 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Two-Phase Recall-and-Select Framework for Fast Model Selection
Paper and Code
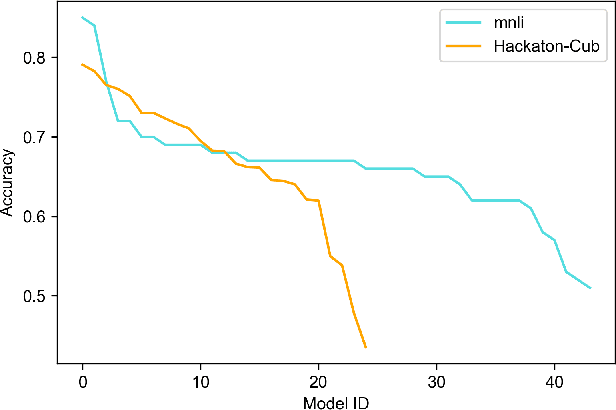
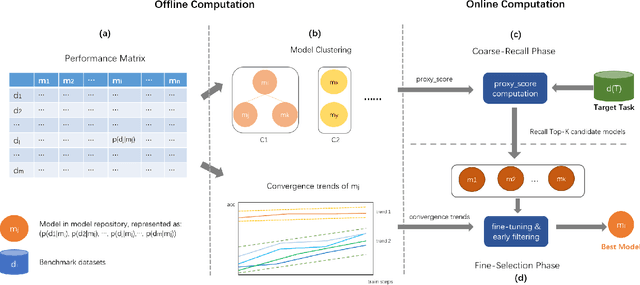
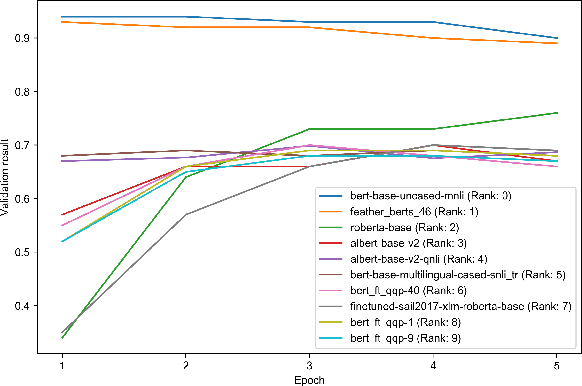

As the ubiquity of deep learning in various machine learning applications has amplified, a proliferation of neural network models has been trained and shared on public model repositories. In the context of a targeted machine learning assignment, utilizing an apt source model as a starting point typically outperforms the strategy of training from scratch, particularly with limited training data. Despite the investigation and development of numerous model selection strategies in prior work, the process remains time-consuming, especially given the ever-increasing scale of model repositories. In this paper, we propose a two-phase (coarse-recall and fine-selection) model selection framework, aiming to enhance the efficiency of selecting a robust model by leveraging the models' training performances on benchmark datasets. Specifically, the coarse-recall phase clusters models showcasing similar training performances on benchmark datasets in an offline manner. A light-weight proxy score is subsequently computed between this model cluster and the target dataset, which serves to recall a significantly smaller subset of potential candidate models in a swift manner. In the following fine-selection phase, the final model is chosen by fine-tuning the recalled models on the target dataset with successive halving. To accelerate the process, the final fine-tuning performance of each potential model is predicted by mining the model's convergence trend on the benchmark datasets, which aids in filtering lower performance models more earlier during fine-tuning. Through extensive experimentation on tasks covering natural language processing and computer vision, it has been demonstrated that the proposed methodology facilitates the selection of a high-performing model at a rate about 3x times faster than conventional baseline methods. Our code is available at https://github.com/plasware/two-phase-selection.