 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Fine-grained Temporal Perception: Post-Training Large Audio-Language Models with Audio-Side Time Prompt
Apr 15, 2026Large Audio-Language Models (LALMs) enable general audio understanding and demonstrate remarkable performance across various audio tasks. However, these models still face challenges in temporal perception (e.g., inferring event onset and offset), leading to limited utility in fine-grained scenarios. To address this issue, we propose Audio-Side Time Prompt and leverage Reinforcement Learning (RL) to develop the TimePro-RL framework for fine-grained temporal perception. Specifically, we encode timestamps as embeddings and interleave them within the audio feature sequence as temporal coordinates to prompt the model. Furthermore, we introduce RL following Supervised Fine-Tuning (SFT) to directly optimize temporal alignment performance. Experiments demonstrate that TimePro-RL achieves significant performance gains across a range of audio temporal tasks, such as audio grounding, sound event detection, and dense audio captioning, validating its robust effectiveness.
MoEGCL: Mixture of Ego-Graphs Contrastive Representation Learning for Multi-View Clustering
Nov 08, 2025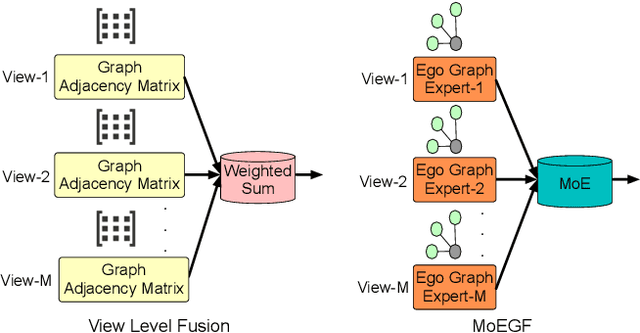
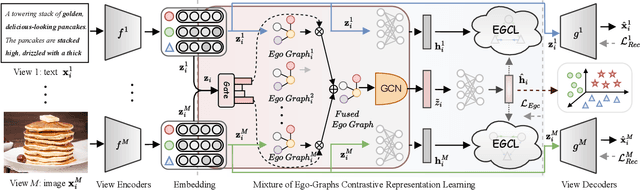
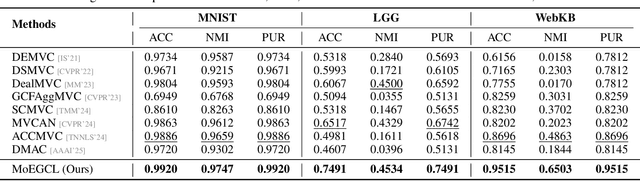
In recent years, the advancement of Graph Neural Networks (GNNs) has significantly propelled progress in Multi-View Clustering (MVC). However, existing methods face the problem of coarse-grained graph fusion. Specifically, current approaches typically generate a separate graph structure for each view and then perform weighted fusion of graph structures at the view level, which is a relatively rough strategy. To address this limitation, we present a novel Mixture of Ego-Graphs Contrastive Representation Learning (MoEGCL). It mainly consists of two modules. In particular, we propose an innovative Mixture of Ego-Graphs Fusion (MoEGF), which constructs ego graphs and utilizes a Mixture-of-Experts network to implement fine-grained fusion of ego graphs at the sample level, rather than the conventional view-level fusion. Additionally, we present the Ego Graph Contrastive Learning (EGCL) module to align the fused representation with the view-specific representation. The EGCL module enhances the representation similarity of samples from the same cluster, not merely from the same sample, further boosting fine-grained graph representation. Extensive experiments demonstrate that MoEGCL achieves state-of-the-art results in deep multi-view clustering tasks. The source code is publicly available at https://github.com/HackerHyper/MoEGCL.
CSSinger: End-to-End Chunkwise Streaming Singing Voice Synthesis System Based on Conditional Variational Autoencoder
Dec 12, 2024



Singing Voice Synthesis (SVS) {aims} to generate singing voices {of high} fidelity and expressiveness. {Conventional SVS systems usually utilize} an acoustic model to transform a music score into acoustic features, {followed by a vocoder to reconstruct the} singing voice. It was recently shown that end-to-end modeling is effective in the fields of SVS and Text to Speech (TTS). In this work, we thus present a fully end-to-end SVS method together with a chunkwise streaming inference to address the latency issue for practical usages. Note that this is the first attempt to fully implement end-to-end streaming audio synthesis using latent representations in VAE. We have made specific improvements to enhance the performance of streaming SVS using latent representations. Experimental results demonstrate that the proposed method achieves synthesized audio with high expressiveness and pitch accuracy in both streaming SVS and TTS tasks.
SiFiSinger: A High-Fidelity End-to-End Singing Voice Synthesizer based on Source-filter Model
Oct 16, 2024



This paper presents an advanced end-to-end singing voice synthesis (SVS) system based on the source-filter mechanism that directly translates lyrical and melodic cues into expressive and high-fidelity human-like singing. Similarly to VISinger 2, the proposed system also utilizes training paradigms evolved from VITS and incorporates elements like the fundamental pitch (F0) predictor and waveform generation decoder. To address the issue that the coupling of mel-spectrogram features with F0 information may introduce errors during F0 prediction, we consider two strategies. Firstly, we leverage mel-cepstrum (mcep) features to decouple the intertwined mel-spectrogram and F0 characteristics. Secondly, inspired by the neural source-filter models, we introduce source excitation signals as the representation of F0 in the SVS system, aiming to capture pitch nuances more accurately. Meanwhile, differentiable mcep and F0 losses are employed as the waveform decoder supervision to fortify the prediction accuracy of speech envelope and pitch in the generated speech. Experiments on the Opencpop dataset demonstrate efficacy of the proposed model in synthesis quality and intonation accuracy.
Deep CLAS: Deep Contextual Listen, Attend and Spell
Sep 26, 2024



Contextual-LAS (CLAS) has been shown effective in improving Automatic Speech Recognition (ASR) of rare words. It relies on phrase-level contextual modeling and attention-based relevance scoring without explicit contextual constraint which lead to insufficient use of contextual information. In this work, we propose deep CLAS to use contextual information better. We introduce bias loss forcing model to focus on contextual information. The query of bias attention is also enriched to improve the accuracy of the bias attention score. To get fine-grained contextual information, we replace phrase-level encoding with character-level encoding and encode contextual information with conformer rather than LSTM. Moreover, we directly use the bias attention score to correct the output probability distribution of the model. Experiments using the public AISHELL-1 and AISHELL-NER. On AISHELL-1, compared to CLAS baselines, deep CLAS obtains a 65.78% relative recall and a 53.49% relative F1-score increase in the named entity recognition scene.
LCM-SVC: Latent Diffusion Model Based Singing Voice Conversion with Inference Acceleration via Latent Consistency Distillation
Aug 22, 2024Any-to-any singing voice conversion (SVC) aims to transfer a target singer's timbre to other songs using a short voice sample. However many diffusion model based any-to-any SVC methods, which have achieved impressive results, usually suffered from low efficiency caused by a mass of inference steps. In this paper, we propose LCM-SVC, a latent consistency distillation (LCD) based latent diffusion model (LDM) to accelerate inference speed. We achieved one-step or few-step inference while maintaining the high performance by distilling a pre-trained LDM based SVC model, which had the advantages of timbre decoupling and sound quality. Experimental results show that our proposed method can significantly reduce the inference time and largely preserve the sound quality and timbre similarity comparing with other state-of-the-art SVC models. Audio samples are available at https://sounddemos.github.io/lcm-svc.
LDM-SVC: Latent Diffusion Model Based Zero-Shot Any-to-Any Singing Voice Conversion with Singer Guidance
Jun 08, 2024


Any-to-any singing voice conversion (SVC) is an interesting audio editing technique, aiming to convert the singing voice of one singer into that of another, given only a few seconds of singing data. However, during the conversion process, the issue of timbre leakage is inevitable: the converted singing voice still sounds like the original singer's voice. To tackle this, we propose a latent diffusion model for SVC (LDM-SVC) in this work, which attempts to perform SVC in the latent space using an LDM. We pretrain a variational autoencoder structure using the noted open-source So-VITS-SVC project based on the VITS framework, which is then used for the LDM training. Besides, we propose a singer guidance training method based on classifier-free guidance to further suppress the timbre of the original singer. Experimental results show the superiority of the proposed method over previous works in both subjective and objective evaluations of timbre similarity.
Adversarial speech for voice privacy protection from Personalized Speech generation
Jan 22, 2024The rapid progress in personalized speech generation technology, including personalized text-to-speech (TTS) and voice conversion (VC), poses a challenge in distinguishing between generated and real speech for human listeners, resulting in an urgent demand in protecting speakers' voices from malicious misuse. In this regard, we propose a speaker protection method based on adversarial attacks. The proposed method perturbs speech signals by minimally altering the original speech while rendering downstream speech generation models unable to accurately generate the voice of the target speaker. For validation, we employ the open-source pre-trained YourTTS model for speech generation and protect the target speaker's speech in the white-box scenario. Automatic speaker verification (ASV) evaluations were carried out on the generated speech as the assessment of the voice protection capability. Our experimental results show that we successfully perturbed the speaker encoder of the YourTTS model using the gradient-based I-FGSM adversarial perturbation method. Furthermore, the adversarial perturbation is effective in preventing the YourTTS model from generating the speech of the target speaker. Audio samples can be found in https://voiceprivacy.github.io/Adeversarial-Speech-with-YourTTS.
Multichannel AV-wav2vec2: A Framework for Learning Multichannel Multi-Modal Speech Representation
Jan 07, 2024



Self-supervised speech pre-training methods have developed rapidly in recent years, which show to be very effective for many near-field single-channel speech tasks. However, far-field multichannel speech processing is suffering from the scarcity of labeled multichannel data and complex ambient noises. The efficacy of self-supervised learning for far-field multichannel and multi-modal speech processing has not been well explored. Considering that visual information helps to improve speech recognition performance in noisy scenes, in this work we propose a multichannel multi-modal speech self-supervised learning framework AV-wav2vec2, which utilizes video and multichannel audio data as inputs. First, we propose a multi-path structure to process multichannel audio streams and a visual stream in parallel, with intra- and inter-channel contrastive losses as training targets to fully exploit the spatiotemporal information in multichannel speech data. Second, based on contrastive learning, we use additional single-channel audio data, which is trained jointly to improve the performance of speech representation. Finally, we use a Chinese multichannel multi-modal dataset in real scenarios to validate the effectiveness of the proposed method on audio-visual speech recognition (AVSR), automatic speech recognition (ASR), visual speech recognition (VSR) and audio-visual speaker diarization (AVSD) tasks.
Rep2wav: Noise Robust text-to-speech Using self-supervised representations
Sep 04, 2023



Benefiting from the development of deep learning, text-to-speech (TTS) techniques using clean speech have achieved significant performance improvements. The data collected from real scenes often contains noise and generally needs to be denoised by speech enhancement models. Noise-robust TTS models are often trained using the enhanced speech, which thus suffer from speech distortion and background noise that affect the quality of the synthesized speech. Meanwhile, it was shown that self-supervised pre-trained models exhibit excellent noise robustness on many speech tasks, implying that the learned representation has a better tolerance for noise perturbations. In this work, we therefore explore pre-trained models to improve the noise robustness of TTS models. Based on HiFi-GAN, we first propose a representation-to-waveform vocoder, which aims to learn to map the representation of pre-trained models to the waveform. We then propose a text-to-representation FastSpeech2 model, which aims to learn to map text to pre-trained model representations. Experimental results on the LJSpeech and LibriTTS datasets show that our method outperforms those using speech enhancement methods in both subjective and objective metrics. Audio samples are available at: https://zqs01.github.io/rep2wav.