


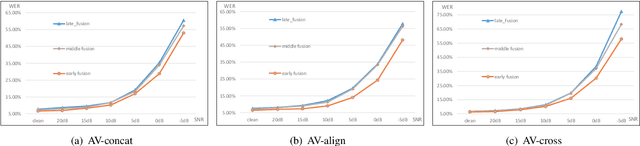
Audio-visual information fusion enables a performance improvement in speech recognition performed in complex acoustic scenarios, e.g., noisy environments. It is required to explore an effective audio-visual fusion strategy for audiovisual alignment and modality reliability. Different from the previous end-to-end approaches where the audio-visual fusion is performed after encoding each modality, in this paper we propose to integrate an attentive fusion block into the encoding process. It is shown that the proposed audio-visual fusion method in the encoder module can enrich audio-visual representations, as the relevance between the two modalities is leveraged. In line with the transformer-based architecture, we implement the embedded fusion block using a multi-head attention based audiovisual fusion with one-way or two-way interactions. The proposed method can sufficiently combine the two streams and weaken the over-reliance on the audio modality. Experiments on the LRS3-TED dataset demonstrate that the proposed method can increase the recognition rate by 0.55%, 4.51% and 4.61% on average under the clean, seen and unseen noise conditions, respectively, compared to the state-of-the-art approach.
A Fixed-Size Encoding Method for Variable-Length Sequences with its Application to Neural Network Language Models
Jun 16, 2015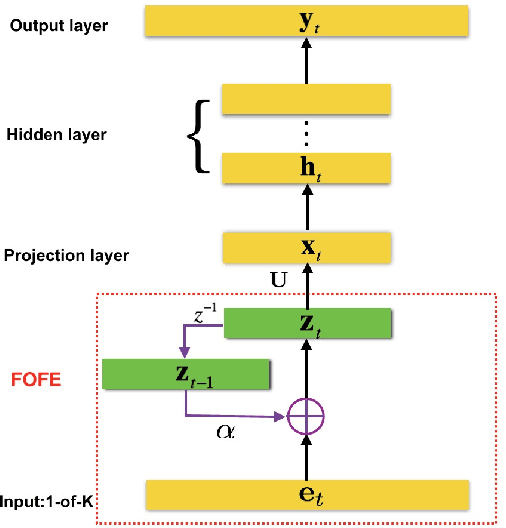
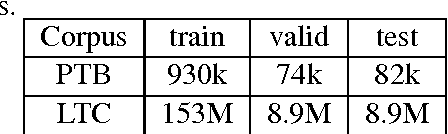

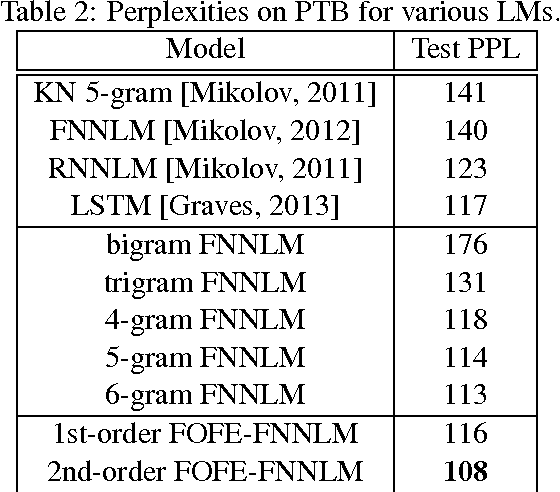
In this paper, we propose the new fixed-size ordinally-forgetting encoding (FOFE) method, which can almost uniquely encode any variable-length sequence of words into a fixed-size representation. FOFE can model the word order in a sequence using a simple ordinally-forgetting mechanism according to the positions of words. In this work, we have applied FOFE to feedforward neural network language models (FNN-LMs). Experimental results have shown that without using any recurrent feedbacks, FOFE based FNN-LMs can significantly outperform not only the standard fixed-input FNN-LMs but also the popular RNN-LMs.