 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Knowledge Editing for Information Enrichment and Probability Promotion
Dec 22, 2024Knowledge stored in large language models requires timely updates to reflect the dynamic nature of real-world information. To update the knowledge, most knowledge editing methods focus on the low layers, since recent probes into the knowledge recall process reveal that the answer information is enriched in low layers. However, these probes only and could only reveal critical recall stages for the original answers, while the goal of editing is to rectify model's prediction for the target answers. This inconsistency indicates that both the probe approaches and the associated editing methods are deficient. To mitigate the inconsistency and identify critical editing regions, we propose a contrast-based probe approach, and locate two crucial stages where the model behavior diverges between the original and target answers: Information Enrichment in low layers and Probability Promotion in high layers. Building upon the insights, we develop the Joint knowledge Editing for information Enrichment and probability Promotion (JEEP) method, which jointly edits both the low and high layers to modify the two critical recall stages. Considering the mutual interference and growing forgetting due to dual modifications, JEEP is designed to ensure that updates to distinct regions share the same objectives and are complementary. We rigorously evaluate JEEP by editing up to thousands of facts on various models, i.e., GPT-J (6B) and LLaMA (7B), and addressing diverse editing objectives, i.e., adding factual and counterfactual knowledge. In all tested scenarios, JEEP achieves best performances, validating the effectiveness of the revealings of our probe approach and the designs of our editing method. Our code and data are available at https://github.com/Eric8932/JEEP.
A Two-Phase Recall-and-Select Framework for Fast Model Selection
Mar 28, 2024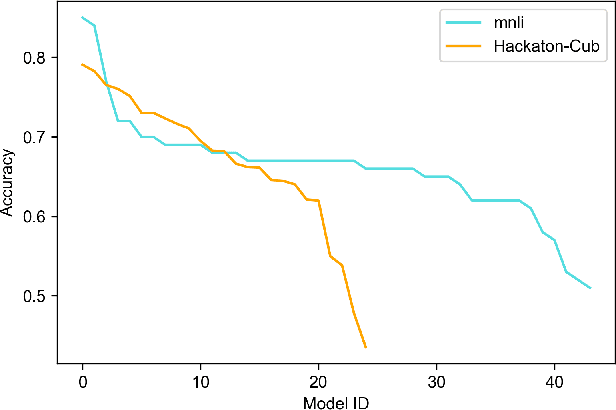
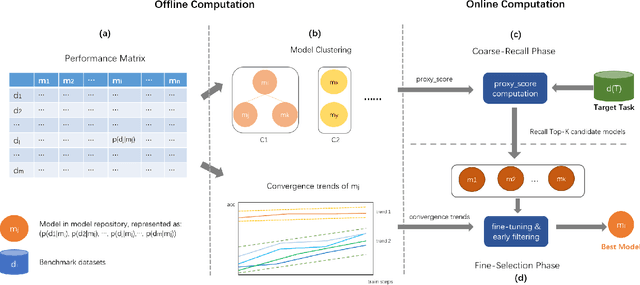
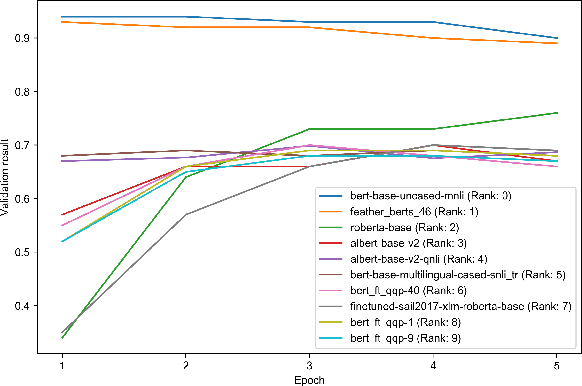

As the ubiquity of deep learning in various machine learning applications has amplified, a proliferation of neural network models has been trained and shared on public model repositories. In the context of a targeted machine learning assignment, utilizing an apt source model as a starting point typically outperforms the strategy of training from scratch, particularly with limited training data. Despite the investigation and development of numerous model selection strategies in prior work, the process remains time-consuming, especially given the ever-increasing scale of model repositories. In this paper, we propose a two-phase (coarse-recall and fine-selection) model selection framework, aiming to enhance the efficiency of selecting a robust model by leveraging the models' training performances on benchmark datasets. Specifically, the coarse-recall phase clusters models showcasing similar training performances on benchmark datasets in an offline manner. A light-weight proxy score is subsequently computed between this model cluster and the target dataset, which serves to recall a significantly smaller subset of potential candidate models in a swift manner. In the following fine-selection phase, the final model is chosen by fine-tuning the recalled models on the target dataset with successive halving. To accelerate the process, the final fine-tuning performance of each potential model is predicted by mining the model's convergence trend on the benchmark datasets, which aids in filtering lower performance models more earlier during fine-tuning. Through extensive experimentation on tasks covering natural language processing and computer vision, it has been demonstrated that the proposed methodology facilitates the selection of a high-performing model at a rate about 3x times faster than conventional baseline methods. Our code is available at https://github.com/plasware/two-phase-selection.
Create and Find Flatness: Building Flat Training Spaces in Advance for Continual Learning
Sep 20, 2023Catastrophic forgetting remains a critical challenge in the field of continual learning, where neural networks struggle to retain prior knowledge while assimilating new information. Most existing studies emphasize mitigating this issue only when encountering new tasks, overlooking the significance of the pre-task phase. Therefore, we shift the attention to the current task learning stage, presenting a novel framework, C&F (Create and Find Flatness), which builds a flat training space for each task in advance. Specifically, during the learning of the current task, our framework adaptively creates a flat region around the minimum in the loss landscape. Subsequently, it finds the parameters' importance to the current task based on their flatness degrees. When adapting the model to a new task, constraints are applied according to the flatness and a flat space is simultaneously prepared for the impending task. We theoretically demonstrate the consistency between the created and found flatness. In this manner, our framework not only accommodates ample parameter space for learning new tasks but also preserves the preceding knowledge of earlier tasks. Experimental results exhibit C&F's state-of-the-art performance as a standalone continual learning approach and its efficacy as a framework incorporating other methods. Our work is available at https://github.com/Eric8932/Create-and-Find-Flatness.
TencentPretrain: A Scalable and Flexible Toolkit for Pre-training Models of Different Modalities
Dec 13, 2022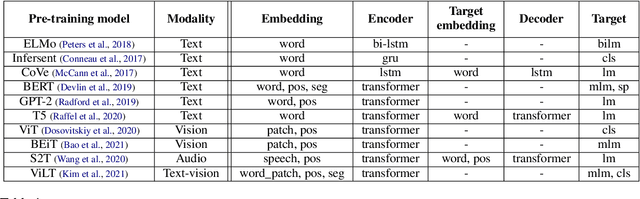
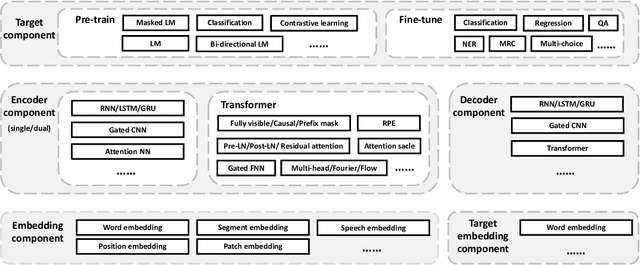
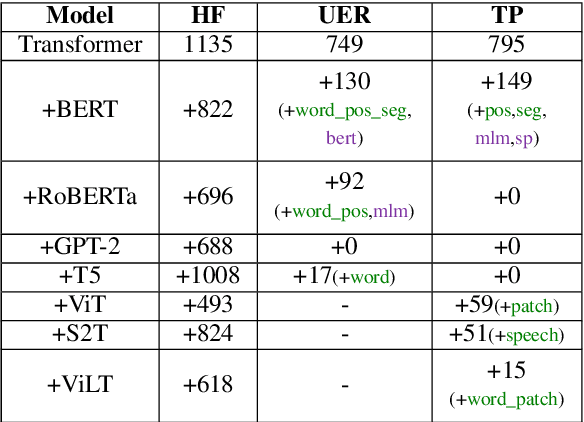
Recently, the success of pre-training in text domain has been fully extended to vision, audio, and cross-modal scenarios. The proposed pre-training models of different modalities are showing a rising trend of homogeneity in their model structures, which brings the opportunity to implement different pre-training models within a uniform framework. In this paper, we present TencentPretrain, a toolkit supporting pre-training models of different modalities. The core feature of TencentPretrain is the modular design. The toolkit uniformly divides pre-training models into 5 components: embedding, encoder, target embedding, decoder, and target. As almost all of common modules are provided in each component, users can choose the desired modules from different components to build a complete pre-training model. The modular design enables users to efficiently reproduce existing pre-training models or build brand-new one. We test the toolkit on text, vision, and audio benchmarks and show that it can match the performance of the original implementations.