 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaST-VLA: Thinking in Latent Spatio-Temporal Space for Vision-Language-Action in Autonomous Driving
Mar 02, 2026While Vision-Language-Action (VLA) models have revolutionized autonomous driving by unifying perception and planning, their reliance on explicit textual Chain-of-Thought (CoT) leads to semantic-perceptual decoupling and perceptual-symbolic conflicts. Recent shifts toward latent reasoning attempt to bypass these bottlenecks by thinking in continuous hidden space. However, without explicit intermediate constraints, standard latent CoT often operates as a physics-agnostic representation. To address this, we propose the Latent Spatio-Temporal VLA (LaST-VLA), a framework shifting the reasoning paradigm from discrete symbolic processing into a physically grounded Latent Spatio-Temporal CoT. By implementing a dual-feature alignment mechanism, we distill geometric constraints from 3D foundation models and dynamic foresight from world models directly into the latent space. Coupled with a progressive SFT training strategy that transitions from feature alignment to trajectory generation, and refined via Reinforcement Learning with Group Relative Policy Optimization (GRPO) to ensure safety and rule compliance. \method~setting a new record on NAVSIM v1 (91.3 PDMS) and NAVSIM v2 (87.1 EPDMS), while excelling in spatial-temporal reasoning on SURDS and NuDynamics benchmarks.
CSSinger: End-to-End Chunkwise Streaming Singing Voice Synthesis System Based on Conditional Variational Autoencoder
Dec 12, 2024



Singing Voice Synthesis (SVS) {aims} to generate singing voices {of high} fidelity and expressiveness. {Conventional SVS systems usually utilize} an acoustic model to transform a music score into acoustic features, {followed by a vocoder to reconstruct the} singing voice. It was recently shown that end-to-end modeling is effective in the fields of SVS and Text to Speech (TTS). In this work, we thus present a fully end-to-end SVS method together with a chunkwise streaming inference to address the latency issue for practical usages. Note that this is the first attempt to fully implement end-to-end streaming audio synthesis using latent representations in VAE. We have made specific improvements to enhance the performance of streaming SVS using latent representations. Experimental results demonstrate that the proposed method achieves synthesized audio with high expressiveness and pitch accuracy in both streaming SVS and TTS tasks.
SiFiSinger: A High-Fidelity End-to-End Singing Voice Synthesizer based on Source-filter Model
Oct 16, 2024



This paper presents an advanced end-to-end singing voice synthesis (SVS) system based on the source-filter mechanism that directly translates lyrical and melodic cues into expressive and high-fidelity human-like singing. Similarly to VISinger 2, the proposed system also utilizes training paradigms evolved from VITS and incorporates elements like the fundamental pitch (F0) predictor and waveform generation decoder. To address the issue that the coupling of mel-spectrogram features with F0 information may introduce errors during F0 prediction, we consider two strategies. Firstly, we leverage mel-cepstrum (mcep) features to decouple the intertwined mel-spectrogram and F0 characteristics. Secondly, inspired by the neural source-filter models, we introduce source excitation signals as the representation of F0 in the SVS system, aiming to capture pitch nuances more accurately. Meanwhile, differentiable mcep and F0 losses are employed as the waveform decoder supervision to fortify the prediction accuracy of speech envelope and pitch in the generated speech. Experiments on the Opencpop dataset demonstrate efficacy of the proposed model in synthesis quality and intonation accuracy.
LCM-SVC: Latent Diffusion Model Based Singing Voice Conversion with Inference Acceleration via Latent Consistency Distillation
Aug 22, 2024Any-to-any singing voice conversion (SVC) aims to transfer a target singer's timbre to other songs using a short voice sample. However many diffusion model based any-to-any SVC methods, which have achieved impressive results, usually suffered from low efficiency caused by a mass of inference steps. In this paper, we propose LCM-SVC, a latent consistency distillation (LCD) based latent diffusion model (LDM) to accelerate inference speed. We achieved one-step or few-step inference while maintaining the high performance by distilling a pre-trained LDM based SVC model, which had the advantages of timbre decoupling and sound quality. Experimental results show that our proposed method can significantly reduce the inference time and largely preserve the sound quality and timbre similarity comparing with other state-of-the-art SVC models. Audio samples are available at https://sounddemos.github.io/lcm-svc.
A Two-Phase Recall-and-Select Framework for Fast Model Selection
Mar 28, 2024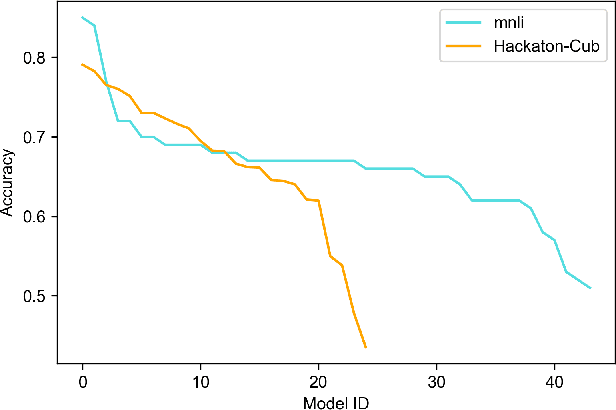
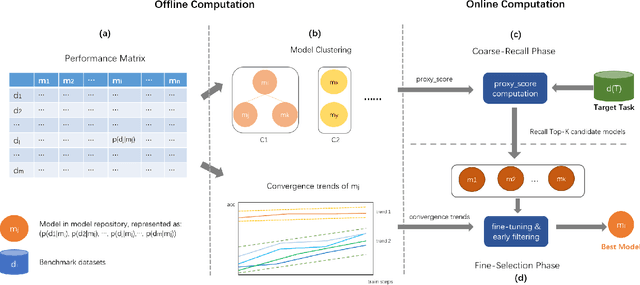
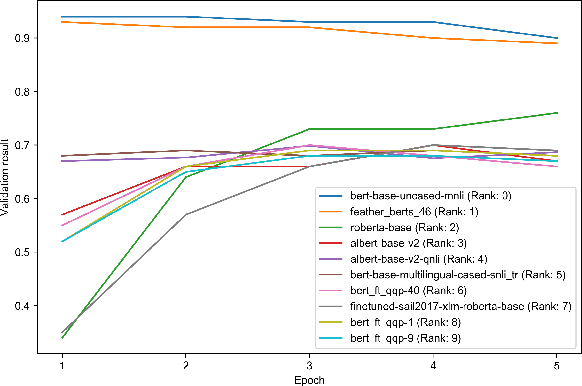

As the ubiquity of deep learning in various machine learning applications has amplified, a proliferation of neural network models has been trained and shared on public model repositories. In the context of a targeted machine learning assignment, utilizing an apt source model as a starting point typically outperforms the strategy of training from scratch, particularly with limited training data. Despite the investigation and development of numerous model selection strategies in prior work, the process remains time-consuming, especially given the ever-increasing scale of model repositories. In this paper, we propose a two-phase (coarse-recall and fine-selection) model selection framework, aiming to enhance the efficiency of selecting a robust model by leveraging the models' training performances on benchmark datasets. Specifically, the coarse-recall phase clusters models showcasing similar training performances on benchmark datasets in an offline manner. A light-weight proxy score is subsequently computed between this model cluster and the target dataset, which serves to recall a significantly smaller subset of potential candidate models in a swift manner. In the following fine-selection phase, the final model is chosen by fine-tuning the recalled models on the target dataset with successive halving. To accelerate the process, the final fine-tuning performance of each potential model is predicted by mining the model's convergence trend on the benchmark datasets, which aids in filtering lower performance models more earlier during fine-tuning. Through extensive experimentation on tasks covering natural language processing and computer vision, it has been demonstrated that the proposed methodology facilitates the selection of a high-performing model at a rate about 3x times faster than conventional baseline methods. Our code is available at https://github.com/plasware/two-phase-selection.
Learning towards Selective Data Augmentation for Dialogue Generation
Mar 17, 2023As it is cumbersome and expensive to acquire a huge amount of data for training neural dialog models, data augmentation is proposed to effectively utilize existing training samples. However, current data augmentation techniques on the dialog generation task mostly augment all cases in the training dataset without considering the intrinsic attributes between different cases. We argue that not all cases are beneficial for augmentation task, and the cases suitable for augmentation should obey the following two attributes: (1) low-quality (the dialog model cannot generate a high-quality response for the case), (2) representative (the case should represent the property of the whole dataset). Herein, we explore this idea by proposing a Selective Data Augmentation framework (SDA) for the response generation task. SDA employs a dual adversarial network to select the lowest quality and most representative data points for augmentation in one stage. Extensive experiments conducted on two publicly available datasets, i.e., DailyDialog and OpenSubtitles, show that our framework can improve the response generation performance with respect to various metrics.
MoralDial: A Framework to Train and Evaluate Moral Dialogue Systems via Constructing Moral Discussions
Dec 21, 2022



Morality in dialogue systems has raised great attention in research recently. A moral dialogue system could better connect users and enhance conversation engagement by gaining users' trust. In this paper, we propose a framework, MoralDial to train and evaluate moral dialogue systems. In our framework, we first explore the communication mechanisms of morality and resolve expressed morality into four sub-modules. The sub-modules indicate the roadmap for building a moral dialogue system. Based on that, we design a simple yet effective method: constructing moral discussions from Rules of Thumb (RoTs) between simulated specific users and the dialogue system. The constructed discussion consists of expressing, explaining, and revising the moral views in dialogue exchanges, which makes conversational models learn morality well in a natural manner. Furthermore, we propose a novel evaluation method in the framework. We evaluate the multiple aspects of morality by judging the relation between dialogue responses and RoTs in discussions, where the multifaceted nature of morality is particularly considered. Automatic and manual experiments demonstrate that our framework is promising to train and evaluate moral dialogue systems.
C3KG: A Chinese Commonsense Conversation Knowledge Graph
Apr 06, 2022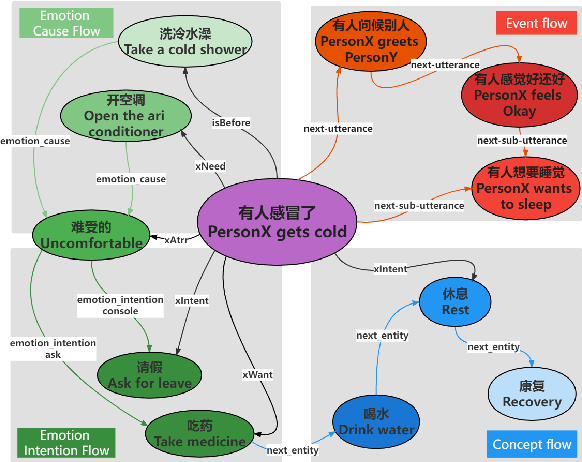

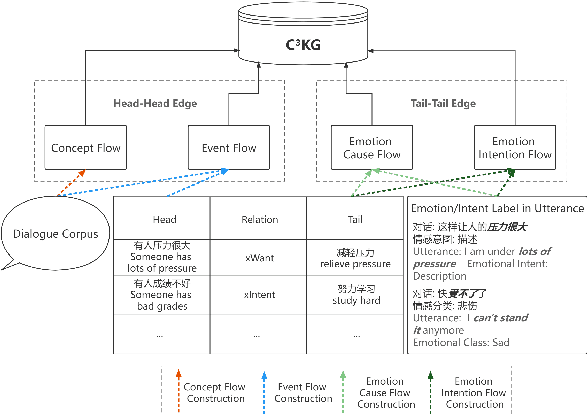

Existing commonsense knowledge bases often organize tuples in an isolated manner, which is deficient for commonsense conversational models to plan the next steps. To fill the gap, we curate a large-scale multi-turn human-written conversation corpus, and create the first Chinese commonsense conversation knowledge graph which incorporates both social commonsense knowledge and dialog flow information. To show the potential of our graph, we develop a graph-conversation matching approach, and benchmark two graph-grounded conversational tasks.
MISC: A MIxed Strategy-Aware Model Integrating COMET for Emotional Support Conversation
Mar 31, 2022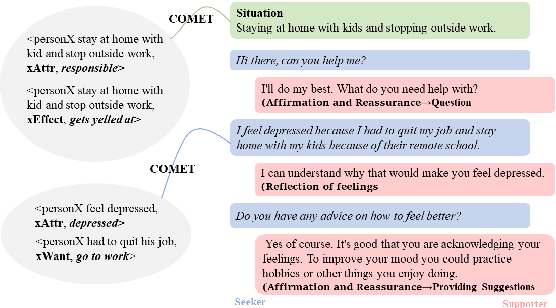

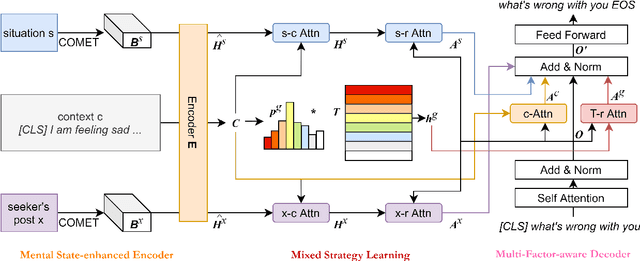
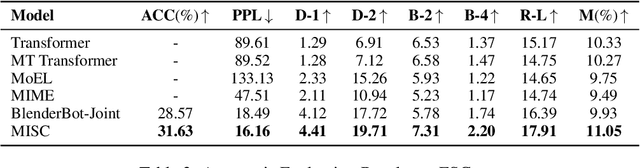
Applying existing methods to emotional support conversation -- which provides valuable assistance to people who are in need -- has two major limitations: (a) they generally employ a conversation-level emotion label, which is too coarse-grained to capture user's instant mental state; (b) most of them focus on expressing empathy in the response(s) rather than gradually reducing user's distress. To address the problems, we propose a novel model \textbf{MISC}, which firstly infers the user's fine-grained emotional status, and then responds skillfully using a mixture of strategy. Experimental results on the benchmark dataset demonstrate the effectiveness of our method and reveal the benefits of fine-grained emotion understanding as well as mixed-up strategy modeling. Our code and data could be found in \url{https://github.com/morecry/MISC}.
Multi-Scale Local-Temporal Similarity Fusion for Continuous Sign Language Recognition
Jul 27, 2021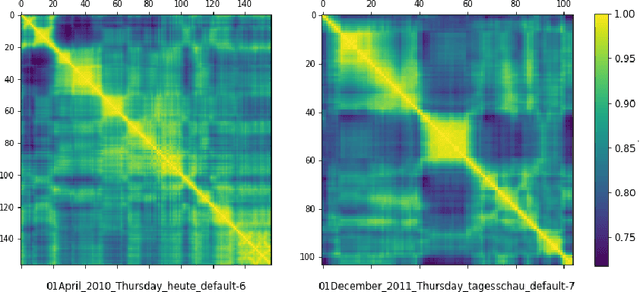

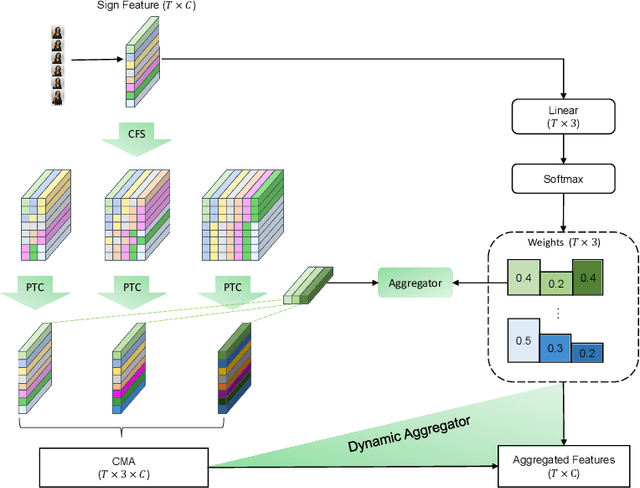

Continuous sign language recognition (cSLR) is a public significant task that transcribes a sign language video into an ordered gloss sequence. It is important to capture the fine-grained gloss-level details, since there is no explicit alignment between sign video frames and the corresponding glosses. Among the past works, one promising way is to adopt a one-dimensional convolutional network (1D-CNN) to temporally fuse the sequential frames. However, CNNs are agnostic to similarity or dissimilarity, and thus are unable to capture local consistent semantics within temporally neighboring frames. To address the issue, we propose to adaptively fuse local features via temporal similarity for this task. Specifically, we devise a Multi-scale Local-Temporal Similarity Fusion Network (mLTSF-Net) as follows: 1) In terms of a specific video frame, we firstly select its similar neighbours with multi-scale receptive regions to accommodate different lengths of glosses. 2) To ensure temporal consistency, we then use position-aware convolution to temporally convolve each scale of selected frames. 3) To obtain a local-temporally enhanced frame-wise representation, we finally fuse the results of different scales using a content-dependent aggregator. We train our model in an end-to-end fashion, and the experimental results on RWTH-PHOENIX-Weather 2014 datasets (RWTH) demonstrate that our model achieves competitive performance compared with several state-of-the-art models.